Static analysis of Java enterprise applications: frameworks and caches, the elephants in the room, Antoniadis et al., PLDI’20
Static analysis is a key component of many quality and security analysis tools. Being static, it has the advantage that analysis results can be produced solely from source code without the need to execute the program. This means for example that it can be applied to analyse source code repositories and pull requests, be used as an additional test in CI pipelines, and even give assistance in your IDE if it’s fast enough.
Enterprise applications have (more than?) their fair share of quality and security issues, and execute in a commercial context where those come with financial and/or reputational risk. So they would definitely benefit from the kinds of reassurances that static analysis can bring. But there’s a problem:
Enterprise applications represent a major failure of applying programming languages research to the real world — a black eye of the research community. Essentially none of the published algorithms or successful research frameworks for program analysis achieve acceptable results for enterprise applications on the main quality axes of static analysis research: completeness, precision, and scalability.
If you try running Soot, WALA, or Doop out of the box on a real-world Java enterprise application you’re likely to get very low coverage, or possibly even no results at all if the tool fails to complete the analysis.
Why is static analysis of enterprise apps so hard?
Several features of enterprise applications are unfriendly to static analysis tools:
- There are a lot of frameworks, at several different layers (e.g. Spring, EJBs).
- These frameworks make heavy use of inversion of control (i.e., the framework itself determines invokes entry points)
- Dependency injection is heavily used to provide classes with their critical dependencies (so you can’t just read the local code for analysis purposes, and need to understand what will be injected)
- The configuration of the application determines the set of components, their attributes, and how they are connected together (dependency-injected) amongst other things. This configuration can be in annotations, xml, or even determined at runtime.
- Meta-programming and dynamic code generation techniques are often used to adapt plain-old Java objects (aka POJOs) to the requirements of the framework.
In addition, enterprise applications can get pretty large as well!
Popular static analysis frameworks for Java provide no support for the lifecycle or injected semantics of enterprise applications. Instead, analyses expect their users to provide customization for web applications, which is a significant burden, virtually never overcome in practice.
Introducing JackEE
The situation as we have it so far is that you can’t ignore frameworks when analysing enterprise applications, and there are multiple frameworks to be taken into account although the principles underlying those frameworks are similar.
This suggests the layering that JackEE, a static analyser for enterprise Java web applications, adopts:
- A foundational static analysis framework (the authors chose Doop due to its declarative specifications in Datalog, which are amenable to expressing rules).
- A framework-independent layer that understands the core enterprise application concepts. For example, the notions of entry point, controller, filter, and bean.
- A per-framework mapping that translates the specific details of a framework into concepts at the framework-independent layer.
For example, in the Spring Framework the @Controller annotation marks a bean that is both a Controller and also an EntryPointClass. Likewise an @RequestMapping annotation indicates an EntryPointMethod. The following rules map these Spring-specific annotations to the framework-independent layer concepts of Controller, EntryPointClass, and ExercisedEntryPointMethod:

And here are sample rules for determining beans and field-based dependency injection:


2objH analysis
The mapping rules and framework-independent layer deal with understanding the subtleties of enterprise applications, but there still remains the challenge of dealing with their scale. In particular, the authors wanted to use a powerful form of context sensitivity analysis called 2objH, but out of the box it doesn’t scale well in enterprise application contexts.
In context sensitive analysis, a method is analysed separately for every distinct context in which it can be encountered.
In the Java setting, object-sensitivity has been the context sensitivity approach that constitutes the state of the art for precise analysis of realistic programs. In particular, a 2-object sensitive analysis with a context-sensitive heap (2objH) is often considered the golden standard of a “precise analysis” in the literature.
For an invocation base.method() 2objH will ask ‘what object is base?’, and ‘what object allocated base?’ (the two objects).
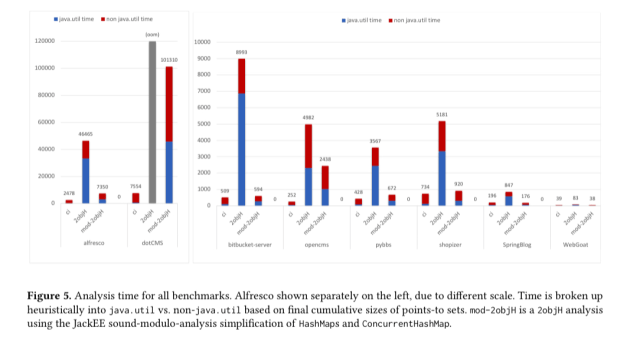
A striking finding of our work with enterprise applications has been that a 2objH analysis is extraordinarily heavy, due to its treatment of
java.util– the very same functionality that 2ojbH is key for handling well.
For one representative enterprise app, the authors found that a standard 2objH analysis spent almost 70% of its execution time in java.util. Way higher than the ~20% seen when analysing desktop applications. All that framework and configuration code makes for very heavy use of generic, heterogeneous data structures!
sound-modulo-analysis
The excessive time spent in java.util turned out to be due to an internal implementation detail of java.util.HashMap, which uses a doubly-dispatched TreeNode under the covers. The double-dispatch is not 2objH friendly. The solution is to introduce a replacement implementation of HashMap that eliminates the TreeNode while preserving all of the externally observable HashMapbehaviours.
The fancy term the authors give to this manoeuvre is sound-modulo-analysis. Sound in that by replicating external behaviours it doesn’t impact the application analysis, and modulo because it replaces one or more modules.
The sound-modulo-analysis modeling of
HashMapstructures in practice results in a more precise analysis, as far as clients of the library are concerned. The reason is that the simplification of the code allows the context sensitivity policy to keep greater precision.
JackEE in action
The authors create a benchmark dataset of open-source enterprise applications, including for example the community edition of alfresco (37,163 classes), dotCMS(46,027 classes), shopizer (33,841 classes) and SpringBlog (18,493). The complete list can be found in section 5 of the paper.
Compared to vanilla Doop, JackEE demonstrates much higher reachability in its analysis of these applications.

Using its sound-modulo-analysis replacement, JackEE was able to complete a full 2objH analysis on all applications with an average speed-up of 5.9x over the original HashMap implementation.
Not only is it faster, but it also has better precision, as can be seen by comparing the mod-2obj+H column with the standard 2obj+H column in the table below. Lower numbers are better.

We hope that JackE can be the beginning of research interest in analyzing enterprise applications. Covering a domain of such complexity and size cannot be achieved via a single step. However, collecting a set of sizable, realistic benchmarks, showing that their analysis is feasible, and making progress in its precision are good ways to ensure further research in this high-value area.
