Helios: hyperscale indexing for the cloud & edge, Potharaju et al., PVLDB’20
On the surface this is a paper about fast data ingestion from high-volume streams, with indexing to support efficient querying. As a production system within Microsoft capturing around a quadrillion events and indexing 16 trillion search keys per day it would be interesting in its own right, but there’s a lot more to it than that. Helios also serves as a reference architecture for how Microsoft envisions its next generation of distributed big-data processing systems being built. These two narratives of reference architecture and ingestion/indexing system are interwoven throughout the paper. I’m going to tackle the paper in two parts, focusing today on the reference architecture, and in the next post on the details of Helios itself. What follows is a discussion of where big data systems might be heading, heavily inspired by the remarks in this paper, but with several of my own thoughts mixed in. If there’s something you disagree with, blame me first!
Why do we need a new reference architecture?
Cloud-native systems represent by far the largest, most distributed, computing systems in our history. And the established cloud-native architectural principles behind them aren’t changing here. But zoom out one level of abstraction, and you can also look at cloud platforms as the largest, most-centralised, computing systems in our history. We push as much data processing as possible onto warehouse-scale computers and systems software. It’s a planet-scale client-server architecture with an enormous number of mostly thin clients sharing the services of a few giant server systems. There are several pressures on such a design:
- The volume of data continues to grow – by another 2 orders of magnitude this decade according to IDC – as does the velocity of data arrival and the variance in arrival rates. At the same time, end users want results faster – from batch to real-time.
We are observing significant demand from users in terms of avoiding batch telemetry pipelines altogether.
- It makes heavy use of comparatively expensive data-center computing facilities
- It’s limited by the laws of physics in terms of end-to-end latency
- It’s more challenging to build privacy-respecting systems when all data needs to shipped remotely to be processed
The first two of these pressures combine to cause cloud systems to run into one of two limits as exemplified by this quote from the paper:
None of our existing systems could handle these requirements adequately; either the solution did not scale or it was too expensive to capture all the desired telemetry. (Emphasis mine)
Latency limits are one of the drivers pushing us towards more edge computing – a trend which began with static content distribution, then dynamic content (both of which sit on the response path), and now is extending to true edge computation (that can also help improve the request path, e.g. by local processing either eliminating or reducing the amount of data that needs to be sent on to central servers). Industrial IoT use cases are an example here.
The emergence of edge computing has raised new challenges for big data systems… In recent years a number of distributed streaming systems have been built via either open source or industry effort (e.g. Storm, Spark Streaming, MillWheel, Dataflow, Quill). These systems however adopt a cloud-based, centralised architecture that does not include any “edge computing” component – they typically assum an external, independent data ingestion pipeline that directs edge streams to cloud storage endpoints such as Kafka or Event Hubs.
On the privacy front, with increasing awareness and regulation (a good thing, imho!), it’s getting much more complex and expensive to process, store, and secure potentially sensitive data. The most cost-effective mechanism of all is not to store it centrally, and not to process it centrally. Securing data you don’t have and never saw is free! In this regard the machine learning community is ahead of the systems community, with a growing body of work on federated machine learning.
The GDPR directive requires that companies holding EU citizen data provide a reasonable level of protection for personal data… including erasing all personal data upon request… Finding the list of data streams that contain the user’s information requires a provenance graph (as the number of streams is in the order of 10s of billions) and an index (as each stream can span multiple peta-bytes) to avoid expensive linear scans.
What does the new reference architecture look like?
The central idea in the Helios architecture is ’embrace the edge’. Although the word federated doesn’t actually appear in the paper at all, federated big-data systems (c.f. federated machine learning and federated database management systems) seems a reasonable way of describing what’s going on here.
Helios is an effort towards building a new genre of big data systems that combine the cloud and edge as a single, holistic data processing platform.
(And by extension, we could envision end-user devices being part of that holistic platform too).
In the olden days we used to talk about function shipping and data shipping. Function shipping being the idea that you move the compute to the data, and data shipping being the idea that you move the data to the compute. Within todays cloud systems, a lot of function shipping takes place, but for the clients that interact with them, it’s very heavily skewed towards data shipping. In federated big-data systems perhaps the appropriate terms would be function spreading and data spreading. I.e. compute can take place at multiple different points along the path from end device to cloud (and back again), and data can be spread out across layers too. A good guiding principle for designing such a system is probably to minimise data movement – i.e. (1) do as much processing as possible as close to the point of data capture as possible, and only send the aggregated results downstream, and then (2) where pools of data do amass, do as much querying of that data as close to the point of data storage as possible and only send the query results back upstream.
In Helios, this translates to coming up with efficient techniques for splitting computation between end devices, edge, and cloud.
This split has another interesting consequence. We saw earlier that there is end-user pressure to replace batch systems with much lower latency online systems. I observe that computation split across end devices, edge, and cloud doesn’t really sit well with batch processing either. We do distributed batch processing within a layer (e.g. map-reduce) but across layers is different. My conclusion is that federated big-data systems are also online systems. One nice advantage of unifying batch and online processing is that we don’t need to duplicate logic:
This solves the problem of maintaining code that needs to produce the same result in two complex distributed systems.
Generally batch systems have higher throughput and higher latency, and as we reduce the batch size towards online systems, we lower the latency and also the throughput. It will be interesting to watch the throughput characteristics of federated big data systems, but it’s a challenge I think we have to take on. (Helios’ throughput is plenty good enough btw.)
Technically, what might it look like to build a system that works in this way?
Based on our production experience, we posit that a single engine model can (1) enable optimizations such as automatically converting recurring batch queries into streaming queries, dynamically mapping operators/computations to various layers (e.g., end device, edge, cloud), automated A/B testing for figuring out the best query execution plans, join query optimization in multi-tenant scenarios and automatic cost-based view materialisation, and (2) significantly reduce user and operational burden of having to learn and maintain multiple complex stacks.
I’m going to throw one more requirement into the mix for next-generation big data systems. You won’t find this in the Helios paper, but it is something that Microsoft have articulated well in other works, notably Cloudy with a high chance of DBMS: a 10-year prediction for enterprise-grade ML . From a data systems perspective, machine learning is just data processing over (usually) big data sets. We don’t really want completely separate systems for federated machine learning and federated big-data, especially as there are many data cycles between the two (ML both consuming and producing data) and ML is increasingly becoming a mainstream part of many systems and applications. See e.g. the introduction to ‘The case for a learned sorting algorithm.’
The picture that forms in my mind is of a federated differential dataflow style system that processes and materializes just what is needed at each layer. E.g. in the Helios case, “we can similarly distribute the task of data summarization – including filtering, projections, index generation, and online aggregation – to end devices.” One nice thing that falls out of extending such a system all the way out to the end devices is that it means the dataflow engine is effectively responsible for managing all of those pesky caches, and especially cache invalidation.
There might be many different layers of edge compute (e.g. 5G base stations, CDN POPs, …) between an end-(user) device and a warehouse scale computer (WSC, aka the cloud). You can think of these as concentric rings forming around WSCs, and conceptually a federated big data system can span all of them.
So far we’ve mostly been talking about spreading compute and data along a single path from an end device to the cloud and back again, leading to a picture like this.
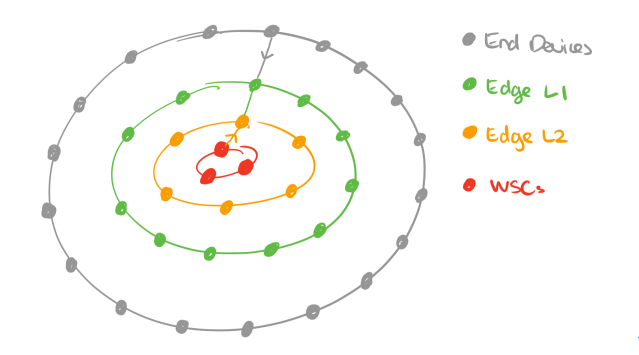
But of course it’s entirely possible (and common) for a node at one layer to interact with multiple nodes at the layer below, leading to a picture more like this:

And furthermore it’s easy to imagine cases where peer-to-peer communication between nodes at the same level also makes sense:

In general we’re looking at a dynamic dataflow topology with very large numbers of nodes.
Helios is a successful production example of a subset of these ideas, and we’ll look at Helios itself in much more detail in the next post. For now I’ll close with this thought:
Helios provides one example for a specific type of computation, i.e. indexing of data. There are a number of related problems, such as resource allocation, query optimization, consistency, and fault tolerance. We believe that this is a fertile ground for future research.
