Millions of tiny databases, Brooker et al., NSDI’20
This paper is a real joy to read. It takes you through the thinking processes and engineering practices behind the design of a key part of the control plane for AWS Elastic Block Storage (EBS): the Physalia database that stores configuration information.
In the same spirit as Paxos Made Live, this paper describes the details, choices and tradeoffs that are required to put a consensus system into production.
The core algorithms (chain-replication, Paxos-based consensus) aren’t the stars of the show here, instead the paper focuses on how these algorithms are deployed, and the software engineering practices behind the creation of a mission-critical production system employing them.
A guiding principle
Engineering decisions involve making lots of trade-offs. If you want to emerge with a coherent design, then it’s well worth spending some time thinking about the principle(s) by which you’re going to make them. For Physalia, and for AWS more generally, the guiding principle is minimise the blast radius.
Over the decade since [the introduction of Availability Zones], our thinking on failure and availability has continued to evolve, and we paid increasing attention to blast radius and correlation of failure. Not only do we work to make outages rare and short, we work to reduce the number of resources and customers that they affect, an approach we call blast radius reduction. This philosophy is reflected in everything from the size of our datacenter, to the design of our services, to operational practices.
Requirements
To understand the additional forces shaping the design of Physalia, we need to spend a few moments explaining what it actually does!
You’d probably prefer it if your EBS volume didn’t fail (lose data, or become unavailable). EBS uses chain replication for availability, with data flowing from client to primary to replica. Once the chain is setup, this all happens without any external coordination. But if a failure does occur, the chain needs to be reconfigured. Updates to the replication group need to be atomic, ordered, and durable.
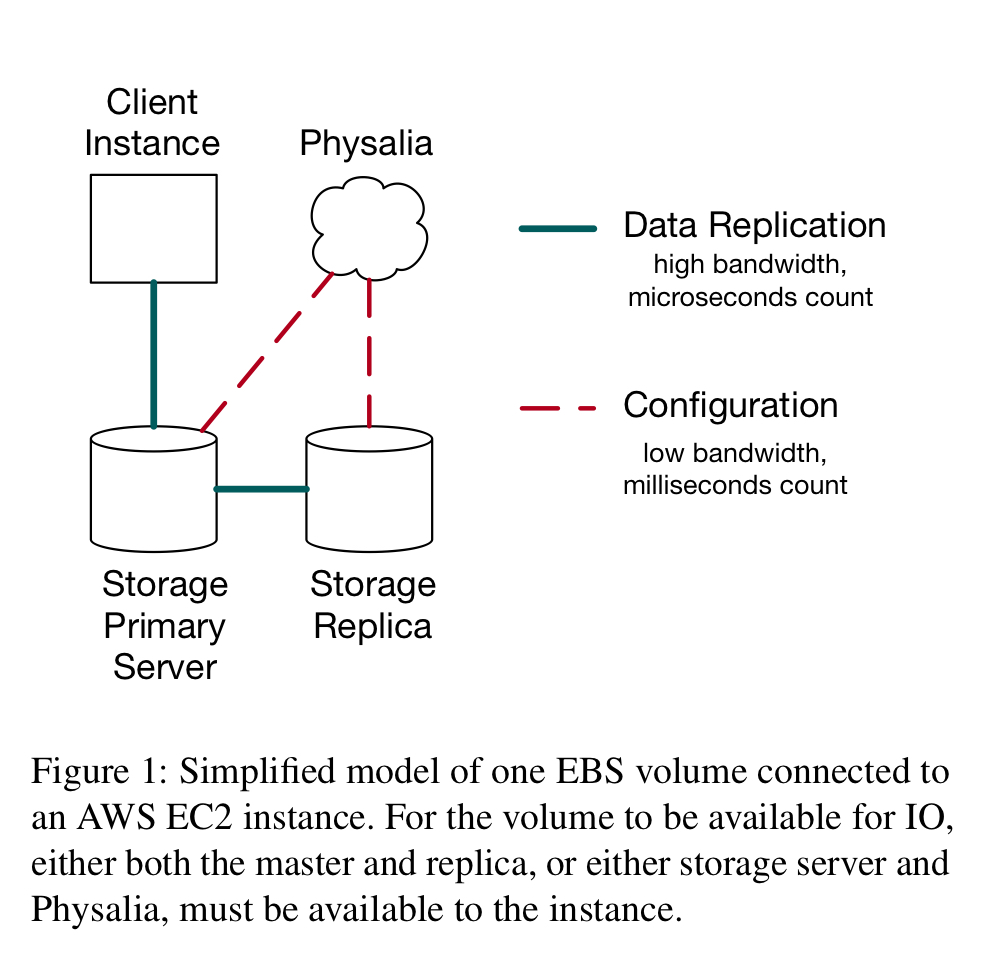
Most of the time the workload is light. But in the event of a large-scale failure there will be a sudden burst of load as many chains need to be reconfigured at once. Thus the configuration master is under stress just when you need it the most.
This work is latency critical, because volume IO is blocked until it is complete. It requires strong consistency, because any eventual consistency would make the replication protocol incorrect. It is also most critical at the most challenging time: during large-scale failures.
Physalia is designed to offer consistency and high-availability, even under network partitions. It is designed to fail gracefully and partially, and to strongly avoid large-scale failures. And, of course, it is designed to minimise the blast radius of any failures that do occur.
Physalia in the large
When I think about minimising blast radius, I immediately think of bulkheads. The bulkhead design pattern suggests partitioning a system so that failure of one partition doesn’t impact the others. If Physalia was designed as one large configuration database for all of EBS, that would be a huge blast radius should it ever fail. So Physalia doesn’t do that. Instead – and the clue is in the paper title, ‘Millions of tiny databases’ – Physalia is constructed as a large number of cells, each serving a small number of clients. If a cell fails, the vast majority of clients will be unaffected.
Our core observation is that we do not require all keys to be available to all clients. In fact, each key needs to be available at only three points in the network: the AWS EC2 instance that is the client of the volume, the primary copy, and the replica copy. Through careful placement, based on our system’s knowledge of network and power topology, we can significantly increase the probability that Physalia is available to the clients that matter for the keys that matter to those clients.
A Physalia installation, or colony, is made up of many cells. Cells are spread across a mesh of nodes (each node running on a single server). A node may participate in many cells. A cell manages the data of a single partition key, and cells are mutually independent.
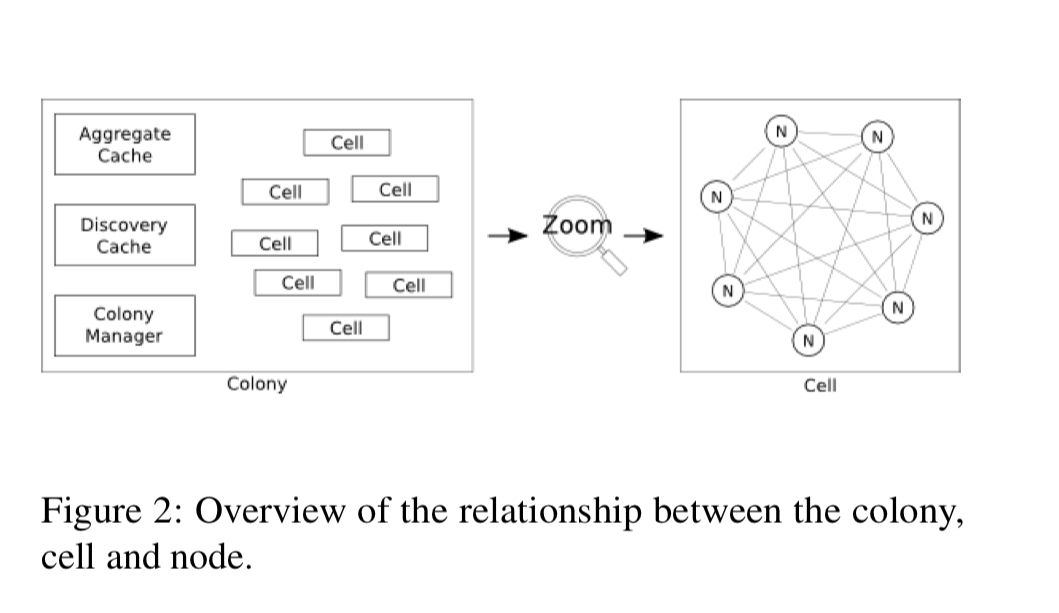
Reconfiguration in Physalia happens all the time – not just in response to failures. Physalia cells are actively moved to be close to their clients by replacing far-away nodes with closer ones, one node at a time. When a node joins or re-joins a cell it needs to be brought up to speed, a process the authors call teaching. There are three modes of teaching:
- In bulk mode, most suitable for new nodes, a bulk snapshot of the cell state is transfered to the learner node from an existing cell node (the teacher)
- In log-based mode, the teacher ships a segment of the log to the learner, enabling the learning to catch-up through replay. This mode works best for nodes re-joining after a partition or pause.
- My favourite mode, just because the name is so great, is the whack-a-mole mode. Whack-a-mole is used when a learner has gaps in its log that can’t be filled by a teacher in the cell. In this case the learner actively tries to propose a no-op transition in the vacant log position (we’re using Paxos here). Either the acceptors will accept the no-op transition, or the learning will discover and subsequently propose another value through this process.
Millions of tiny cells
The division of a colony into a large number of cells is our main tools for reducing radius in Physalia. Each node is only used by a small subset of cells, and each cell is only used by a small subset of clients.
Cells are constructed as consensus-based distributed state machines that use Paxos to reach agreement. Cells have seven nodes. The number seven was carefully chosen:
- Durability improves exponentially with larger cell size
- Larger cells have better tolerance of tail latency (e.g. a slow node experiencing a GC pause)
- A sweet-spot between availability in the face of small numbers of uncorrelated node failures, and availability in the face of large numbers of failures
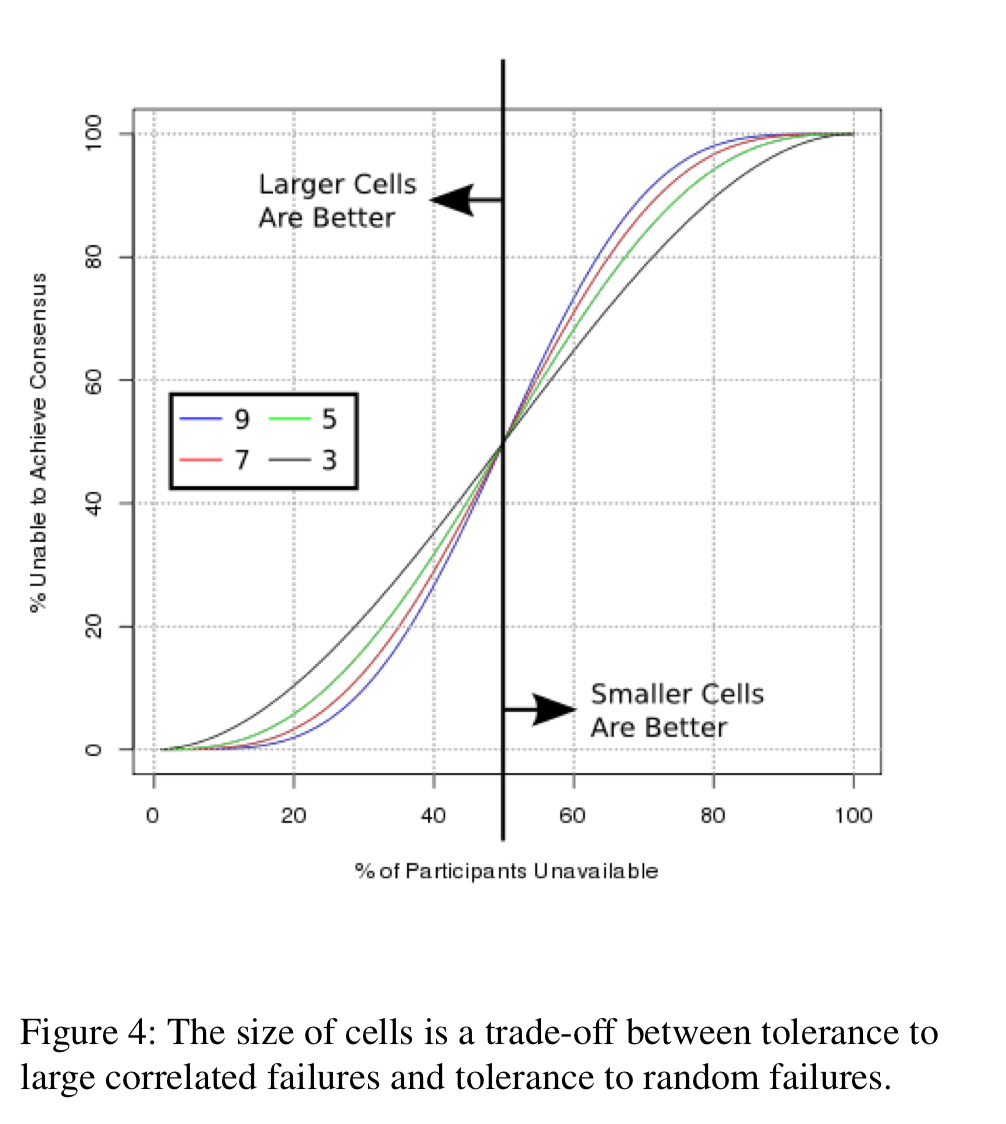
The relatively small transaction rate, and very small data sizes, made the overheads of larger cells manageable.
The many aspects of availability
State-machine replication using consensus is a popular approach for building systems that tolerate faults in single machines, and uncorrelated failures of a small number of machines. In theory, systems built using this pattern can achieve extremely high availability. In practice, however, achieving high availability is challenging. Studies across three decades have found that software, operations, and scale drive downtime in systems designed to tolerate hardware faults. Few studies consider a factor that is especially important to cloud customers: large-scale correlated failures which affect many cloud resources at the same time.
Physalia uses multiple techniques to increase availability and minimise blast radius. Due to the many cell design, a given client only cares about the availability of the cell storing its own data. If the other cells go down (or are unreachable due to a partition) that client will be unaffected. One desirable property therefore, is that in the event of a partition, a client’s Physalia database will be on the same side of the partition as the client. Clever placement of cells across nodes can maximise the chances of this:
Reducing the number of network devices between the Physalia database and its clients reduces the possibility of a network partition forming between them for the simple reason that fewer devices means there’s less to go wrong.
Physalia’s placement engine takes a number of factors into consideration, to continuously optimise for the probability that a volume will be available when its client EC2 instance is available.
Limiting the number of cells dependent on a given node, and the number of clients dependent on a given cell, also helps to minimise the blast radius. This is particulary useful in limiting the effects of poison pills and correlated failures.
In a typical distributed state machine design, each node is processing the same updates and the same messages in the same order. This leads the software on the machines to be in the same state. In our experience, this is a common cause of outages in real-world systems: redundancy does not add availability if failures are highly correlated. Having all copies of the software in the same state tends to trigger the same bugs in each copy at the same time, causing multiple nodes to fail, either partially or completely, at the same time.
A poison pill transaction is one such example – a transaction which passes validition and is accepted in the log, but cannot be applied without causing an error.
Alongside the system design, availability is also a function of operational practices. Incremental deployment (phased rollouts) is ‘a required operational practice for highly available systems.’ The fault tolerant mechanisms built into the system can mask failures from the deployment system though, until they have built to a critical mass (e.g., a majority of nodes). So as well as partitioning the system into millions of tiny databases, the blast radius of bad rollouts is contained by partitioning the system into many different colours.
Operational practices at AWS already separate operational tasks by region and availability zone, ensuring that operations are not performed across many of these units at the same time. Physalia goes a step further than this practice, by introducing the notion of colors. Each cell is assigned a color, and each cell is constructed only of nodes of the same color. The control plane ensures that colorv are evenly spread around the datacenter… When software deployments and other operations are performed, they proceed color-by-color.
Gaining confidence
Testing a large-scale distributed system is far from easy. AWS use a whole battery of approaches to gain confidence in the design and implementation of Physalia.
The challenge of testing a system like Physalia is as large as the challenge of designing and building it. Testing needs to cover not only the happy case, but also a wide variety of error cases.
Key components of the testing (and test-driven-design) strategy include:
- Using TLA+ ("it proved exceptionally useful in the development of Physalia") to: write specifications of the protocols to ensure they were deeply understood; to model check correctness and liveness properties using the TLC model checker; and as a format for protocol documentation.
- Using abstractions and dependency injection to create a test harness (‘simworld‘) in which distributed systems tests can be written and run inside the IDE without the need to spin up actual test clusters etc. (Reminds me of one of the design goals of a certain framework in the enterprise application development space ;) ).
- Using Jepsen to make sure that API responses remained linearizable under network failure cases.
- Performing a number of game days against physical deployments of Physalia.
Our code reviews, simworld tests, and design meetings frequently referred back to the TLA+ models of our protocols to resolve ambiguities in Java code or written communication. We highly recommend TLA+ (and its Pluscal dialect) for this use.
Before and After
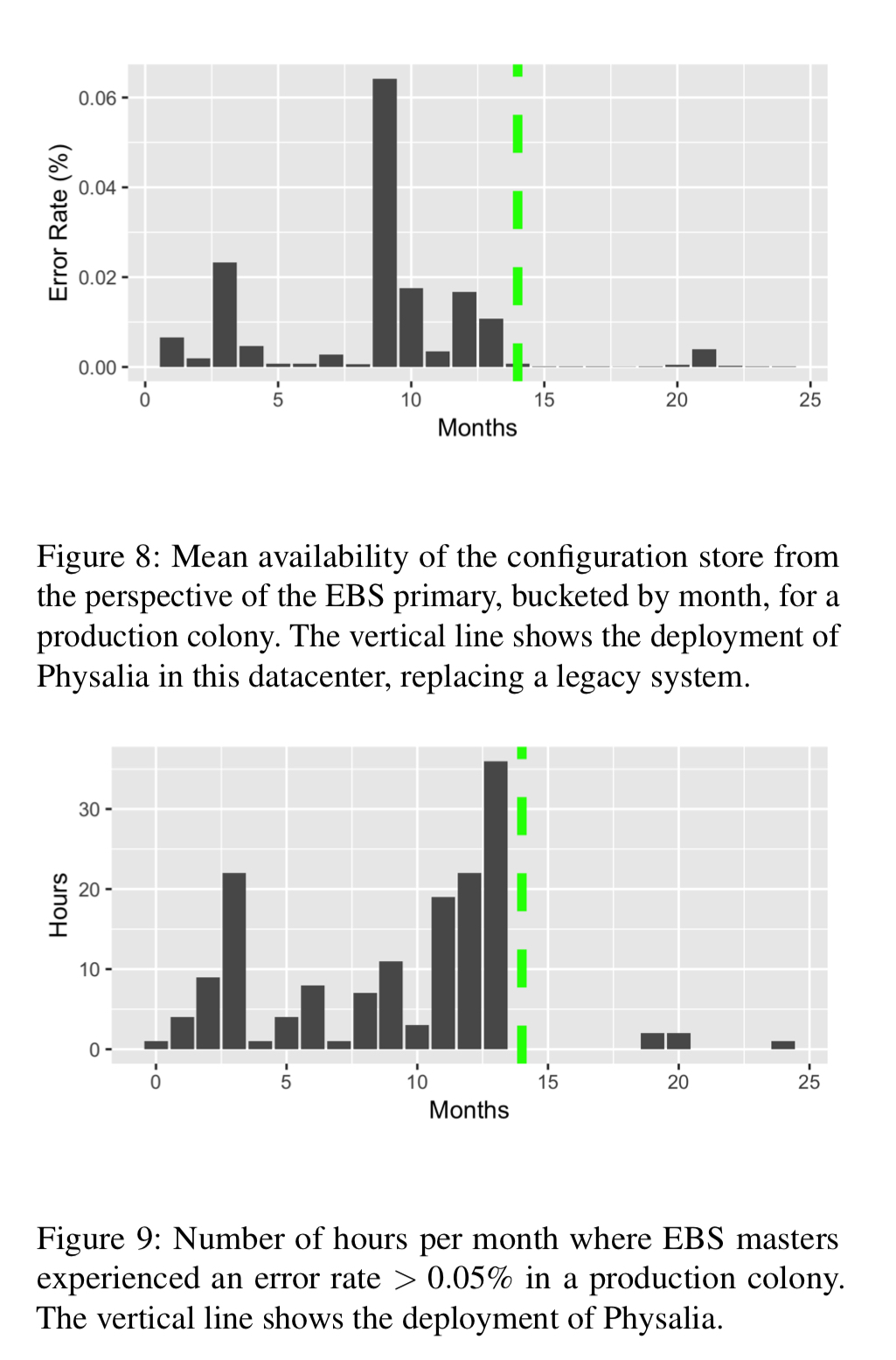
Section 5 in the paper summarises the production experience of deploying Physalia in AWS. I’m already well over my target length with this post, so I’ll keep it brief here and refer you to the paper for the full details. A picture in this case is worth many words: here are the availability charts for EBS, before and after Physalia deployment (the green line)!
And I’ll finish with this one final lesson I can’t resist highlighting:
Postel’s famous robustness principle (be conservative in what you do, be liberal in what you accept from others) does not apply to distributed state machines: they should not access transactions they only partially understand and allow the consensus protocol to treat them as temporarily failed.

14 thoughts on “Millions of tiny databases”
Comments are closed.