Trade-offs under pressure: heuristics and observations of teams resolving internet service outages, Allspaw, Masters thesis, Lund University 2015
This is part 2 of our look at Allspaw’s 2015 master thesis (here’s part 1). Today we’ll be digging into the analysis of an incident that took place at Etsy on December 4th, 2014.
- 1:00pm Eastern Standard Time the Personalisation / Homepage Team for Etsy are in a conference room kicking off a lunch-and-learn session on the personalised feed feature on the Etsy.com homepage
- 1:06pm reports of the personalised homepage having issues start appearing from multiple sources. Instead of the personalised feed, the site has fallen back to serving a generic ‘trending items’ feed. This is a big deal during the important holiday shopping season. Members of the team begin diagnosing the issue using the #sysops and #warroom internal IRC channels.
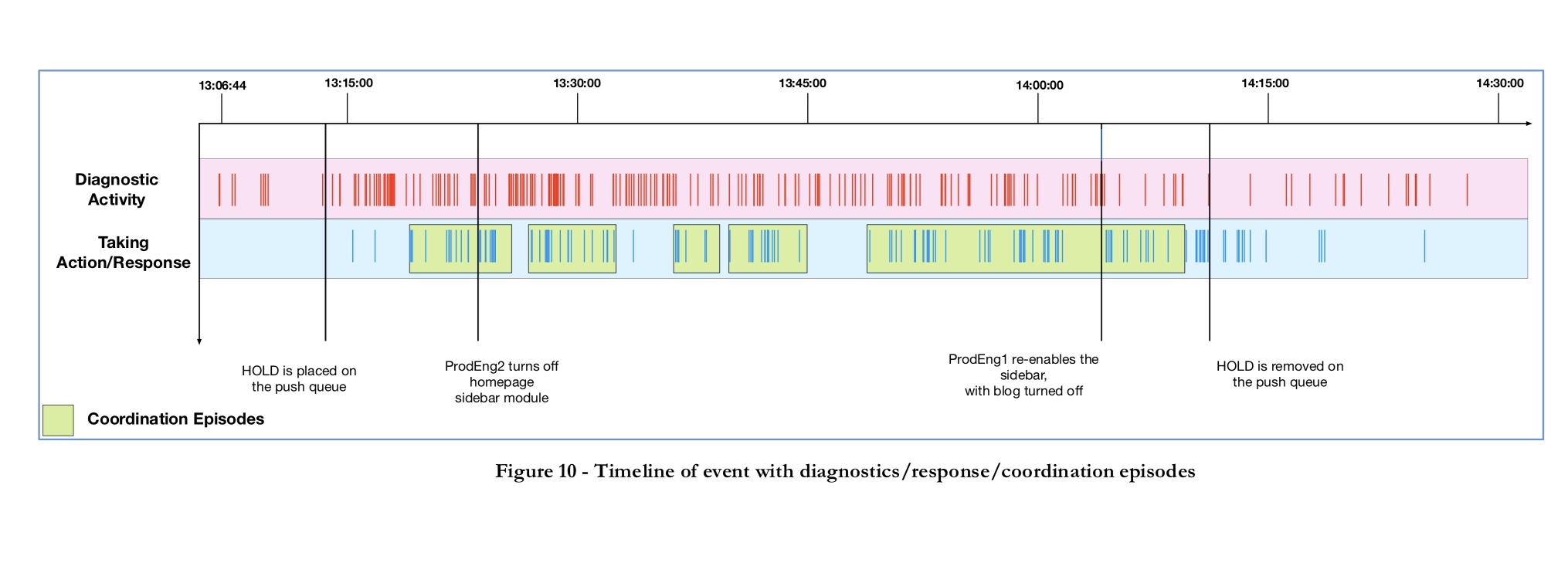
- 1:18pm a key observation was made that an API call to populate the homepage sidebar saw a huge jump in latency
- 1:28pm an engineer reported that the profile of errors for a specific API method matched the pattern of sidebar errors
- 1:32pm the API errors were narrowed down to requests for data on a specific single shop. The shop had been closed so no data was available.
- 1:36pm it was discovered that this shop was linked to from the Etsy blog post, via an article posted by the Etsy employee that owned the shop. The blog post was subsequently unpublished.
- Between 2:00pm and 2:15pm the sidebar is re-enabled with the blog turned off, and the temporary HOLD on new deploys is removed.

With service restored, the team kept the sidebar module "more from the blog" turned off overnight to give time to change the underlying code to gracefully handle 400 errors by caching them (the big slowdown came because the 400 errors for the missing shop data bypassed the caching mechanism, causing a full request to be made on every page load).
With only an hour or so of degraded performance in the end, it’s not the worst incident you can imagine, but it was clearly taken as very serious given the time of year.
Recall though that we’re not really here to analyse the incident itself, but what happened within the team handling the incident.
In this study, the diagnosis and resolution of an outage in a global Internet service, Etsy.com, was explored in an effort to uncover which cognitive strategies (specifically, heuristics) are used by engineers as they work to bring the service back to a stable state.
A technique called process tracing was employed to try and recover "a record of participant data acquisition, situation assessment, knowledge activation, expectations, intentions, and actions as the case unfolds over time." Five infrastructure engineers and 3 product engineers were involved in the incident. The process tracing exercise included:
- Examning IRC transcripts from multiple channels
- Accessing logs of the dashboards and graphs engineers looked at during the outage
- Gathering timestapms of changes made to application code during the outage
- Capturing logs af any alerts that triggered during the outage
- Semi-structured interviews using cued-recall.
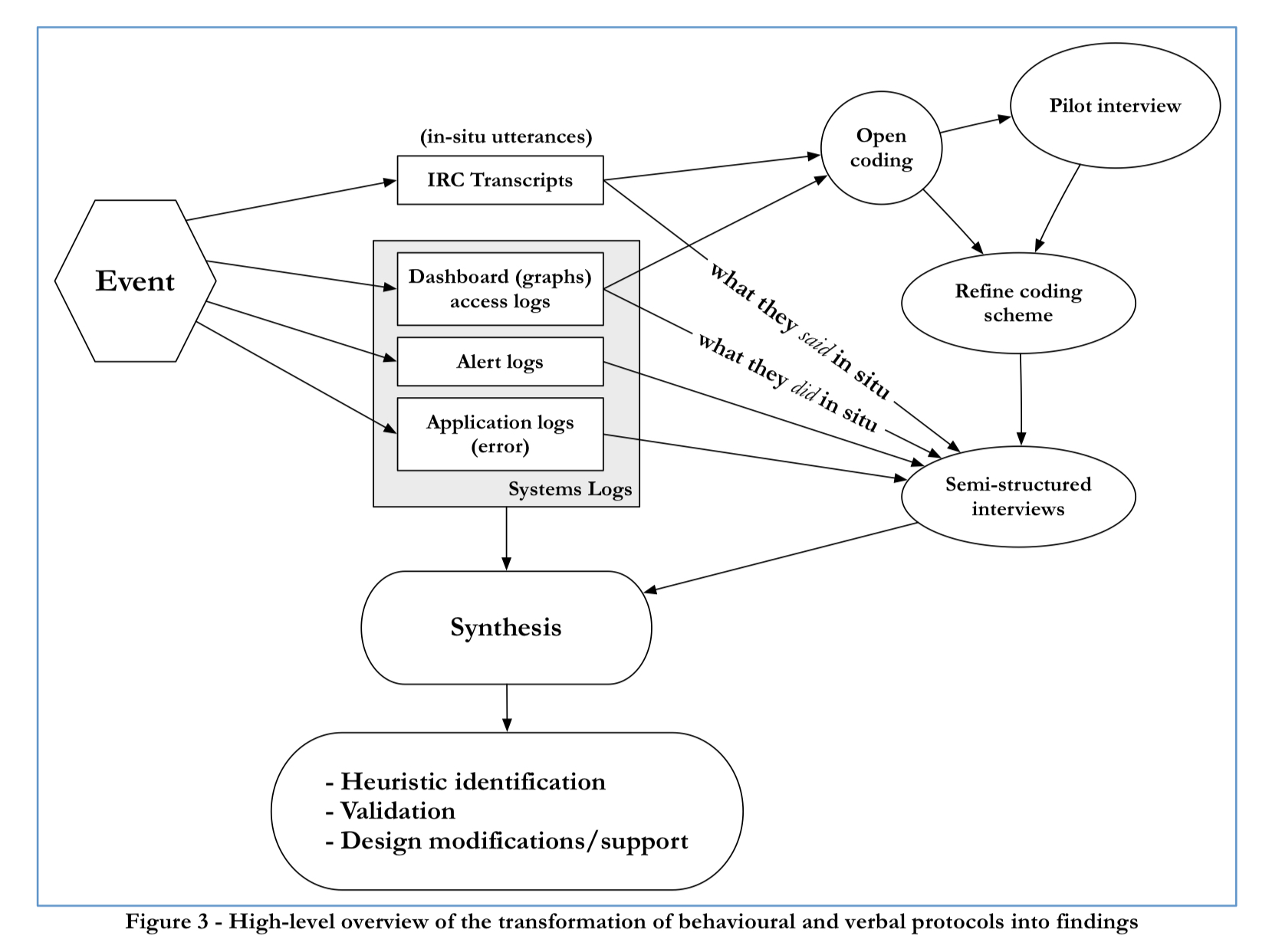
Event analysis
A coded timelime was created dividing activities into three main types:
- Coordination activities
- Diagnastic activities
- Disturbance management activities
The following chart shows the big picture, with five key coordination episodes identified.
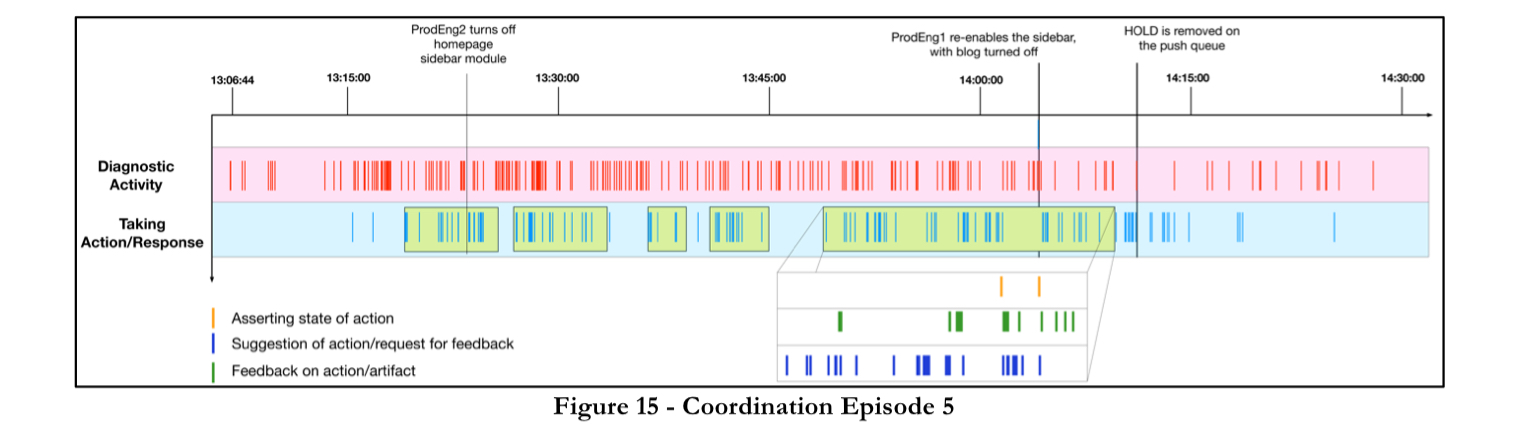
Coordination episodes:
- At 1:19pm, a discussion as to whether or not the sidebar portion of the homepage should be turned off
- At 1:24pm, a discussion as to whether the cause might be a ‘featured shop’
- At 1:36pm, a switch in hypothesis from the ‘featured shop’ module to the ‘more from the blog’ module
- At ~1:40pm, a member of the blog infrastructure team is invited to join the warroom and the decision is taken to unpublish the blog post
- At 1:49pm, a discussion on renabling the sidebar with the ‘more from the blog’ module turned off.
There are detailed breakdowns of each of these coordination episodes with visual timelines such as this one:
Throughout the incident there were five different hypotheses generated, shared, and discussed. Interwoven with the diagnosis and coordination activities the team were also actively engaged in disturbance management.
Almost all of the activities were aimed at reducing the untoward effects of the degradation and stabilization of the site’s functionality, as opposed to immediately focusing on full recovery.
Peer consensus was the primary mechanism used to decide whether to take actions affecting the production systems, and on two occassions changes were pushed through without waiting for automated tests to complete.
Out of the analysis, four heuristics emerged that the team were using to manage the incident.
- First look for any correlation to the last change made to the system
- If no correlated change is implicated, then widen the diagnostic search space to any potential signals
- When forming hypotheses and evaluating diagnostic directions, use pattern matching of signals or symptoms to either specific past events or recent events.
- During incident management, prefer peer review of any code changes to gain confidence as opposed to automated tests or other procedures.
(There’s much more colour around these in the full thesis report of course).
Given the heuristics that have been identified, an interpretation of the diagnostic activity is that it demonstrates that abduction is the primary mode of reasoning in events such as these.
"Abductive reasoning (also called abduction, abductive inference, or retroduction) is a form of logical inference which starts with an observation or set of observations then seeks to find the simplest and most likely explanation for the observations." – wikipedia.
Diagnostic searches followed anomaly recognition in a cyclical pattern, with all externalized hypotheses followed by an anomaly detection search to refute or confirm them. Monitoring for success also followed each corrective response action.
The last word
In fields such as software operations, it can be too easy to assume that the success of business-critical systems are owed solely to the speed, algorithmic prowess, and preventative design of automation. This study joins many others in the fields of human factors, cognitive systems engineering, and systems safety that not only provide ample falsification of this perspective, but asserts a different view: that the greatest sources of success in automation-rich environments are (perhaps ironically) the adaptive capacities of human cognition and activity, not the pseudo-intelligence of the software. (Emphasis mine).

One thought on “Trade-offs under pressure: heuristics and observations of teams resolving internet service outages (Part II)”
Comments are closed.