Migrating a privacy-safe information extraction system to a software 2.0 design, Sheng, CIDR’20
This is a comparatively short (7 pages) but very interesting paper detailing the migration of a software system to a ‘Software 2.0’ design. Software 2.0, in case you missed it, is a term coined by Andrej Karpathy to describe software in which key components are implemented by neural networks. Since we’ve recently spent quite a bit of time looking at the situations where interpretable models and simple rules are highly desirable, this case study makes a nice counterpoint: it describes a system that started out with hand-written rules, which then over time grew complex and hard to maintain until meaningful progress had pretty much slowed to a halt. (A set of rules that complex wouldn’t have been great from the perspective of interpretability either). Replacing these rules with a machine learned component dramatically simplified the code base (45 Kloc deleted) and set the system back onto a growth and improvement trajectory.
A really interesting thing happens when you go from developing a Software 1.0 (i.e., traditional software) to a Software 2.0 system. In Software 1.0 we spend the majority of our effort on writing code, expressing how the system achieves its goals. Our whole tool chains are geared around the creation and validation of that logic. But in Software 2.0 the majority of our effort goes into curating training data, i.e., specification-by-example of what the system should do. We need a whole new tool chain geared around the creation/curation and validation of that data.
The particular system discussed in this paper is Google’s email information extraction system. This learns templates for business-to-consumer emails and then uses those templates to extract information such as order numbers, travel dates, and so on. The existing system was based on a rule-based architecture with hand-crafted rules and had been in production since 2013. Prior to the replacement, "the coverage of the heuristic-based extraction system had been flat for several months since it was too brittle to improve without introducing erroneous extractions."
Switching to a Software 2.0 design delivered Google four main benefits:
- Precision and recall quickly surpassed the results from the heuristics-based system
- Google were able to delete about 45K lines of code, greatly reducing the code footprint.
- The new system is much easier to maintain – the hand-written rules had become brittle and made it difficult to debug errors and make any further improvements to accuracy.
- It opened the door to whole new possibilities that could not have been considered before – chief of these is the integration of cross-language word-embeddings to learn information extraction models that work across several languages (the original system only worked for English).
The biggest challenges we encountered during this migration were in generating and managing training data.
In the Software 1.0 system, the biggest challenges were in generating and managing hand-written rules. But in Software 2.0, (training) data is key. In this particular case there’s in interesting twist: the corpus of emails that the system has to operate over is private. I.e., Google engineers don’t have access to them.
Detecting low quality training data from low-precision rules and improving data quality over time is critical. Developing these in the context of a privacy-safe system where no one can visually inspect the underlying data is particularly challenging.
Background on Juicer
Google’s system for extracting structured information from unstructured emails is called Juicer. Juicer clusters together emails that share a similar structure (using a locality sensitive hash of the set of XPaths that make up the HTML DOM tree of an email), and then using a set of pre-trained vertical classifiers to decide what kind of email (e.g. order confirmation, travel reservation) the cluster represents. The label assigned by this classifier determines what kind of field information Juicer will try to extract from the email (e.g., an order number if this email cluster has been classified as order confirmation). From the cluster therefore, a template of the emails in that cluster is formed.
The original system (in production since 2013) using hand-written rules for field extraction, developed over many years.
In the Software 2.0 approach, the extraction rules are machine-learned. Each field has a corresponding field classifier which is applied to a set of candidates in the email to identify the target field value.
A library of annotators are used to annotate dates, email addresses, numbers, prices, and so on in the email text. A candidate for field extraction is any span of text with an annotation of the appropriate type (e.g., a date, if you’re looking for a delivery date field value). Field classifiers are trained (per template) to predict whether a given candidate corresponds to a given field in the vertical. The classifier scores are averaged across all emails in the cluster for which the XPath is observed. If the average score is greater than a pre-determined threshold, then an extraction rule is added to the template for that XPath.
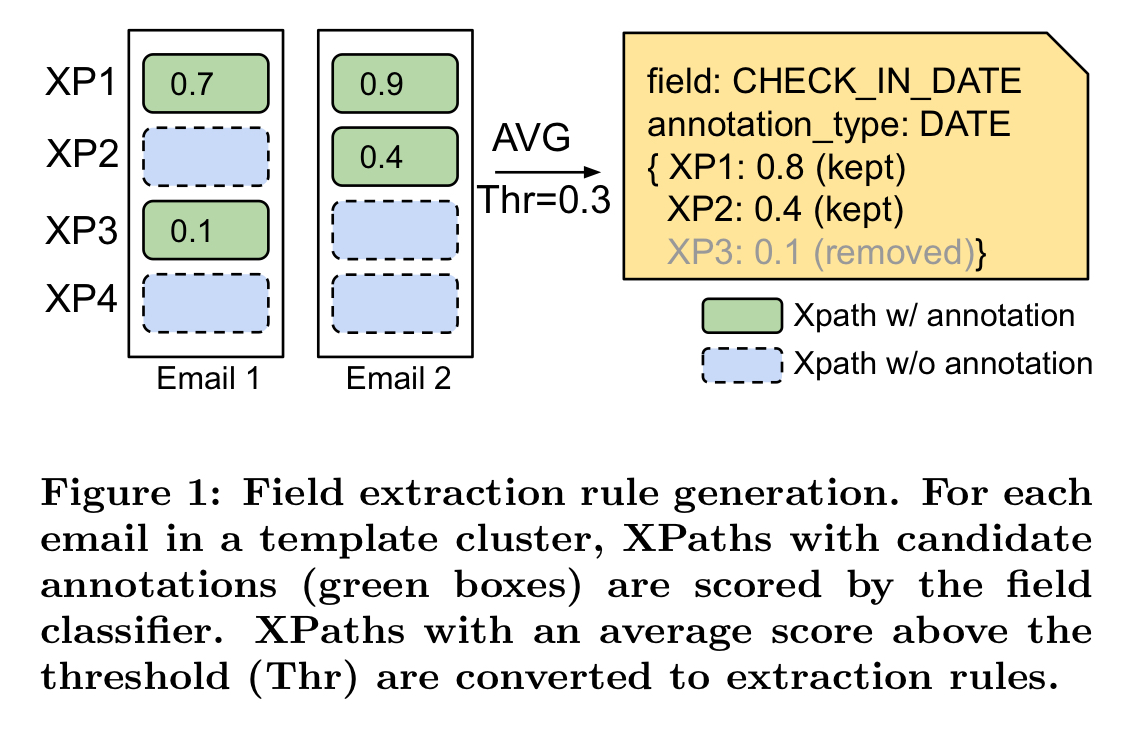
At runtime when a new email arrives Juicer looks up the appropriate template based on the hash of the XPaths, and then applies any extraction rules for that template.
Extractions are evaluated by inspecting synthetic emails generated from the underlying templates and highlighting the results from either the legacy system or machine learned rules. Since email data is private no-one has access to visually inspect any real data. Instead, emails are synthetically generated from the text of the templates that pass the k-anonymity constraints.
Managing training data
The very first trained models were only able to replace 6% of the extractions made by the previous heuristic rules. Closing this gap was all about managing the training data. If you can’t inspect real emails for that purpose, then the next best thing is to generate your own synthetic emails. A CandidateGenerator is given an annotated email and returns a collection of candidates to be used in model training or inference for field rule generation. CandidateLabelers then implement logic to label each candidate as positive, negative, or unknown for use in model training (e.g. by comparing the annotated value to the known ground truth used to construct the email in the first place).
Given the private nature of emails, it is particularly difficult to gain insights into the quality of candidate generation or labeling logic if one cannot actually view the results over a real email sample.
To address this, a set of counter metrics are computed for every field extractor. By examining these counters (e.g., the number of emails ignored due to having only negative labels) the developers can quickly pinpoint issues without needing to understanding the details of the particular field in question.

Only high-confidence results are allowed into the training data. Classifiers trained on data with low-quality examples excluded performed better than those that included it.
Using the counter metrics, it is possible to identify cases where hand-written rules can successfully extract, but the ML system cannot. These areas can then be targeted for improvement.
Once field extraction rules have been generated for a template, synthetically generated emails are created for that template, run through the extractors, and then human assessors verify the vertical label and field extraction. "These assessments are rather cheap, since they only require a yes/no answer to questions such as ‘Is this a hotel confirmation?’, ‘Is the correct check-in date extracted?’, etc."
Results
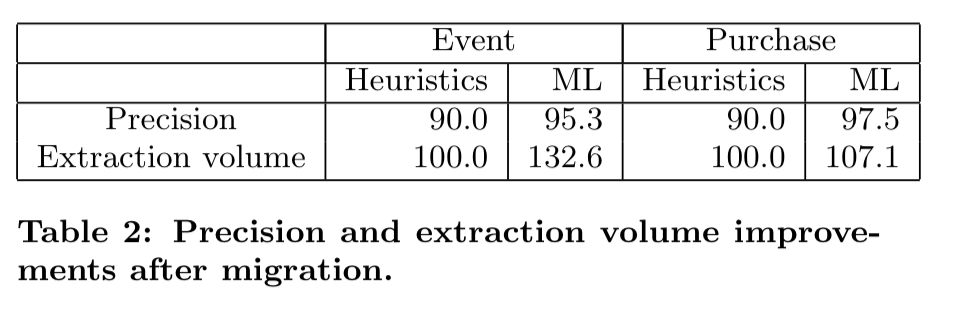
We covered the headline results earlier in this post. Within a few weeks following the processes outlined above, the ML system had begun to outperform the hand-written rules with years of development behind them. For example, the ML models discovered additional templates and rules resulting in a 32.6% increase in volume of extractions for events.
Our work reinforces the argument that a critical ingredient of a Software 2.0 approach for the real-world is managing training data. In contrast to solving a de-novo extraction problem, we focus on replacing a complex heuristics-based production extraction system with a completely machine-learned system that is easy to understand and improve. We argue that a key component for any such effort is a system to manage training data – including acquiring, debugging, versioning, and transforming it. (Emphasis mine).

It’s very interesting paper. Everything is new, but nothing is.
In software 1.0 we had to collect and organize requirements that developers will use to “generate” a program. In software 2.0 requirements are prepared in machine-friendly form, so machine could generate a program without a human.
Requirements a.k.a. training data keeps to be a key to the working software. And the learning is still here yet automated similar to the mainstream agile as the way to use feedback loop while experimenting. Truly we’re getting into automated program generation!
Thanks!
The name “Software 2.0” was a poor choice on the part of Karpathy, and even he sort of admits it himself (https://youtu.be/zywIvINSlaI?t=688). A better name could have been “Software for AI, 2.0”, as this new way of generating software really only applies to rule or heuristic based problems, and not general software problems, e.g. Video games, web servers, Android apps to view the weather, etc.
Leaving the name aside, I think this is a great development that’s starting to take shape. It seems to me that wherever in code we used to have rules or heuristic based engines to generate an objective function, these can now be replaced with neural nets to achieve greater results.
One possible application I can see for this would be in machine code optimization in programming language compilation. Given an intermediate representation for some computer program (LLVM IR, Java Bytecode, etc.), use a neural network to output optimized architecture specific code based on some objective function (minimize instruction count, instruction throughput, etc.)
I do agree with you on this point. because in recent development circumstances。 we can generating routine code from template by leverage heuristic AI models