Ambry: LinkedIn’s scalable geo-distributed object store Noghabi et al. SIGMOD ’16
Ambry is LinkedIn’s blob store, designed to handle the demands of a modern social network:
Hundreds of millions of users continually upload and view billions of diverse massive media objects, from photos and videos to documents. These large media objects, called blobs, are uploaded once, frequently accessed from all around the world, never modified, and rarely deleted. LinkedIn, as a global large-scale social network company, has faced the need for a geographically distributed system that stores and retrieves these read-heavy blobs in an efficient and scalable manner.
For LinkedIn, this amounts to about 800M operations/day and about 120TB data/day with a request rate that is doubling year-on-year. (See also Facebook’s f4 and Haystack). Storing blobs efficiently brings about three main challenges:
- Blobs vary significantly in size from 10s of KBs to several GBs.
- The number of blobs that need to stored and served is growing rapidly
- The variability in workload (e.g. for popular (‘hot’) blobs) can create unbalanced system load.
Ambry is thus designed to handle both large and small immutable data blobs with read-heavy (> 95%) traffic patterns. It has been in production for over 2 years across four datacenters.
Our experimental results show that Ambry reaches high throughput (reaching up to 88% of the network bandwidth) and low latency (serving 1 MB blobs in less than 50ms), works efficiently across multiple geo-distributed datacenters, and improves the imbalance among disks by a factor of 8x–10x while moving minimal data.
The overall design of Ambry should look fairly familiar. There are frontend servers that handle incoming requests (there are just three operations: put, get, and delete) and route them to backend data nodes which store the actual data. A ZooKeeper-based cluster manager looks after the state of the cluster itself.
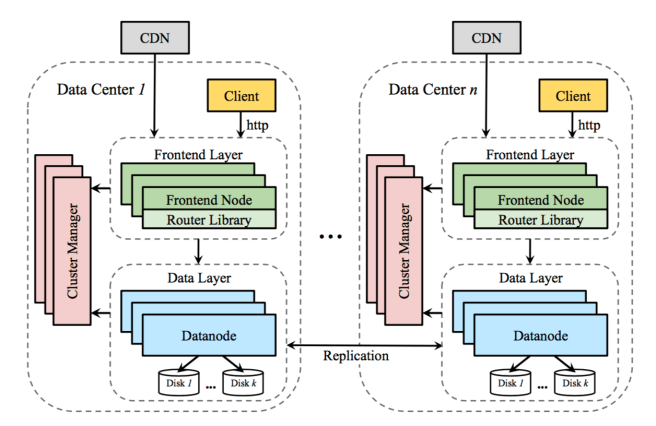
A CDN layer in front of Ambry is used to serve popular data. On the data nodes, multiple blobs are grouped together into a partition, which for high availability and fault-tolerance data is replicated on multiple data nodes. Asynchronous replication is used to keep partition replicas in sync. Each replica takes it in turn to execute the following protocol:
- Contact all the other replicas of the partition and ask for the blob ids of all blobs written since the last sync offset
- Request any blobs that the initiating replica does not have, and append them to the local partition
An in-memory journal structure is used to make finding recently written blobs efficient. Requests are batched between common partition replicas of two data nodes, and the transfer of blobs across datacenters is also batched. Lagging replicas are given dedicated threads to help them catch-up at a faster rate.
Client Operations are handled in a multi-master design where operations can be served by any of the replicas. The decision of how many replicas to contact is based on user-defined policies. These policies are similar to consistency levels in Cassandra, where they control how many (one, k, majority, all) replicas to involve in an operation. For puts (or deletes), the request is forwarded to all replicas, and policies define the number of acknowledgments needed for a success (trade-off between durability and latency). For gets, policies determine how many randomly selected replicas to contact for the operation (trade-off between resources usage and latency). In practice, we found that for all operations the k = 2 replica policy gives us the balance we desire. Stricter polices (involving more replicas) can be used to provide stronger consistency guarantees.
(See Probabilistically bounded staleness for a good overview of the considerations in setting k).
Partitioning
Instead of directly mapping blobs to physical machines, e.g., Chord and CRUSH, Ambry randomly groups blobs together into virtual units called partitions. The physical placement of partitions on machines is done in a separate procedure. This decoupling of the logical and physical placement enables transparent data movement (necessary for rebalancing) and avoids immediate rehashing of data during cluster expansion.
A partition is realised as an append-only log in a pre-allocated large file (100 GB). Blobs are sequentially written to partitions as put and delete entries. Large blobs are split into smaller equal-sized units called chunks: the sweet spot for a chunk size is around 4–8MB. A metadata blob (the blob id of which is returned to the client) is created to store the number of chunks and the chunk ids so that the large blob can later be reconstructed. When first created, partitions are read-write and can be used for all operations (put, get, and delete).
When the partition hits its upper threshold on size (capacity threshold) it becomes read-only, thereafter serving only get and delete operations. The capacity threshold should be slightly less than the max capacity (80–90%) of the partition for two reasons. First, after becoming read-only, replicas might not be completely in-sync and need free space to catch-up later (because of asynchronous writes). Second, delete requests still append delete entries.
Load balancing
Ambry uses a combination of static and dynamic load balancing.
Splitting large blobs into multiple small chunks as well as routing put operations to random partitions, achieves balance in partition sizes. Additionally, using fairly large partition sizes along with relying on CDNs to handle very popular data significantly decrease the likelihood of hot partitions. Using these techniques the load imbalance of request rates and partition sizes in production gets to as low as 5% amongst data nodes.
Every now and then Ambry rebalances the cluster. Read-write partitions become the main factor of load imbalance as they receive all write traffic, and also store the most recently written (and hence most likely the most recently shared) blobs. When the cluster is expanded (capacity demands are increasing all the time), the new data nodes will contain almost exclusively read-wire partitions for a time. This can create imbalances where new nodes are receiving up to 100x higher traffic than old nodes, and 10x higher than average-age nodes. Rebalancing spreads the read-write partitions more evenly across nodes.
The rebalancing approach reduces request rate and disk usage imbalance by 6–10x and 9–10x respectively. Ambry defines the ideal (load balanced) state as a triplet (idealRW, idealRO, idealUsed) representing the ideal number of read-write partitions, ideal number of read-only partitions and ideal disk usage each disk should have… the rebalacing algorithm attempts to reach this ideal state.
It is a two-phase algorithm. In the first phase Ambry (logically) moves partitions from disks that are above ideal into a partition pool, the partitions to move are chosen so as to minimize data movement – for read-write partitions, those with the least used capacity are chosen, but for read-only partitions it is just a random selection as all of these are full by definition. In the second phase, partitions from the pool are assigned to disks that are below ideal – first read-write partitions, and then read-only ones. “Ambry finds all disks below ideal, shuffles them, and assigns partitions to them in a round-robin fashion. This procedure is repeated until the pool becomes empty.”
After finding the the new placement, replicas are seamlessly moved by: 1) creating a new replica in the destination, 2) syncing the new replica with old ones using the replication protocol while serving new writes in all replicas, and 3) deleting the old replica after syncing.
Latency reduction
Datanodes use a variety of techniques to reduce read and write latency:
- maintaining an index of blob offsets per partition replica
- maximising the use of OS caching to serve most reads from RAM, and maintaining an in-memory Bloom filter for each disk segment to indicate which blob ids are in which segment.
- batching writes for a particular partition, with periodic flushes to disk, “the flush period is configurable and trades-off latency for durability.”
- keeping all file handles open (there are a relatively small number of large – 100 GB – files, making this possible)
- using a zero copy mechanism to move data from disk to network without going through the application layer
The future
As part of future work we plan to adaptively change the replication factor of data based on the popularity, and use erasure coding mechanisms for cold data. We also plan to investigate using compression mechanisms and its costs and benefits. Additionally, we are working on improving the security of Ambry, especially for cross-datacenter traffic.

2 thoughts on “Ambry: LinkedIn’s scalable geo-distributed object store”
Comments are closed.