Morpheus: Towards automated SLOs for enterprise clusters Jyothi et al. OSDI 2016 I'm really impressed with this paper - it covers all the bases from user studies to find out what's really important to end users, to data-driven engineering, a sprinkling of algorithms, a pragmatic implementation being made available in open source, and of course, … Continue reading Morpheus: Towards automated SLOs for enterprise clusters
Tag: Distributed Systems
Core distributed systems topics, for example consistency, availability and so on.
Kraken: Leveraging live traffic tests to identify and resolve resource utilization bottlenecks in large scale web services
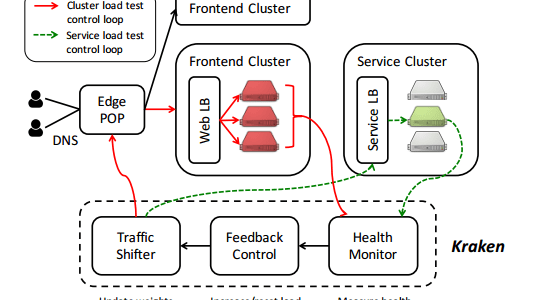
Kraken: Leveraging live traffic tests to identify and resolve resource utilization bottlenecks in large scale web services Veeraraghavan et al. (Facebook) OSDI 2016 How do you know how well your systems can perform under stress? How can you identify resource utilization bottlenecks? And how do you know your tests match the condititions experienced with live … Continue reading Kraken: Leveraging live traffic tests to identify and resolve resource utilization bottlenecks in large scale web services
The Honey Badger of BFT protocols
The Honey Badger of BFT Protocols Miller et al. CCS 2016 The surprising success of cryptocurrencies (blockchains) has led to a surge of interest in deploying large scale, highly robust, Byzantine fault tolerant (BFT) protocols for mission critical applications, such as financial transactions. In a ‘traditional’ distributed system consensus algorithm setting we assume a relatively … Continue reading The Honey Badger of BFT protocols
Simple testing can prevent most critical failures
Simple testing can prevent most critical failures: an analysis of production failures in distributed data-intensive systems Yuan et al. OSDI 2014 After yesterday's paper I needed something a little easier to digest today, and 'Simple testing can prevent most critical failures' certainly hit the spot. Thanks to Caitie McCaffrey from whom I first heard about … Continue reading Simple testing can prevent most critical failures
The load, capacity, and availability of quorum systems
The load, capacity, and availability of quorum systems Naor & Wool, SIAM J Computing 1998 Update: fixed 'non-intersection property' to read 'non-empty intersection property.' Quite an important difference! With thanks to those who pointed out my mistake. This is the paper that Howard et al referenced in Flexible Paxos as defining the “fundamental theorem of … Continue reading The load, capacity, and availability of quorum systems
Distributed consensus and the implications of NVM on database management systems
Distributed consensus and the implications of NVM on database management systems Fournier, Arulraj, & Pavlo ACM Queue Vol 14, issue 3 As you may recall, Peter Bailis and ACM Queue have started a "Research for Practice" series introducing "expert curated guides to the best of CS research." Aka, reading lists for The Morning Paper! I … Continue reading Distributed consensus and the implications of NVM on database management systems
Flexible Paxos: Quorum intersection revisited
Flexible Paxos: Quorum intersection revisited Howard et al., 2016 Paxos has been around for 18 (26) years now, and extensively studied. (For some background, see the 2 week mini-series on consensus that I put together last year). In this paper, Howard et al. make a simple(?) observation that has significant consequences for improving the fault-tolerance … Continue reading Flexible Paxos: Quorum intersection revisited
Data on the Outside versus Data on the Inside
Data on the Outside vs Data on the Inside Pat Helland, CIDR 2005 Another (modern) classic today, Pat Helland's wonderful 2005 paper on thinking about data in service oriented architectures. Sticking with the contemporary feel I'm going to write SOA as 'microservices' for the rest of this post. Helland shows us that we need to … Continue reading Data on the Outside versus Data on the Inside
On designing and deploying internet-scale services
On designing and deploying internet-scale services James Hamilton LISA '07 Want to know how to build cloud native applications? You'll be hard-pushed to find a better collection of wisdom, best practices, and hard-won experience than this 2007 paper from James Hamilton. It's amazing to think that all of this knowledge was captured and written down … Continue reading On designing and deploying internet-scale services
BigDebug: Debugging primitives for interactive big data processing in Spark
BigDebug: Debugging primitives for interactive big data processing in Spark - Gulzar et al. ICSE 2016 BigDebug provides real-time interactive debugging support for Data-Intensive Scalable Computing (DISC) systems, or more particularly, Apache Spark. It provides breakpoints, watchpoints, latency monitoring, forward and backward tracing, crash monitoring, and a real-time fix-and-resume capability. The overheads are low for … Continue reading BigDebug: Debugging primitives for interactive big data processing in Spark
