Firecracker: lightweight virtualisation for serverless applications, Agache et al., NSDI’20
Finally the NSDI’20 papers have opened up to the public (as of last week), and what a great looking crop of papers it is. We looked at a couple of papers that had pre-prints available last week, today we’ll be looking at one of the most anticipated papers of this year’s crop: Amazon’s Firecracker.
Firecracker is the virtual machine monitor (VMM) that powers AWS Lambda and AWS Fargate, and has been used in production at AWS since 2018. Firecracker is open source, and there are a number of projects that make it easy to work with outside of the AWS environment too, including Weave Firekube (disclaimer: Accel is an investor in Weaveworks). Firekube exists because none of the existing alternatives (virtualisation, containers or language-specific vms) met the combined needs of multi-tenant efficiency and strong isolation in the AWS environment.
The traditional view is that there is a choice between virtualization with strong security and high overhead, and container technologies with weaker security and minimal overhead. This tradeoff is unacceptable to public infrastructure providers, who need both strong security and minimal overhead.
Approaches to isolation
The first version of AWS Lambda was built using Linux containers. Multiple functions for the same customer would run inside a single VM, and workloads for different customers ran in different VMs. Thus containers provided isolation between functions, and virtualisation provided the (stronger) isolation between accounts. This approach puts some limitations on packing efficiency, and also necessitates a container trade-off between security and code compatibility based on the types of syscalls containers are allowed to make.
A modern commodity server can contain up to 1TB of RAM, and Lambda functions can use as little as 128MB. So you need up to 8000 functions on a server to fill the RAM (more in practice due to soft allocation). This also makes any solution very sensitive to per-function (per isolation unit) overheads.
The ideal isolation solution would have the following properties:
- Strong isolation (multiple functions on the same hardware, protected against privilege escalation, information disclosure, covert channels, and other risks).
- The ability to run thousands of functions on a single machine with minimal waste
- Close to native performance
- Support for arbitrary Linux binaries and libraries without code changes or recompilation
- Fast start-up and tear-down of functions
- Soft-allocation support whereby each function consumes only the resources it needs (up to its limit), not the amount it is actually entitled to.
The problem with containers
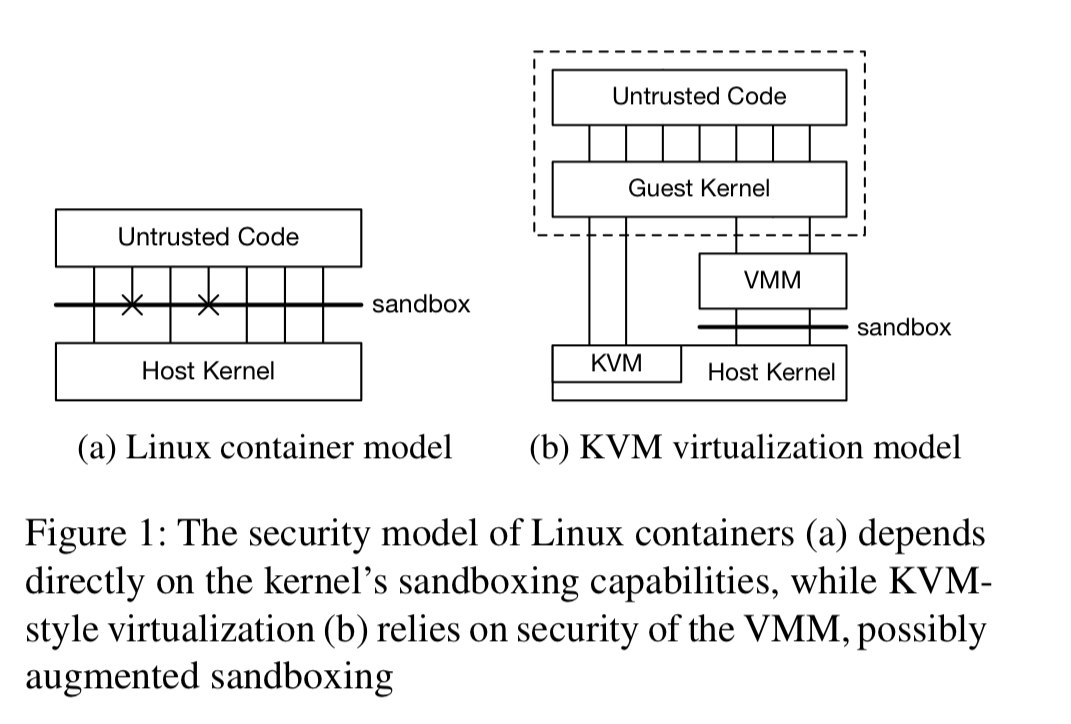
Containers on a host share a single OS kernel, relying on isolation mechanisms built into the kernel for protection.
The fact that containers rely on syscall limitations for their security represents at tradeoff between security and compatibility.
A realistic container enviroment might need access to hundreds of sys calls, together with the /proc and /sys kernel interfaces. One solution for syscalls is to move some of the kernel functionality into userspace, leaving a smaller surface area to secure. That helps protect against privilege escalation, but the richness of /proc and friends means that protecting against covert communication channels is still challenging.
The problem with language VMs
Language-specific VMs, such as V8 isolates, are a non-starter in the AWS Lambda use case because Lambda and Fargate need to be able to support arbitrary binaries.
The problem with virtualisation
Virtualisation has challenges with density, overheads, and startup times. Approaches such as unikernels can help with this, but once again the AWS requirement to be able to run unmodified code rules these out. General-purpose hypervisors and virtual machine monitors (VMMs) are also quite large, leading to a large trusted compute base (TCB). The popular combination of KVM + QEMU runs to over 1M lines of code and requires up to 270 unique syscalls.
The design of Firecracker
All of the existing approaches we just examined involve trade-offs that AWS didn’t want to make. By building Firecracker specifically for serverless and container applications, it was possible to make simplifying assumptions opening up a new design point.
Developing a VMM for a clear set of goals, and where we could make assumptions about the properties and requirements of guests, was significantly easier than developing one suitable for all uses. These simplifying assumptions are reflected in Firecracker’s design and implementation.
What we really want is the isolation characteristics of virtualisation, with the lightweight overheads of containers. “From an isolation perspective, the most compelling benefit is that it moves the security-critical interface from the OS boundary to a boundary supported in hardware and comparatively simpler software“.
At the core of Firecracker therefore is a new VMM that uses the Linux Kernel’s KVM infrastructure to provide minimal virtual machines (MicroVMs), that support modern Linux hosts, and Linux and OSv guests. It’s about 50kloc of Rust – i.e. a significantly smaller code footprint, and in a safe language. Wherever possible Firecracker makes use of components already built into Linux (e.g. for block IO, process scheduling and memory management, and the TUN/TAP virtual network interfaces). By targeting container and serverless workloads, Firecracker needs to support only a limited number of emulated devices, many less than QEMU (e.g. , no support for USB, video, and audio devices). virtio is used for network and block devices. Firecracker devices offer built-in rate limiters sufficient for AWS’ needs, although still considerably less flexible than Linux cgroups.
We implemented performance limits in Firecracker where there was a compelling reason: enforcing rate limits in device emulation allows us to strongly control the amount of VMM and host kernel CPU time that a guest can consume, and we do not trust the guest to implement its own limits. Where we did not have a compelling reason to add the functionality to Firecracker, we used the capabilities of the host OS.
In addition to the VMM, Firecracker also exposes a REST API used to configure, manage, start, and stop MicroVMs.
If you are thinking of deploying Firecracker in a production environment (rather than just using the one that AWS sells), then there are detailed guidelines and recommendations on current side-channel mitigation best-practices for production hosts.
Integrating Firecracker into AWS
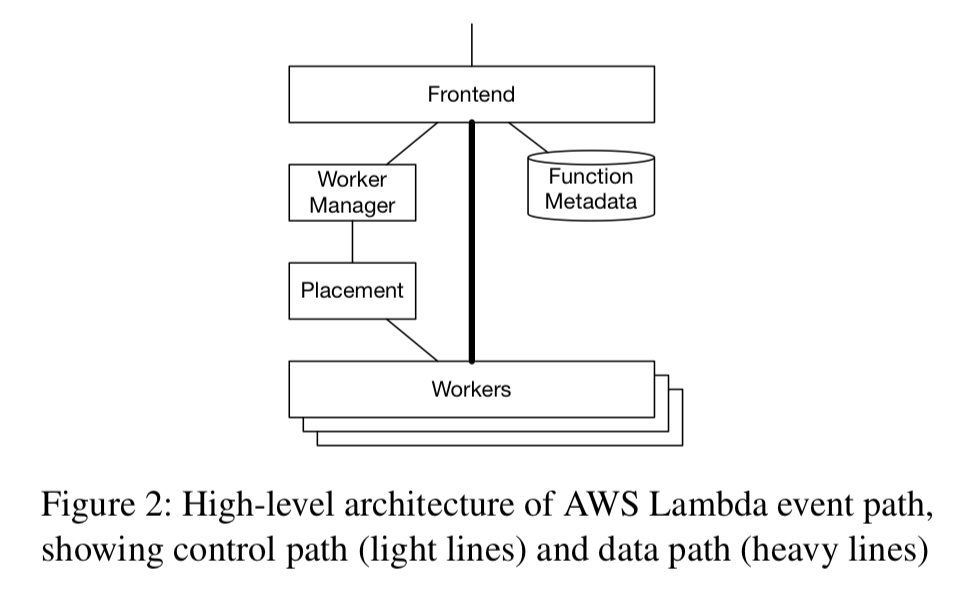
Inside AWS Lamba Firecracker MicroVMs are used to serve trillions of events per month for hundreds of thousands of customers. A Worker Manager routes incoming requests to workers, with sticky routing for a given function to a small number of hosts. Lambda workers offer a number of slots, with each slot being used for many serial invocations of a single function in a MicroVM. If no slot is currently available for a requested function, the Placement service will allocate a slot using time-based leasing.
Each worker runs hundreds or thousands of MicroVMs. One Firecracker MicroManager process is launched for each MicroVM, with responisibilty for creating and managing the MicroVM, providing device emulation, and handling exits. Communication with the MicroVM is over a TCP/IP socket.
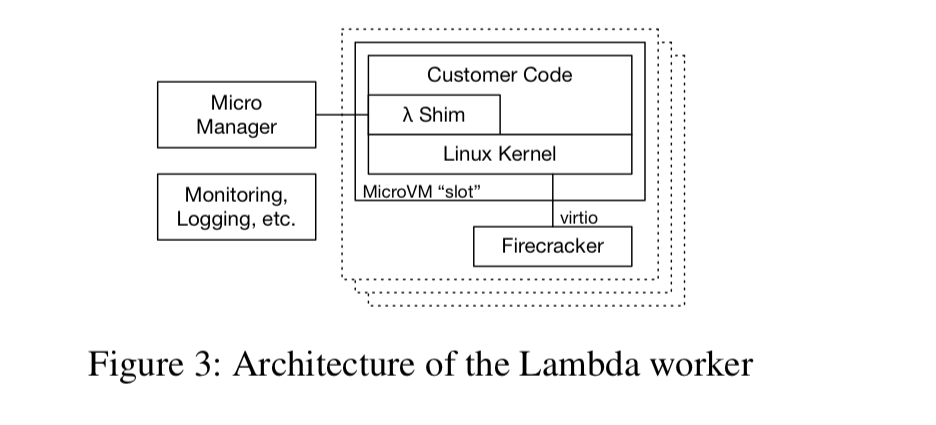
A jailer implements a wrapper around Firecracker which places it into a restrictive sandbox before it boots the guest.
Production experience
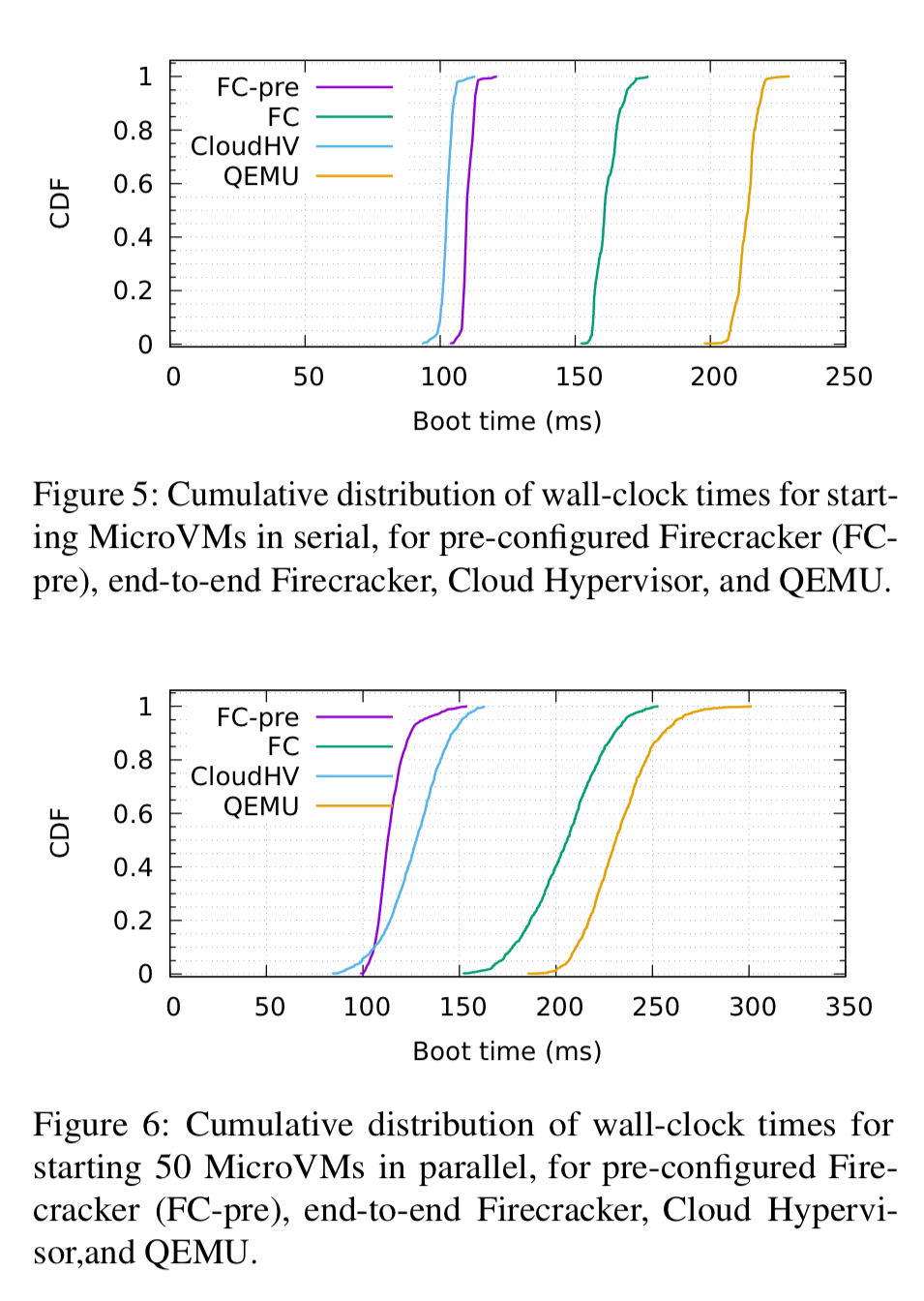
Firecracker MicroVMs boot in around 100ms, 150ms if you also include the API call processing time.
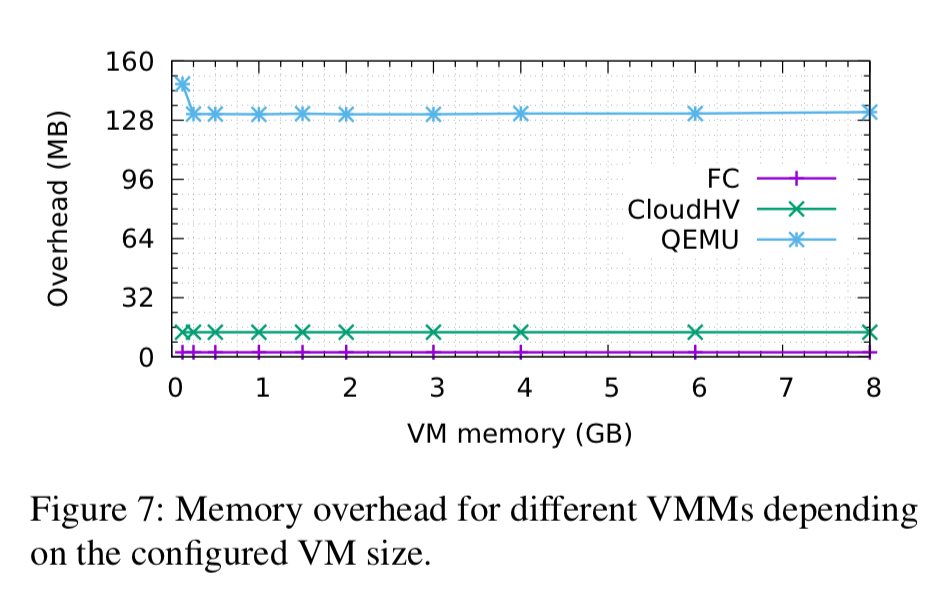
The memory overhead is very low, at around 3MB per MicroVM (compared to 13MB for Cloud Hypervisor, and 131MB for QEMU).
The current weakness of Firecracker is block IO performance. Firecracker (and Cloud Hypervisor) is limited to around 13,000 IOPS (52 MB/s at 4kB), whereas the same hardware is capable of over 340,000 read IOPS (1GB/s at 4kB).
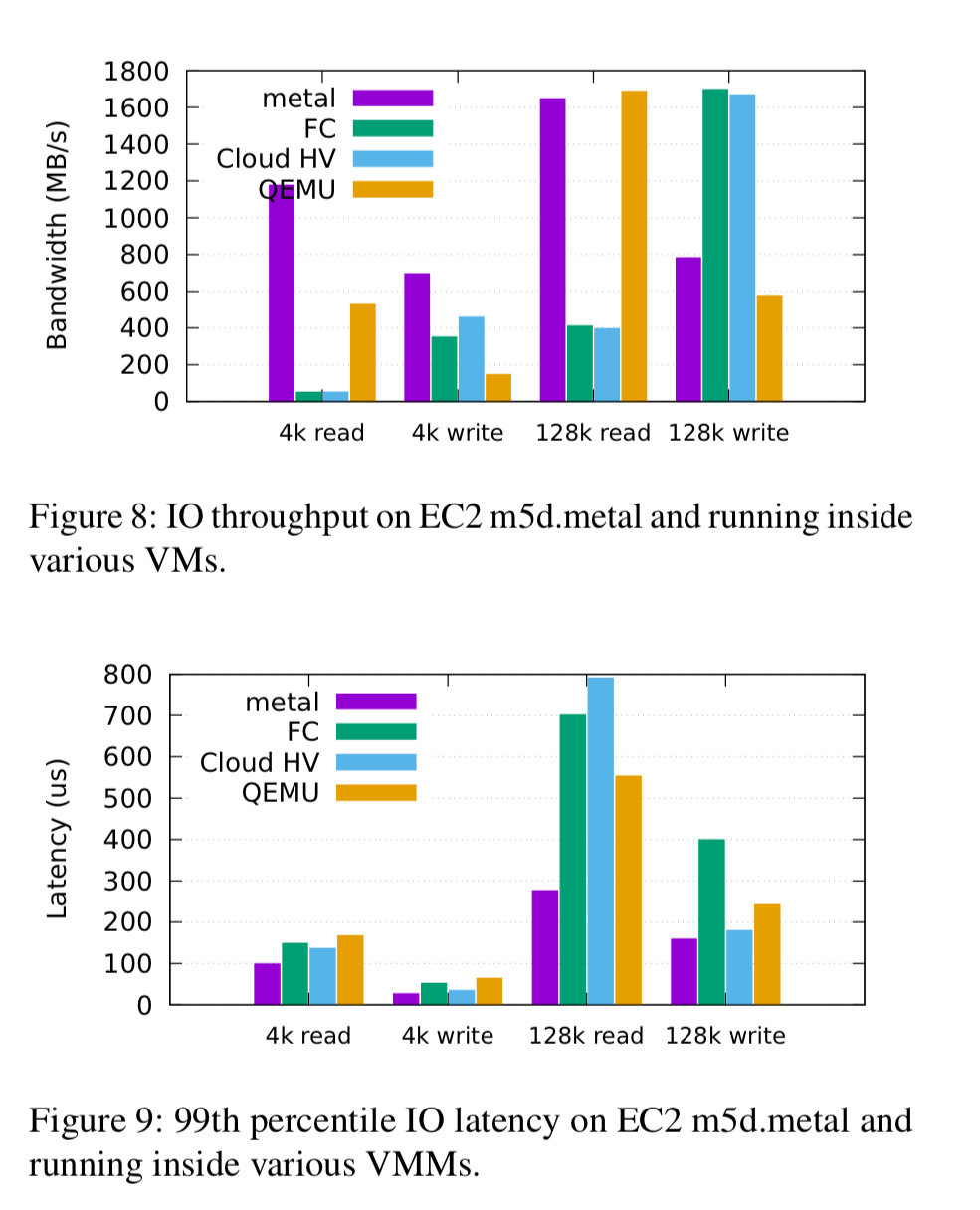
The authors expect significant improvements to be made in this area, but the gap to the near bare-metal performance offered by PCI pass-through will not be fully closed as the hardware is not yet up to the task of supporting thousands of ephemeral VMs.
Memory and CPU over-subscriptions ration have been tested up to 20x without problems, and production ratios of up to 10x have been used.
The last word
In addition to the short-term success, Firecracker will be the bais for future investments and improvements in the virtualization space, including exploring new areas for virtualization technology. We are excited to see Firecracker being picked up by the container community, and believe that there is a great opportunity to move from Linux containers to virtualization as the standard for container isolation across the industry.

Inside AWS Lamba [sic]