Incorporating copying mechanism in sequence to sequence learning Gu et al. 2016, with a side-helping of Neural machine translation by jointly learning to align and translate Bahdanau et al. ICLR 2015
Today’s paper shows how the sequence-to-sequence conversational model we looked at yesterday can be made to seem more natural by including a “copying mechanism” that is an important part of human conversation. Consider the following examples where the blue subsequence from the input (I) is repeated in the response (R):

It’s easy for humans to do, but it turns out we require quite a lot of additional machinery over and above the base sequence-to-sequence approach in order to teach computers to do it.
We argue that it will benefit many Seq2Seq tasks to have an elegant unified model that can accommodate both understanding and rote memorization (copying). Towards this goal, we propose CopyNet, which is not only capable of the regular generation of words but also the operation of copying appropriate segments of the input sequence. Despite the seemingly “hard” operation of copying, CopyNet can be trained in an end-to-end fashion.
One of the areas where the copying mechanism seems to add a lot of value is in coping with “out of vocabulary” (OOV) words. Words not included in the vocabulary could be entity names for example, and echoing these in responses is often appropriate.
Background: adding an attention mechanism to seq2seq
CopyNet itself builds on the work of Bahdanau et al. in “Neural Machine Translation by Jointly Learning to Align and Translate.” So let’s take a brief detour to understand the basic attention mechanism idea in that paper. The setting is machine translation using sequence-to-sequence, which struggles to cope with long sentences where all of the necessary information in the source sentence needs to be compressed into a fixed-length vector. The performance of a basic encoder-decoder pair deteriorates rapidly as the length of the input sentence increases. So the trick is not to try and compress the whole sentence when looking for a translation, but instead to focus attention on different parts of the source sentence at different points in the translation.
The most important distinguishing feature of this approach from the basic encoder–decoder is that it does not attempt to encode a whole input sentence into a single fixed-length vector. Instead, it encodes the input sentence into a sequence of vectors and chooses a subset of these vectors adaptively while decoding the translation. This frees a neural translation model from having to squash all the information of a source sentence, regardless of its length, into a fixed-length vector. We show this allows a model to cope better with long sentences.
The resulting architecture uses a bi-directional RNN as an encoder (more on that shortly), and a decoder that ‘emulates searching through a source sentence during decoding a translation.’
The decoder relies on a series of context annotations, one for each word in the source sentence. Each annotation hi contains information about the whole input sequence, with a strong emphasis on the parts surrounding the ith word of the input sequence. A learned alignment model weights these annotations to score how well the inputs around position j and the outputs at position i match.
Intuitively, this implements a mechanism of attention in the decoder. The decoder decides parts of the source sentence to pay attention to. By letting the decoder have an attention mechanism, we relieve the encoder from the burden of having to encode all information in the source sentence into a fixed- length vector. With this new approach the information can be spread throughout the sequence of annotations, which can be selectively retrieved by the decoder accordingly.
In normal encoding, we just read each input symbol starting from the first symbol and proceeding to the last one. But we want the annotation for each word to summarize not only what has come before it, but what follows it. The solution is simple – encode the sequence both forwards and backwards (a bi-directional RNN) and concatenate the forward and backward state for each symbol.
CopyNet overview
CopyNet follows the general encoder-decoder pattern, and uses a bi-directional RNN to encode the source sequence. The encoded representation can be thought of as a short-term memory, M.
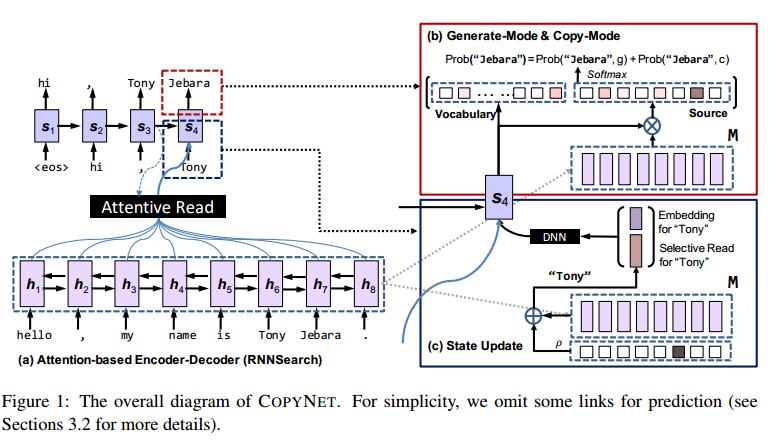
The decoder reads M and predicts the target sequence. It uses a similar attention mechanism to Bahdanau et al., with a few important differences:
- Words are predicted based on a probabilistic model combining two modes: a generate mode and a copy mode. The generate mode uses the same scoring function as a generic encoder-decoder (see e.g. Bahdanau et al.). Copy mode picks words from the source sequence using the hidden states in M to represent each word, using a non-linear activation function (tanh). The two modes are combined with a shared normalization term, and so are basically competing through a softmax function. See section 3.2 for further details, I’m not sure I can do them justice here…
- CopyNet uses both the previous state and a weighted sum of the hidden states in M in order to update each decoding state at every step. This selective read is designed for the copy mode and focuses attention on the source sequence encoded in the hidden state. A properly trained encoder will have captured both the semantics of a word and its location in the input in the hidden states in M.
We hypothesize that COPYNET uses a hybrid strategy for fetching the content in M, which combines both content-based and location-based addressing. Both addressing strategies are coordinated by the decoder RNN in managing the attentive read and selective read, as well as determining when to enter/quit the copy-mode… Unlike the explicit design for hybrid addressing in the Neural Turing Machine, COPYNET is more subtle; it provides the architecture that can facilitate some particular location-based addressing and lets the model figure out the details from the training data for specific tasks.
CopyNet experiments
The authors use CopyNet in three different tasks: a synthetic dataset to show that it can learn rules requiring copying of symbols outside of its vocabulary (it can); a text summarization task; and simple single-turn dialogues. On text summarization, CopyNet ‘beats the competitor models by a big margin.’ But it’s the dialogue performance we’re most interested in this week.
- Dialogue data is collected from Baidu Tieba with real-life conversations covering greetings and sports etc.
- Patterns are mined from the set, e.g. “Hi, my name is Adrian” followed by “Hi, Adrian” can lead to the pattern “hi, my name is X -> hi, X” simply by looking for copied subsequences.
- The dataset is enlarged by filling the slots with suitable subsequences (e.g. name entities, dates etc.).
Using this slot filling, two datasets are created based on 173 collected patterns. CopyNet is able to accurately replicate critical segments from the input using copy mode, and generates the rest of the answers smoothly using the generate mode.

(Click to enlarge).

Thank you very much for discussing the paper by Gu et al. I have always enjoyed and learnt from your blogs. In the present case, I could see the value of copying from the two examples you have given early in the blog. But, I could not quite understand Fig. 1 which has parts a, b and c and many solid and dotted arrows connecting various modules. There is the also the block named “M” in a couple of places. Can you perhaps please explain a bit more?
The best source for more details is section 3.1 in the original paper (linked at the top of the piece). That diagram certainly is complex though I agree (and this is the simplified version!).
In short, there is an RNN encoder which turns the source statement into a series of hidden states – where each hidden state corresponds to a word in the input sentence (bottom of part (a) in the figure). The collection of hidden states is collectively known as the short-term memory, ‘M’, which is then used when generating a reply and copying elements of the input into it (part (b) of the figure).
Regards, A.