It’s common knowledge that the IEEE standard floating point number representations used in modern computers have their quirks, for example not being able to accurately represent numbers such as 1/3, or 0.1. The wikipedia page on floating point numbers describes a number of related accuracy problems including the difficulty of testing for equality. In day-to-day usage, beyond judicious use of ‘within’ for equality testing, I suspect most of us ignore the potential difficulties of floating point arithmetic even if we shouldn’t. You’d like to think that scientific computing applications which heavily depend on floating point operations would do better than that, but the results in today’s paper choice give us reason to doubt.
…despite a superficial similarity, floating point arithmetic is not real number arithmetic, and the intuitive framework one might carry forward from real number arithmetic rarely applies. Furthermore, as hardware and compiler optimisations rapidly evolve, it is challenging even for a knowledgeable developer to keep up. In short, floating point and its implementations present sharp edges for its user, and the edges are getting sharper… recent research has determined that the increasing variability of floating point implementations at the compiler (including optimization choices) and hardware levels is leading to divergent scientific results.
The authors develop a tool called FPSpy which they use to monitor the floating point operations of existing scientific applications. The nature of these applications makes it difficult to say whether or not their outputs are ultimately incorrect as a result of floating point issues, but FPSpy is certainly a smoking gun suggesting that there are a lot of potential lurking problems.
The applications
The study is conducted using a suite of 7 real-world popular scientific applications, and two well-established benchmark suites:
Miniaero solves the compressible Navier-Stokes equation
LAMMPS is a molecular dynamics simulator
LAGHOS is a hydrodynamics application for solving time-dependent Euler equations of compressible gas dynamics
MOOSE is a parallel finite element framework for mechanics, phase-field, Navier-Stokes, and heat conduction problems
WRF is a weather forecasting tool
ENZO is an astrophysics and hydrodynamics simulator
GROMACS is a molecular dynamics application
PARSEC is a set of benchmarks for multi-threaded programs
NAS 3.0 is a set of benchmarks for parallel computing developed by NASA
Together they comprise about 7.5M lines of code.
How FPSpy works
FPSpy is designed to be able to run in production using unmodified application binaries, and is implemented as an LD_PRELOAD shared library on Linux. It interposes on process and thread management functions to follow thread and process forks, and on signal hooking and floating point environment control functions to know when it needs to ‘get out of the way’ in case it should interfere with application execution.
FPSpys builds on hardware features that detect exceptional floating point events as a side-effect of normal processing… The IEEE floating point standard defines five condition codes, while x64 adds an additional one. These correspond to the events FPSpy observes.
The condition codes are sticky, meaning that once a condition code has been set it remains so until it is explicitly cleared. This enables an extremely low overhead mode of FP-spying the authors call aggregate mode, which consists of running the application / benchmark and looking to see which conditions were set during the execution. It also has an individual mode which captures the context of every single instruction causing a floating-point event during execution. Users can filter for the subset of event types they are interested in (e.g., to exclude the very common Inexact event due to rounding), and can also configure subsampling (e.g. only record 1 event in 10, and no more than 10,000 events total). A Poisson sampling mode enables sampling of all event types across the whole program execution, up to a configurable overhead.
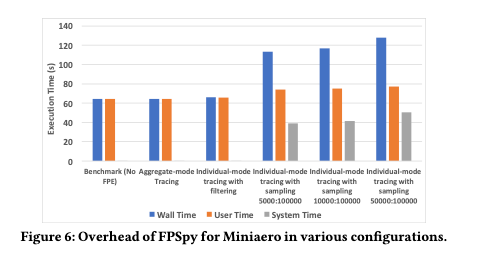
The chart below shows the overhead of FPSpy for the Miniaero application. The overheads are very low in aggregate mode, and in individual mode with Inexact events filtered out. The three ‘tracing with sampling’ runs do include Inexact events.
What FPSpy found
The first discovery is that there is very little usage of floating point control mechanisms in these applications (e.g. checking for and clearing conditions). In fact, only the WRF weather forecasting tool used any floating point control mechanisms at runtime.
Beyond arguing for FPSpy’s generality, the static and dynamic results also suggest something important about the application: the use of floating point control during execution is rare. Because very few applications use any floating point control, problematic events, especially those other than rounding, may remain undetected.
Aggregate-mode testing of the applications reveals that indeed they do have problematic events. For example, ENZO has NaNs, and LAGHOS divides by zero.
Using individual mode tracing, it’s possible to see not only what conditions occur, but also how often and where in the application. ENZO for example produces NaNs pretty consistently all throughout its execution, whereas LAGHOS shows clear bursts of divide-by-zero errors.
Mitigating rounding errors
Rounding errors (Inexact) deserve a special treatment of their own because they are so common, and expected. Just because they are expected though, doesn’t always mean it’s safe to ignore them.
Inexact (rounding) events are a normal part of floating point arithmetic. Nonetheless, they reflect a loss of precision in the computation that the developer does need to reason about to assure reasonable results. In effect, lossses of precision introduce errors into the computation. When modeling, for example, a system that involves chaotic dynamics, such errors, even if they are tiny, can result in diverging or incorrect solutions.
The MPFR library supports multiple precision floating point operations with correct rounding. The analysis from FPSpy suggests that a relatively small number of instruction forms are responsible for the vast majority of the rounding errors in the applications under study. For the most part, less than 100 instructions account for more than 99% of the rounding errors. This suggests the potential to trap these instructions and call into MPFR or an equivalent instead.
This would allow existing, unmodified application binaries to seamlessly execute with higher precision as necessary, resulting in less or even no rounding… By focusing on less than 5000 instruction sites and handling less than 45 instruction forms at those sites, such a system could radically change the effects of rounding on an application… We are currently implementing various approaches, including trap-and-emulate.
Next time out we’ll be looking at a PLDI paper proposing a new API for computations involving real numbers, one that has been designed to give results matching much more closely to our intuitions.