Cloudy with a high chance of DBMS: a 10-year prediction for enterprise-grade ML, Agrawal et al., CIDR’20
"Cloudy with a high chance of DBMS" is a fascinating vision paper from a group of experts at Microsoft, looking at the transition of machine learning from being primarily the domain of large-scale, high-volume consumer applications to being an integral part of everyday enterprise applications.
When it comes to leveraging ML in enterprise applications, especially in regulated environments, the level of scrutiny for data handling, model fairness, user privacy, and debuggability will be substantially higher than in the first wave of ML applications.
Throughout the paper, this emerging class of applications are referred to as EGML apps: Enterprise Grade Machine Learning. And there’s going to be a lot of them!
Enterprises in every industry are developing strategies for digitally transforming their businesses at every level. The core idea is to continuously monitor all aspects of the business, actively interpret the observations using advanced data analysis – including ML – and integrate the learnings into appropriate actions that improve business outcomes. We predict that in the next 10 years, hundreds of thousands of small teams will build millions of ML-infused applications – most just moderately renumerative, but with huge collective value.
EGML requirements
The authors of the paper have "extensive experience of using ML technologies in production settings" between them. The key insight this led to is that ML models are software, derived from data. ML learning systems combine the characteristics of software, e.g. the need for CI/CD pipelines, and of data, e.g. the need to track lineage. Model development itself typically represents less than 20% of most projects.
Compared to web-scale platform use of ML, enterprise applications tend to be built by smaller teams with deeper domain expertise, but less deep algorithmic or systems expertise. The platform requirements in the enterprise context, especially in regulated domains, tend to be more stringent when it comes to auditing, security, privacy, fairness and bias. Many of the software engineering discipline and controls need to be brought over into an ML context.
Typical applications of (EG)ML are built by smaller, less experienced teams, yet they have more stringent demands.
An analysis of projects on GitHub suggests that there is a broad base of ML packages out there, but also some leaders emerging. Systems aiming to support EGML therefore need to provide broad coverage, but can optimise a core set of ML packages.
In terms of feature set, we can use the experiences of leading ML companies as a guide. The following chart breaks down features in three main areas: training and auditing, serving and deployment, and data management, across six systems.

From this the authors draw two conclusions:
- Mature proprietary solutions have stronger support for data management, and
- Providing complete and usable third-party solutions is non-trivial (otherwise the cloud vendors would already have done it).
Finally, an analysis of ML research directions reveals the following arc through time: systems for training, systems for scoring, AutoML, and then responsible AI.
Lately, interest in bias, fairness and responsible use of machine learning is exploding, though only limited solutions exist… We conclude that data platforms play a key role to achieve fast and reliable training and scoring, and that explicit metadata management and provenance tracking are foundational for responsible AI and AutoML solutions.
Three big bets
Taking a step back, EGML systems need support in three main areas: model development/training, model scoring (inference) and model management/governance. Perhaps implicit in the model development/training bucket, but I think worth calling out as an important area in its own right, is the curation and management of the training data itself, as we saw last time out when we looked at Software 2.0.
Here are the three big directional bets that align with the three main areas cited by the authors:
- We will train in the cloud, where its possible to take advantage of managed infrastructure well suited to large amounts of data, spiky resource usage, and access to the latest hardware.
- Inference (scoring) engines will be deployed everywhere, and ML scoring will be deeply integrated into the DBMS "as a foundational extension of relational algebra, and an integral part of SQL query optimizers and runtimes."
- Governance will be everywhere, with "a massive need for the DB community to step up in the areas of secure data access, version management, and provenance tracking and governance."
Training in the cloud and the need for much better governance are both pretty uncontroversial directions. But model inference migrating into the DBMS is a bolder prediction. It follows from the observation that DBMSs are the natural repositories for high-value data demanding security, fine-grained access control, auditing, high availability and so on. If that’s where the data is going to live, then it follows that that’s where we’re going to want to do the scoring too. We previously looked at ‘Declarative recursive computation on an RDBMS‘ which argues for doing training there as well!
Flock
Flock is Microsoft’s reference architecture built to explore these ideas.
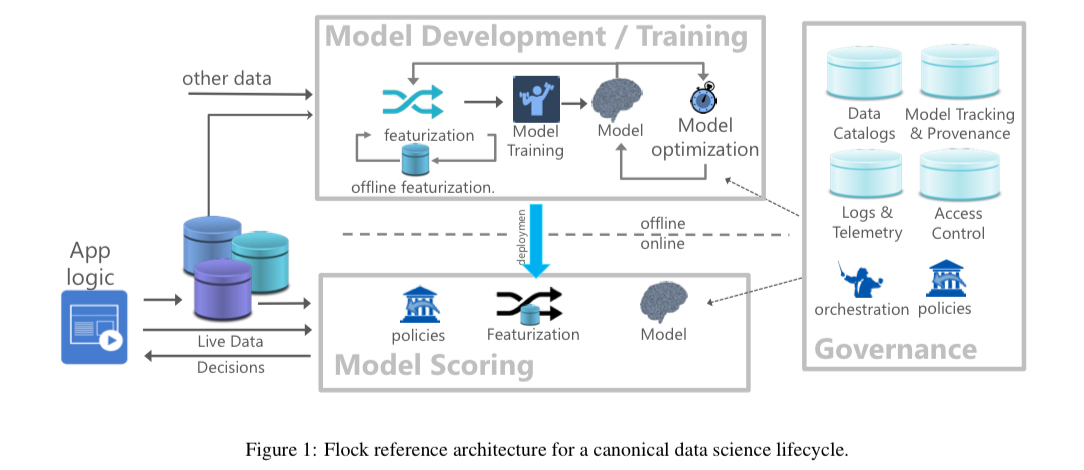
Flock treats ML models as software artefacts derived from data.
Looking at ML as software, we expect the ML and Software Engineering communities to provide us with automation, tooling, and engineering best practices – ML will become an integral part of the DevOps lifecycle. Looking at ML models as derived data, the DB community must address data discovery, access control and data sharing, curation, validation, versioning, and provenance.
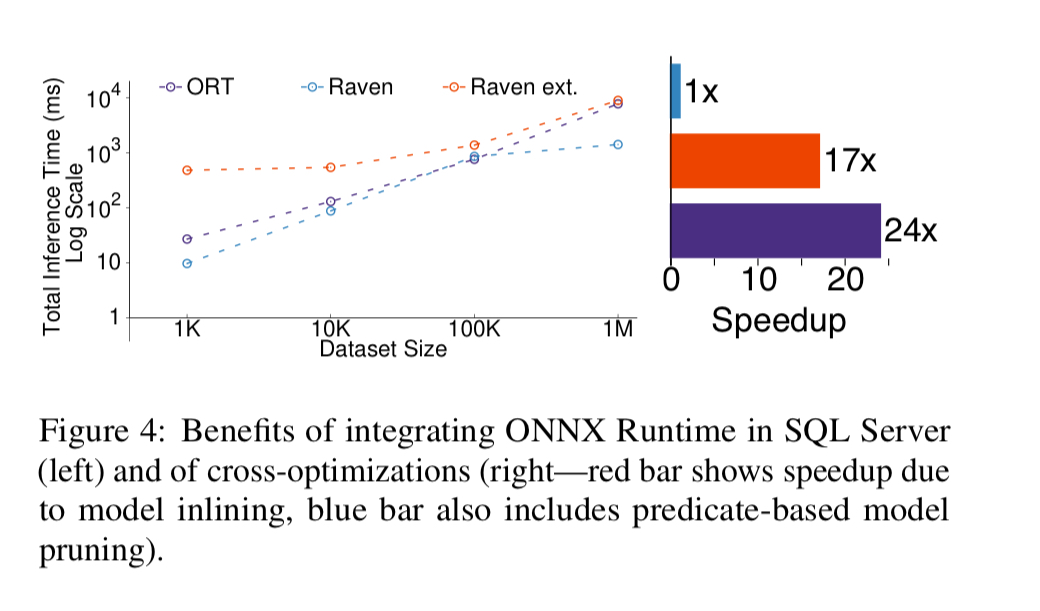
Models themselves must be subject to scrutiny with their storage and querying/scoring secured and auditable. For consistency reasons, in more complex applications transactional updates to models (and across multiple models) may be required. This is another argument in favour of in-DB scoring. A nice side-effect is that scoring in the DB can also be fast: early experiments suggest that in-DB model scoring can be up to 5x-24x faster than standalone state-of-the-art approaches.
Inference in the DBMS
Models only have value insofar as they are used for inference, to create insights and make decisions.
EGML applications will likely make use of multiple models, and you can think of each model just like a processing step in a dataflow. Thus assemblies of models might need to be updated atomically. Treating models as first-class data types in a DBMS allows database transactions to be used for model updates. Performing inference inside the DBMS for common model types, without any external calls, can then be done as an extension of relational query processing. From a processing perspective, a model is a bit like a procedure, in that it takes a bunch of inputs, performs a computation, and produces outputs. So by analogy to stored procedures, would we call models stored in the database stored models? Will we like them more than we like stored procedures?
Microsoft experimented with in-DBMBS inference by integrating the ONNX runtime in SQL Server. The results of the experiment are reported in a second CIDR’20 paper: ‘Extending relational query processing with ML inference,’ and that’s what we’ll be looking at in the next edition of The Morning Paper. So here I’ll just stick to the headline: "early results look very promising."
The output of a model is just the input to the next stage in a business process. I don’t particularly see why there’s anything special about the fact that inputs to a business process stage happen to have come from a model, but the authors see the need for a new type of policy module that helps to ‘transform the model predictions into actionable decisions in the application domain.’ Policy modules apply business constraints on top of model outputs, continuously monitoring the output of the ML models and applying the specified policies before taking any action in the application domain.
Data management
The authors analysed over 4 million notebooks in GitHub, and found to their surprise that very few of them actually make use of a database access library. I can confirm from personal experience that there are highly accomplished practitioners with a long history working in the data science and machine learning space, who have only a rudimentary knowledge of SQL. It was a surprise to me too when that penny dropped. What do these notebooks use instead? Pandas DataFrames loading from flat files.
This state-of-the-art is deeply unsatisfying: data discovery support is virtually non-existent… worse, data versioning is largely unsolved in this paradigm… more fundamentally, files are not the atomic unit of training data. Hence, we believe there is an open need for queryable data abstractions, lineage-tracking and storage technology that can cover heterogenous, versioned, and durable data.
DBMSs provide a good starting point for this, but not all data management needs to be there, so long as you have some data management.
Data versioning is the foundation, after which the need arises to track provenance information across pipelines to understand the resulting models and their predictions. In Flock, provenance is captured through three main modules:
- A catalogue based on Apache Atlas is used to store provenance information
- A SQL Provenance module captures coarse-grained provenance information from SQL queries (input tables and columns affecting the output, with connections modelled as a graph). It is built on top of Apache Calcite.
- A Python Provenance module parses python scripts and identifies lines of code corresponding to feature extraction and model training through a combination of ‘standard static analysis techniques and a knowledge base of ML APIs that we maintain.’
By connecting the outputs of the SQL Provenance module to the Python Provenance module it becomes possible to trace model lineage end-to-end.
The last word
In summary, the future is likely cloudy with a high chance of DBMS, and governance throughout.

Database is not ready to store the data of ML input and output.
Can you elaborate why?
From my point of view any relational database can store input data for ML or anything else. But for output you might need a graph database.