Building an elastic query engine on disaggregated storage, Vuppalapati, NSDI’20
This paper describes the design decisions behind the Snowflake cloud-based data warehouse. As the saying goes, ‘all snowflakes are special’ – but what is it exactly that’s special about this one?
When I think about cloud-native architectures, I think about disaggregation (enabling each resource type to scale independently), fine-grained units of resource allocation (enabling rapid response to changing workload demands, i.e. elasticity), and isolation (keeping tenants apart). Through a study of customer workloads it is revealed that Snowflake scores well on these fronts at a high level, but once you zoom in there are challenges remaining.
This paper presents Snowflake design and implementation along with a discussion on how recent changes in cloud infrastructure (emerging hardware, fine-grained billing, etc.) have altered the many assumptions that guided the design and optimization of the Snowflake system.
From shared-nothing to disaggregation
Traditional data warehouse systems are largely based on shared-nothing designs: persistent data is partitioned across a set of nodes, each responsible for its local data. Analysed from the perspective of cloud-native design this presents a number of issues:
- CPU, memory, storage, and bandwidth resources are all aggregated at each node, and can’t be scaled independently, making it hard to fit a workload efficiently across multiple dimensions.
- The unit of resource allocation is coarse-grained (a node) and the static partitioning makes elasticity difficult.
- An increasingly large fraction of data in modern workloads comes from less predictable and highly variable sources
For such workloads, shared-nothing architectures beget high cost, inflexibility, poor performance, and inefficiency, which hurts production applications and cluster deployments.
Snowflake is a data warehouse designed to overcome these limitations, and the fundamental mechanism by which it achieves this is the decoupling (disaggregation) of compute and storage. Customer data is persisted in S3 (or the equivalent services when running on Azure or GCP), and compute is handled in EC2 instances. If all data was read from S3 every time, performance would suffer, so of course Snowflake has a caching layer – a distributed ephemeral storage service shared by all the nodes in a warehouse. The caching use case may be the most familiar, but in fact it’s not the primary purpose of the ephemeral storage service. The primary purpose is to handle the (potentially large volumes of) intermediate data that is generated by query operators (e.g. joins) during query processing. Tenant isolation is achieved by provisioning a separate virtual warehouse (VW) for each tenant.
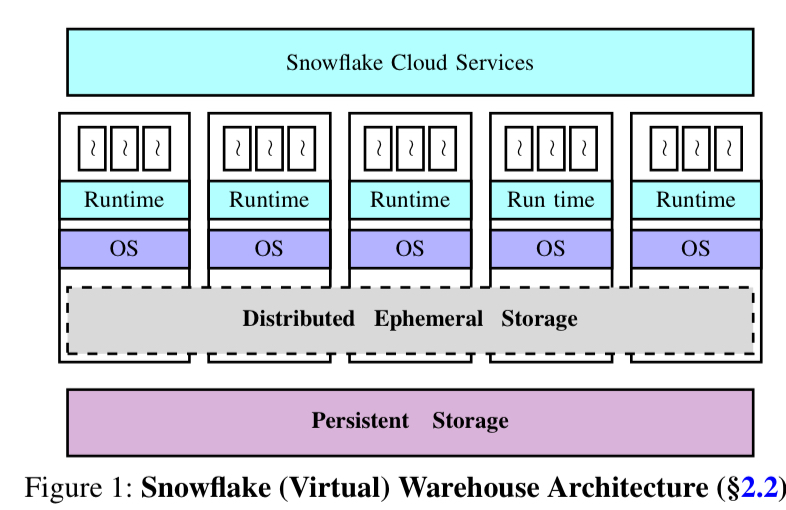
Workload characteristics
The design of Snowflake is influenced by the characteristics of the workloads it needs to support. The paper is based on data collected for ~70 million queries executed over a period of 14 days.
- About 28% of queries are read-only, with the amount of data being read varying over 9 orders of magnitude. Query volume spikes during working hours.
- About 13% of queries are write-only, with the amount of data being written varying over 8 orders of magnitude.
- The remainder are read-write queries, with a read-write ratio varying over multiple orders of magnitude
The queries also require varying amounts of intermediate data to be processed during their execution. Some queries can exchange hundreds of gigabytes or even terabytes of intermediate data. Predicting the volume of intermediate data generated by a query is "hard, or even impossible" for most queries. Intermediate data sizes vary over multiple orders of magnitude across queries, and have little or no correlation with the amount of persistent data read or the expected execution time of the query.
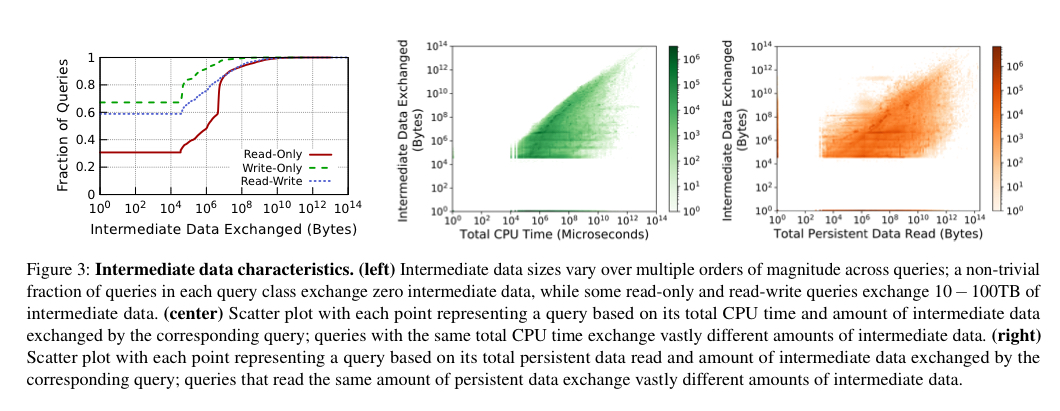
Disaggregation (or not)
So far we’ve seen that the persistent storage and compute layers are disaggregated in Snowflake: able to be scaled independently, and with all persistent storage accessible from any node. But the ephemeral storage service for intermediate data is not based on S3. It’s a three-tier with in-memory data on a node spilling to local SSDs when needed, which in turn spill over to S3 if they are exhausted. The main two tiers of this storage system therefore, are not disaggregated and are tied to the compute nodes. When not required for intermediate data, the same ephemeral storage is used as a write-through cache for frequently accessed persistent data. A consistent hashing scheme maps data to nodes.
Ideally intermediate data would fit entirely in memory, or at least in SSDs, without spilling to S3. Given the coupling of compute, memory, and SSDs this proves challenging to provision for. As we’ve saw earlier, the volume of intermediate data can vary across orders of magnitude, and predicting how much will be generated is difficult.
The first of these challenges could be addressed by decoupling compute and ephemeral storage (future work). Since prediction is difficult, fine-grained elasticity of the ephemeral storage layer would also be required.
The amount of ephemeral storage available for caching is much smaller than a typical customer’s overall persistent data volume – the cache can accommodate just 0.1% of the persistent data on average. Nevertheless, access patterns mean that hit rates of close to 80% for read-only queries and 60% for read-write queries can be achieved.
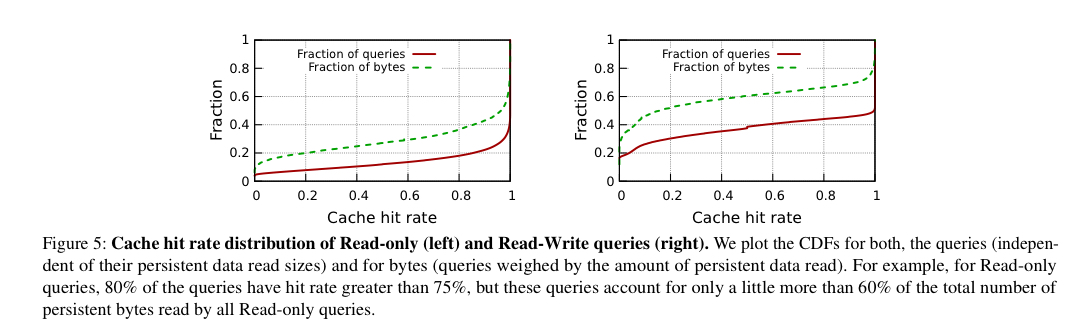
Since end-to-end query performance depends on both cache hit rate for persistent data files and I/O throughput for intermediate data, it is important to optimize how the ephemeral storage system splits capacity between the two. Although we currently use the simple policy of always prioritizing intermediate data, it may not be the optimal policy with respect to end-to-end performance objectives.
Elasticity
Persistent storage elasticity is provided by the underlying stores (e.g. S3 on AWS). A virtual warehouse comprises a set of compute nodes, and compute elasticity is achieved by adding or removing nodes on an on-demand basis. By using a pre-warmed pool of nodes, compute elasticity can be provided at a granularity of tens of seconds. Given that Snowflake uses consistent hashing (with work stealing) to assign tasks to nodes where the persistent data they need to access resides, adding or removing nodes can require large amounts of data to be reshuffled. Snowflake does this lazily: after a reconfiguration consistent hashing may send a task to the new home node for a partition, which won’t have that data yet. At this point the data will be read from persistent storage and cached. Eventually the data in the old home node will be evicted from the cache there too.
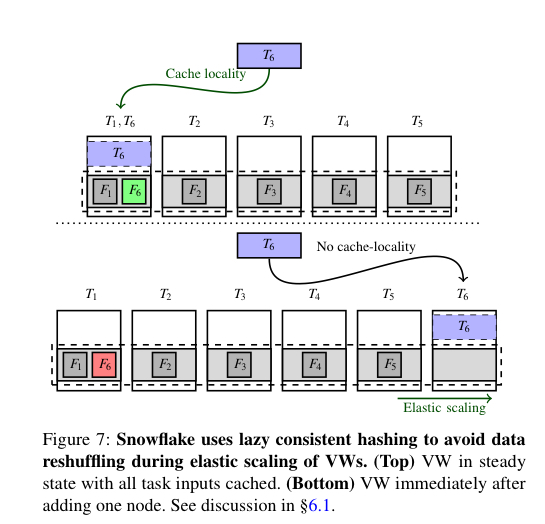
Warehouse scaling is currently fairly coarse-grained, and requires customers to request resizing. Inter-query arrivals times vary much more frequently than customers resize their warehouses. More than 80% of customers don’t request resizing for their warehouses at all. Ideally Snowflake would support auto-scaling both between queries (work is in progress on this) and also during execution of an individual query (resource consumption can vary significantly in a query’s lifetime).
Going further, Snowflake would like to explore serverless platforms for their auto-scaling, high elasticity, and fine-grained billing.
… The key barrier for Snowflake to transition to existing serverless infrastructures is their lack of support for isolation, both in terms of security and performance.
The Firecracker paper suggests to me this doesn’t have to be the case, but it would certainly require a disaggregated ephemeral storage solution which seems the bigger challenge to me.
Isolation
Tenant isolation in Snowdflake is at the virtual warehouse level (every customer gets their own VW). VWs achieve "fairly good, but not ideal, average CPU utilization; however other resources are usually underutilized on average".
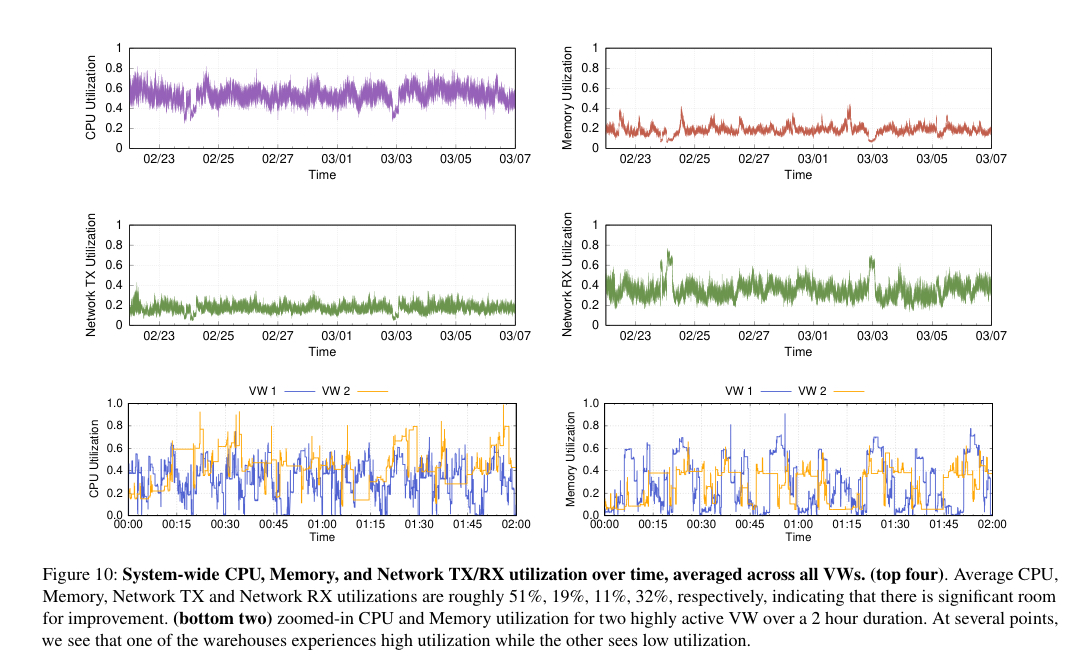
While we were aware of this performance isolation versus utilization tradeoff when we designed Snowflake, recent trends are pushing us to revisit this design choice. Specifically, maintaining a pool of pre-warmed instances was cost-efficient when infrastructure providers used to charge at an hourly granularity; however, recent moves to per-second pricing by all major cloud infrastructure providers has raised interesting challenges.
Snowflake would like to reduce their operational costs, and customers would also like finer-grained pricing. "With per-second billing, we cannot charge unused cycles on pre-warmed nodes to any particular customer". To cross this bridge Snowflake will need to rethink the isolation model, multiplexing customer demands across a set of shared resources. Of course, this has to be done whilst retaining strong isolation properties. The two key resources that need to be isolated are compute and ephemeral storage. Compute isolation in a data center context has been well studied, memory and storage isolation less so.
For ephemeral storage the challenge is fairly sharing cache across tenants, and being able to scale to meet the demands of one tenant without impacting others (e.g. the lazy consistent hashing scheme as currently employed would cause multiple tenants to see cache misses, not just the one triggering the resize). [FairRide][FairRide] is cited as one potentially relevant piece of prior work here.
The memory issue is both important (memory utilisation in VWs is currently low, and DRAM is expensive) and difficult to address. It requires both a disaggregated memory solution for independent scaling, and an efficient mechanism to share that disaggregated memory across multiple tenants.
The scorecard
…Snowflake achieves compute and storage elasticity, as well as high-performance in a multi-tenancy setting. As Snowflake has grown to serve thousands of customers executing millions of queries on petabytes of data every day, we consider ourselves at least partially successful. However, … our study highlights some of the shortcomings of our current design and implementation and highlights new research challenges that may be of interest to the broader systems and networking communities.

this is an error [FairRide][FairRide]
should be corrected as “https://www.usenix.org/system/files/conference/nsdi16/nsdi16-paper-pu.pdf”