A Neural Conversation Model Vinyals & Le, ICML 2015
What happens if you build a bot that is trained on conversational data, and only conversational data: no programmed understanding of the domain at all, just lots and lots of sample conversations…? Building on the sequence to sequence technique that we looked at previously, this is exactly what Vinyals & Le set out to find out.
The main advantage of this (sequence-to-sequence) framework is that it requires little feature engineering and domain specificity whilst matching or surpassing state-of-the-art-results [in tasks such as machine translation]. This advance, in our opinion, allows researchers to work on tasks for which domain knowledge may not be readily available, or for tasks which are simply too hard to design rules manually. Conversational modeling can benefit from this formulation because it requires mapping between queries and responses. Due to the complexity of this mapping, conversational modeling has previously been designed to be very narrow in domain, with a major undertaking on feature engineering.
The traditional approach to building bots requires a ‘rather complicated pipeline’ of many stages. In contrast, the neural conversational model is a end-to-end approach to the problem which lacks any domain knowledge. The surprising thing, is just how well it works. We’ll see some example conversations soon. Of course the bot has no understanding of what the conversation means. Or maybe it does have some kind of understanding (just like a word vector seems to capture some understanding of the meaning of a word), but it’s not an understanding we can tap into. Therefore you can’t use this approach to incorporate external knowledge in replies, or to extract intent and take actions etc.. Even so, a bot trained on an IT helpdesk troubleshooting dataset is able to genuinely help people.
Assuming you’re familiar with how sequence-to-sequence learning works, the whole neural conversational model can be explained in one short paragraph. During training, the conversation so far is used as the input sequence, and the next response is the target output sequence.
Concretely, suppose we observe a conversation with two turns: the first person utters “ABC”, and the second person replies “WXYZ”. We can use a recurrent neural network and train to map “ABC” to “WXYZ” as show in Figure 1 [below]. The hidden state of the model when it receives the end of sequence symbol can be viewed as the thought vector because it stores the information of the sentence, or thought, “ABC”.
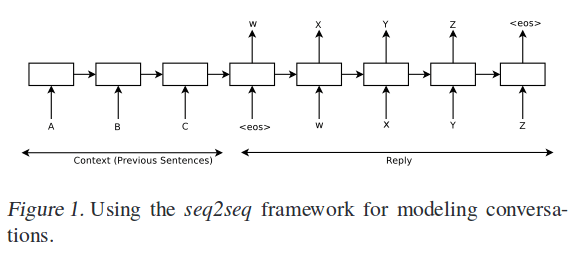
When conversing, the conversation so far is fed into the input sequence, and the bot responds with the generated output sequence.
The approach was tested with an IT helpdesk dataset (30M tokens, with typical interactions being 400 words long and turn-taking clearly signaled), and the Open Subtitles dataset of sentences uttered by characters in movies (62M training sentences, 26M validation sentences).
Training with the IT helpdesk dataset was done with a single layer LSTM with 1024 memory cells and the 20K most common words. Here’s an example conversation with the trained bot:

The OpenSubtitles experiment was performed with a two-layered LSTM with 4096 cells per layer and a 100K word vocabulary. “Our simple recurrent model does often produce plausible answers.”
We find it encouraging that the model can remember facts, understand contexts, and perform common sense reasoning without the complexity in traditional pipelines. What surprises us is that the model does so without any explicit knowledge representation component except for the parameters in the word vectors. Perhaps most practically significant is the fact that the model can generalize to new questions. In other words, it does not simply look up for an answer by matching the question with the existing database. In fact, most of the questions presented above, except for the first conversation, do not appear in the training set.
Here’s an example general knowledge Q&A – I don’t think Watson has anything to worry about just yet!

It’s interesting, but also far from something you’d want to rely on in a real chatbot service at this point in time. The model only gives simple and short answers to questions (which may be ‘probable’ answers according to the model, but aren’t always correct from our perspective).
Perhaps a more problematic drawback is that the model does not capture a consistent personality. Indeed, if we ask not identical but semantically similar questions, the answers can sometimes be inconsistent:

So there you have it:
In this paper, we show that a simple language model based on the seq2seq framework can be used to train a conversational engine. Our modest results show that it can generate simple and basic conversations, and extract knowledge from a noisy but open-domain dataset. Even though the model has obvious limitations, it is surprising to us that a purely data driven approach without any rules can produce rather proper answers to many types of questions. However, the model may require substantial modifications to be able to deliver realistic conversations.
My personal takeaway is that while it’s amazing how much can be done just with conversational data to learn from, any real service is going to need to some more complex logic wrapped around it. One possibility the authors hint at is that the neural conversational model could in principle be combined with other systems to re-score a short-list of candidate responses generated by other means.

Please provide any links to download IT HelpDesk Chat-Service dataset or any equivalent (helpdesk chat-service) dataset for final project in bachelor of technology programme.
I am looking for one too
https://github.com/rkadlec/ubuntu-ranking-dataset-creator is a good place to start… Regards, A.