Extending relational query processing with ML inference, Karanasos, CIDR’10
This paper provides a little more detail on the concrete work that Microsoft is doing to embed machine learning inference inside an RDBMS, as part of their vision for Enterprise Grade Machine Learning. The motivation is not that inference will perform better inside the database, but that the database is the best place to take advantage of enterprise features (transactions, security, auditing, HA, and so on). Given the desire to keep enterprise data within the database, and to treat models as data also, the question is can we do inference in the database with acceptable performance? Raven is the system that Microsoft built to explore this question, and answer it with a resounding yes.
… based on interactions with enterprise customers, we expect that storage and inference of ML models will be subject to the same scrutiny and performance requirements of sensitive/mission-critical operational data. When it comes to data, database management systems (DBMSs) have been the trusted repositories for the enterprise… We thus propose to store and serve ML models from within the DBMS…
The authors don’t just mean farming inference out to an external process from within the RDBMS, but deeply integrating ML scoring as an extension of relational algebra, and an integral part of SQL query optimisers and runtimes. The vision is that data scientists use their favourite ML framework to construct a model, which together with any data pre-processing steps and library dependencies forms a model pipeline. In Raven, model pipelines are packaged using MLflow. These pipelines are stored directly in the database. A stored model / pipeline can then be invoked a bit like a stored procedure by issuing SQL commands.
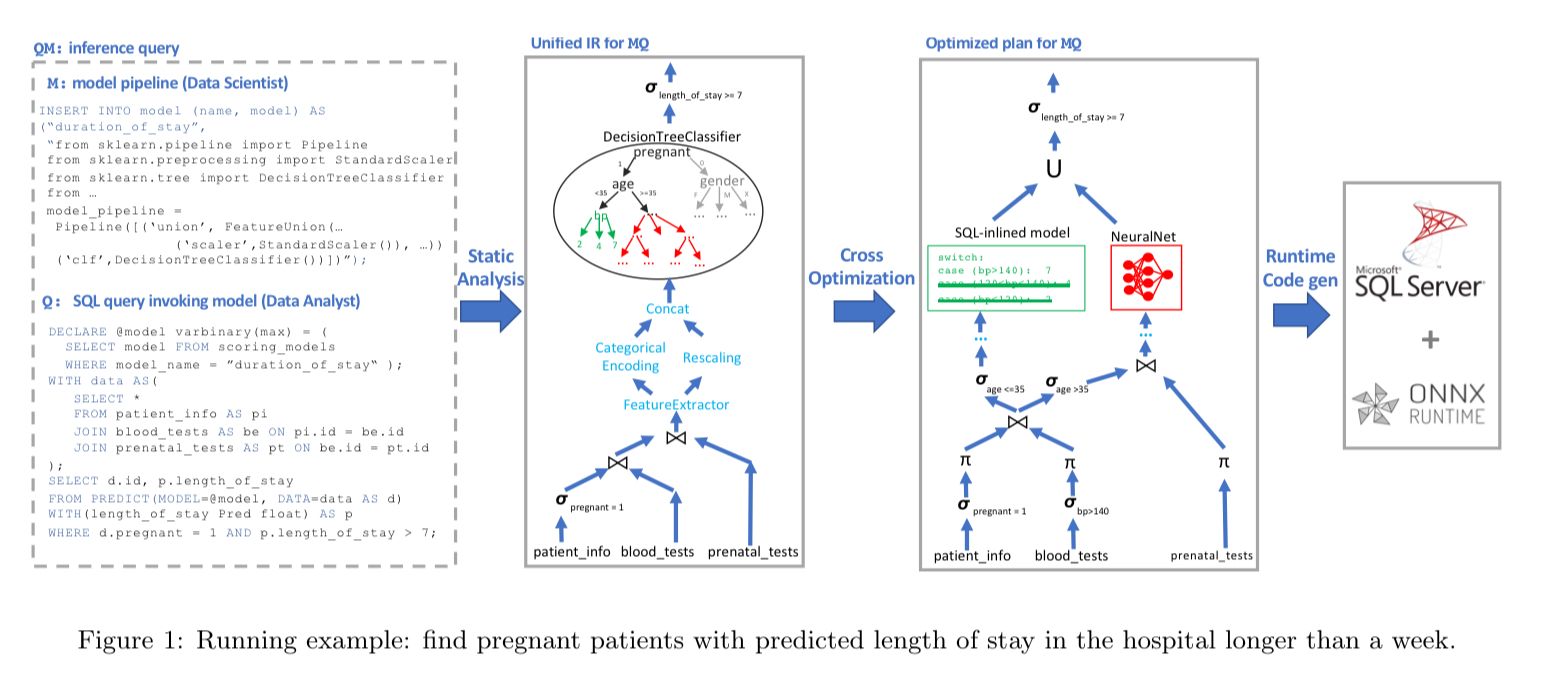
End-to-end the picture looks like this:
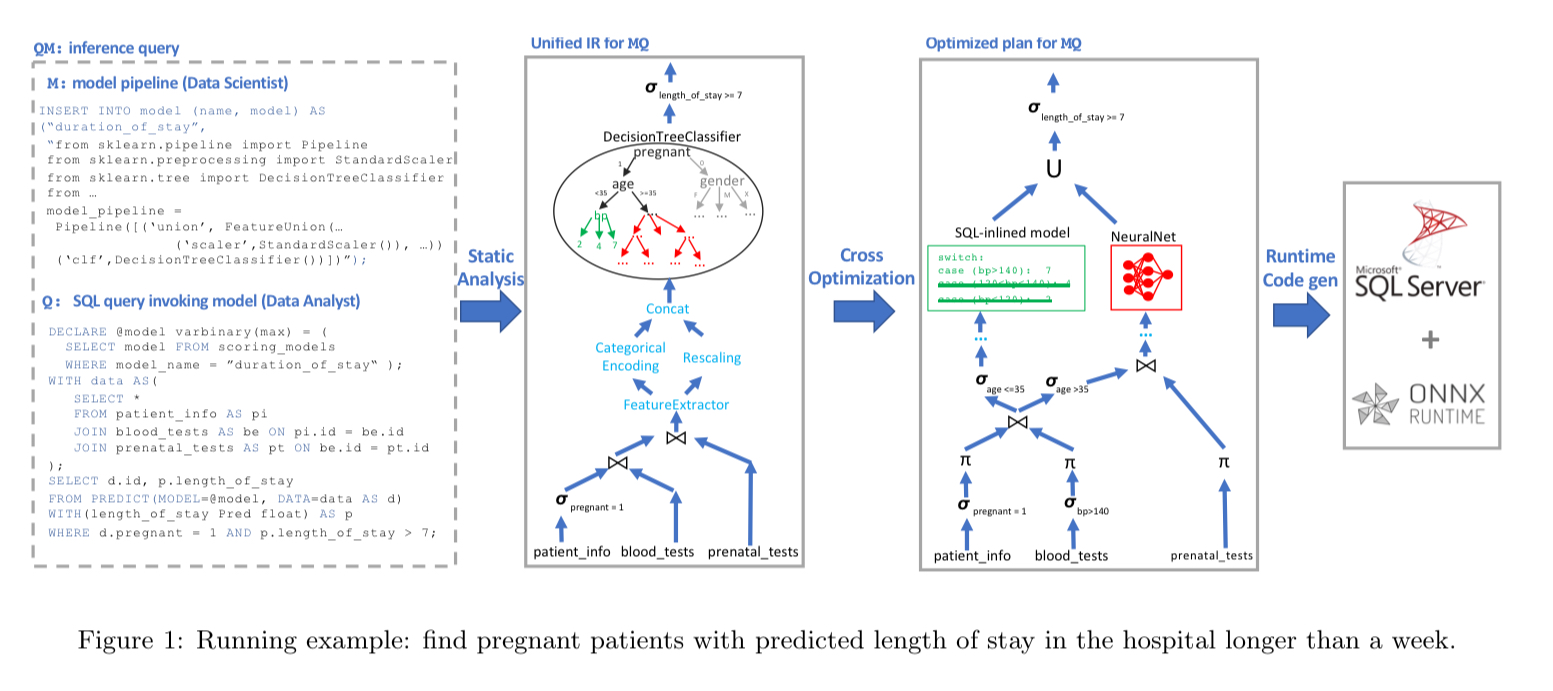
(Enlarge)
- An
INSERT INTO model...statement adds the source code for the model pipeline (Python in the example) to the database. - At some later point a SQL query is issued which
SELECTs a model and then uses thePREDICTfunction to generate a prediction from the model given some input data (which is itself of course the result of a query) - The combined model and query undergo static analysis to produce an intermediate representation (IR) of the prediction computation as a DAG.
- A cross-optimiser then looks for opportunities to optimise the data operator parts of the query given the ML model, and vice-versa (e.g., pruning).
- A runtime code generator creates a SQL query incorporating all of these optimisations.
- An extended version of SQL Server, with an integrated ONNX Runtime engine executes the query.
Static analysis and the IR
In an attempt to be as accommodating as possible to existing data science workflows, the models in model pipelines are simply expressed in Python in MLflow open model format. Unlike SQL queries which are declarative, such models are expressed as imperative programs heavily dependent on libraries. The static analyser has built-in knowledge of popular frameworks and libraries, and knows how to map dataflow nodes and subgraphs to IR operators.
There are limitations to this model of course. It can’t handle loops for example (an analysis of 4.6M Python notebooks in GitHub showed that 17% of notebook used loops). Conditionals result in one plan per execution path, and dynamic typing means not all types can be inferred statically (using knowledge from the SQL queries that feed data into the models for inference can help here). If the static analyser runs into something it doesn’t know how to translate into IR, it translates the offending bit of code into a UDF (user-defined function) instead.
The IR itself contains all the relational algebra operators you would expect in an RDBMS, together with a collection of linear algebra operators (e.g. matrix multiplication and convolution), higher level machine learning operators (e.g. decision trees), and ‘data featurizer’ operators (e.g. categorical encoding).
Maybe in time there will be a more declarative way of specifying the model rather than trying to recover it from an imperative program.
###Cross-optimisation
By using state-of-the-art relational and ML engines, Raven can also leverage the large body of work in relational and ML inference optimization.
Beyond the standard optimisations that exist solely in the relational or solely in the ML realm, Raven also benefits heavily from cross-IR optimisations that pass information between data and ML operators.
In predicate-based model pruning knowledge about the data flowing into the model (e.g. due to constraints in a where clause) can be used to prune the execution paths in the model. For example, removing a branch from a decision tree that we know can never be taken.
In model-projection pushdown we go the other way and use knowledge about the model (e.g., that certain features do not contribute to the prediction output) to optimise the data processing part of an inference query (by fetching only the data that will actually be used).
To create more opportunities for predicate-based pruning, we can cluster data so that each cluster has specific values for some features, and then create one optimised model per cluster (Model clustering).
Model inlining optimisations replace ML operators with relational ones, enabling use of the high performance SQL query optimiser and execution engine.
NN translation optimisations replace classical ML operators and data ‘featurizers’ with neural networks that can be executed directly in e.g. ONNX Runtime, PyTorch, or TensorFlow. "This is very important performance-wise: unlike most traditional ML frameworks, NN engines support out-of-the-box hardware acceleration through GPUs/FPGAs/NPUs as well as code generation."
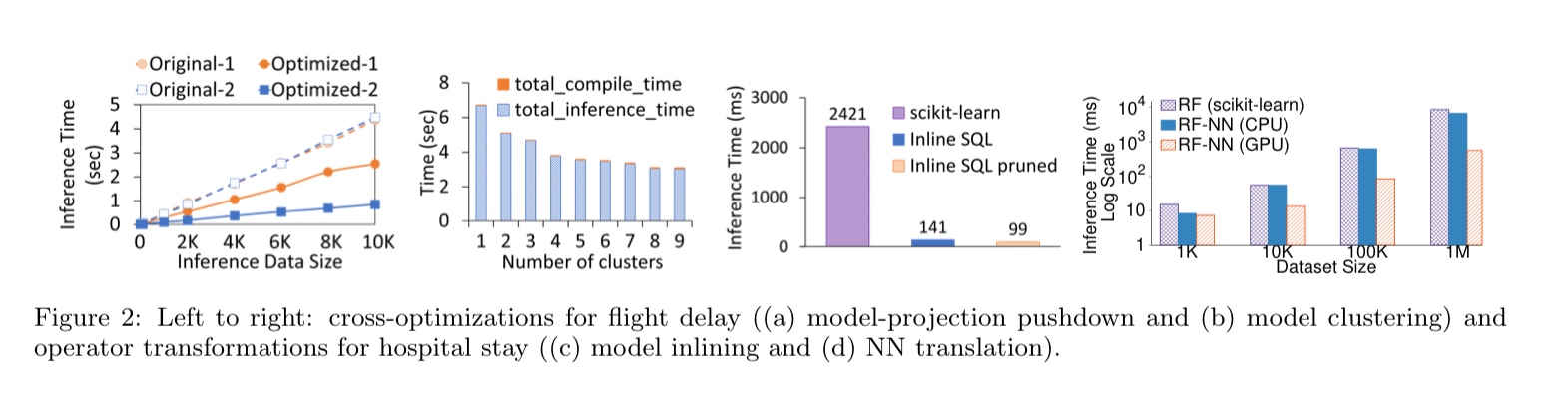
Query execution
For models that are fully supported by the static analyser, Raven supports in-process execution using the embedded ONNX Runtime.
ONNX Runtime is used as a dynamically linked library to create inference sessions, transform data to tensors, and invoke in-process predictions over any ONNX model or any model that can be expressed in ONNX through Raven’s static analysis or ONNX converters.
For model pipelines that are written in Python or R, but not supported by the static analyser, SQL Server’s external script support is used for out-of-process execution.
For model pipelines in an unsupported language, Raven falls back to containerised execution.
The following chart shows the comparative performance of Raven using the in-process ONNX Runtime execution (Raven), against Raven with external execution (Raven ext) and against a pure ONNX Runtime (ORT), for a random forest and an MLP-based model.
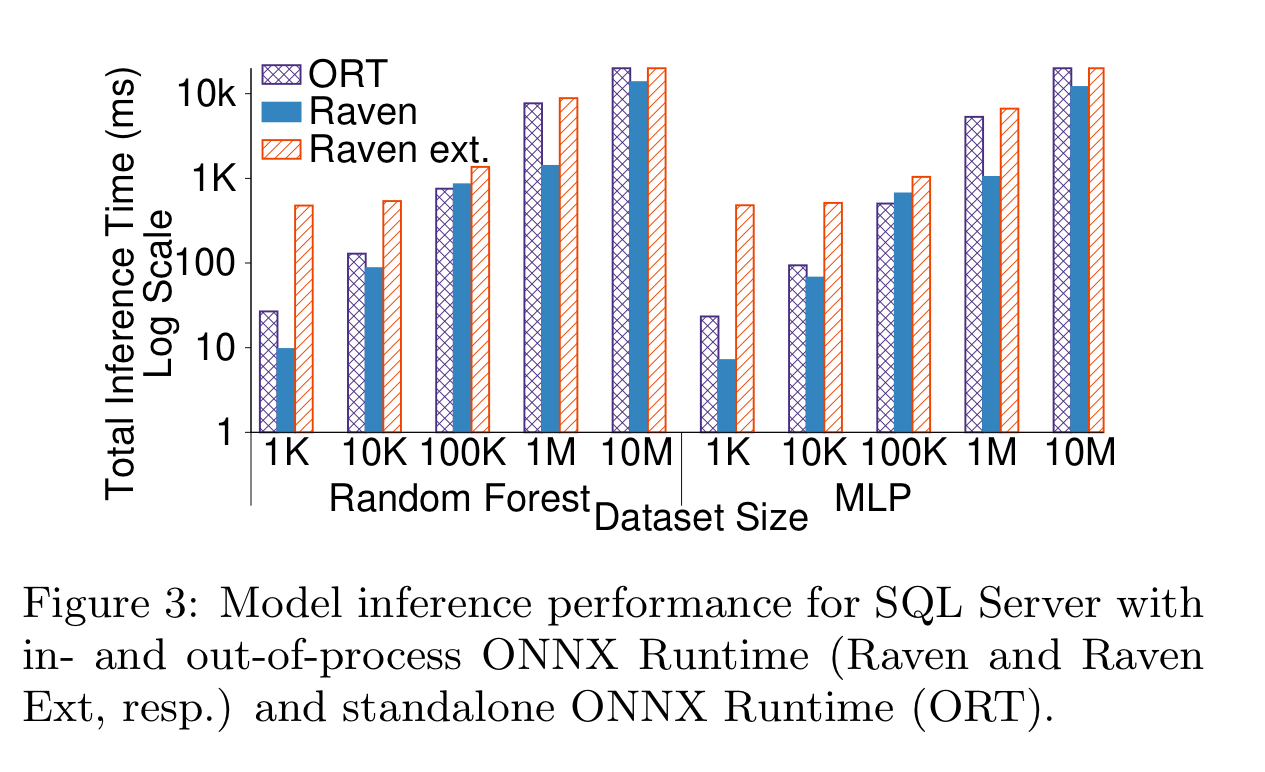
The dataset size here refers to the number of tuples for which predictions are to be made (not the size of training data). So we’re essentially evaluating batch prediction. The chart seems to show Raven outperforming at nearly all scales. There’s a band in the middle, between 50K – 100K tuples, where Raven is up to 15% slower than ORT, but as we scale up it is 5x faster with 1M to 10M tuples. This speed-up came through SQL Server automatically parallelising the scan and predict operators, as compared to the ORT sequential execution.
For single or very small numbers of predictions, Raven is faster due to SQL Server’s caching.
The last word
We are busy incorporating the techniques we present in this paper in a full-fledged cost-based optimiser – hardware acceleration and multi-query optimisation will make this even more fun.
If you want to play with these ideas for yourself, Raven’s SQL Server with integrated ONNX Runtime is currently in public preview in Azure’s SQL Database Edge.

{kind=link}
In the intro link, you say CIDR’10, but it should be CIDR’20