Reverb: speculative debugging for web applications, Netravali & Mickens, SOCC’19
This week we’ll be looking at a selection of papers from the 2019 edition of the ACM Symposium of Cloud Computing (SoCC). First up is Reverb, which won a best paper award for its record and replay debugging framework that accommodates speculative edits (i.e., candidate bug-fixes) during replay. In the context of the papers we’ve been looking at recently, and for a constrained environment, Reverb is helping its users to form an accurate mental model of the system state, and to form and evaluate hypotheses in-situ.
Reverb has three features which enable a fundamentally more powerful debugging experience. First, Reverb tracks precise value provenance, allowing a developer to quickly identify the reads and writes to JavaScript state that affected a particular variable’s value. Second, Reverb enables speculative bug fix analysis… Third, Reverb supports wide-area debugging for applications whose server-side components use event-driven architectures.
The problem
Reverb’s goal is to aid in debugging the client-side of JavaScript web applications. These are "pervasively asynchronous and event-driven" which makes it notoriously difficult to figure out what’s going on. See e.g. "Debugging data flows in reactive programs."
Logging and replay of exactly what happened during an execution requires some kind of interception framework but is conceptually straightforward. But what you should ‘replay’ after a speculative edit has been made? Some prior events may no longer be appropriate, and some new events may need to be fabricated.
The speculative edit-and-debugging experience supported by Reverb has five phases:
- Logging events in a baseline execution run
- Replaying the execution up to a specified point
- Changing the program’s state in some way
- Resuming execution, with nondeterminism from the original run "influencing" the post-edit execution; and
- Comparing the behaviour of the original and altered runs to understand the effects of the speculative fix.
The non-deterministic input vectors for a JavaScript program are well-known and (compared to POSIX) very small in number. However, defining post-edit replay semantics was previously an unsolved problem…
Reverb’s high-level approach
Reverb injects record-and-replay components on the client-side (in browser), as well as on server-side JavaScript (i.e. Node) applications and black-box single-threaded event-driven applications (currently just Redis in the prototype).
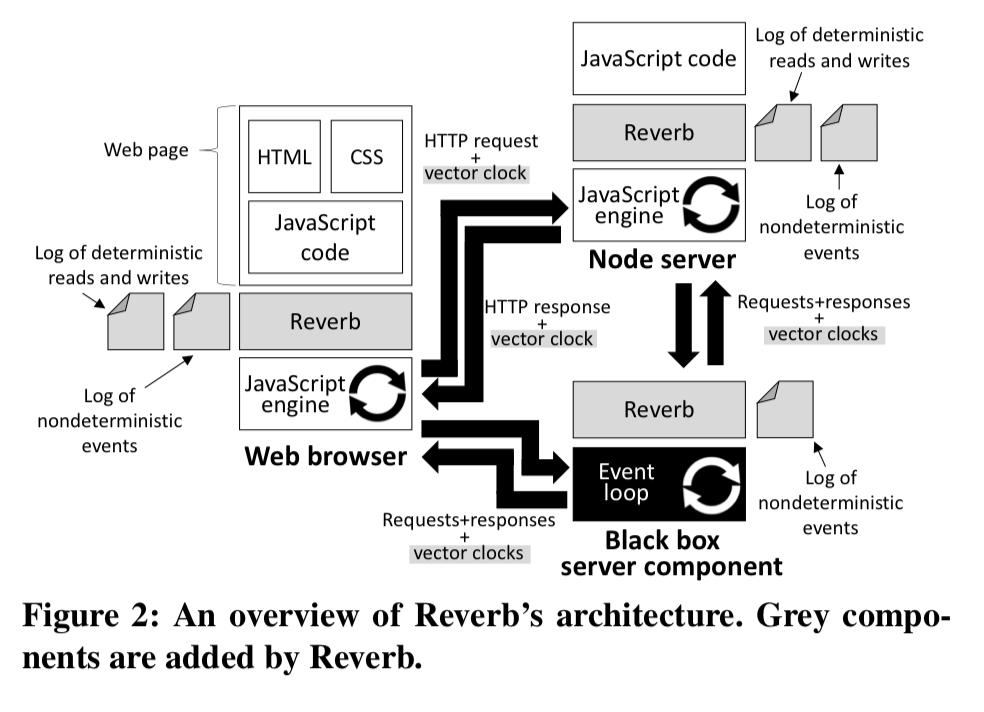
Both server-side and client-side components are assumed to be single-threaded and event-driven. Each component records its nondeterministic events; if a component uses a JavaScript engine, then the component also records its deterministic reads and writes to JavaScript state and the DOM. Distributed causality between hosts e.g. via HTTP requests, is tracked using vector clocks.
Within the browser Reverb rewrites JavaScript code to inject instrumentation that runs during each read or write to JavaScript or DOM state, as well al logging nondeterministic events such as mouse clicks and timer firings. Reverb also take a snapshot of the client’s local storage (e.g. cookies) at the start of logging. Given the read and write logs, Reverb can construct the provenance of all variables in the program.
Within server-side Node applications Reverb modifies the HTTP request handler to extract a client vector clock (sent by rewritten JavaScript on the client side) and update the server’s vector clock appropriately. The server’s updated clock is transmitted to the client via a Set-Cookie header on the response. For Redis, Reverb does a similar thing via a proxy.
Given the recorded logs, it is possible to replay them exactly. The fun starts though, when a programmer pauses execution, makes a change, and then resumes. What values should the new program see now? Consider client-side calls to non-deterministic functions such as Math.random() or Date(). The new code may make fewer, the same, or more calls to such functions depending on the branches explored.
- If the post-edit code makes fewer calls then we use return values from the log, and once the call-chain finishes skip forward to the first return value first seen by the next invocation of the event handler in the original execution.
- If the post-edit code contains more calls than function-specific extrapolation is used to generate additional values – e.g. new random numbers for
Math.random()and monotonically increasing time values forDate()that are smaller than the next logged value.
Furthermore, if the edit results in the deletion of a timer or DOM hander, all subsequent events for the timer/DOM handler are marked as ‘do not replay.’ If XMLHTTPRequests or WebSockets are closed then any future events involving those connections are closed.
If the edit creates a new, unlogged network request, then the replay framework must inject new network events into the log. If the server-side responder is also being replayed, then Reverb inserts a new request into the server-side log… When the response is generated, Reverb buffers it and uses a model of network latency to determine where to inject the response into the client-side log.
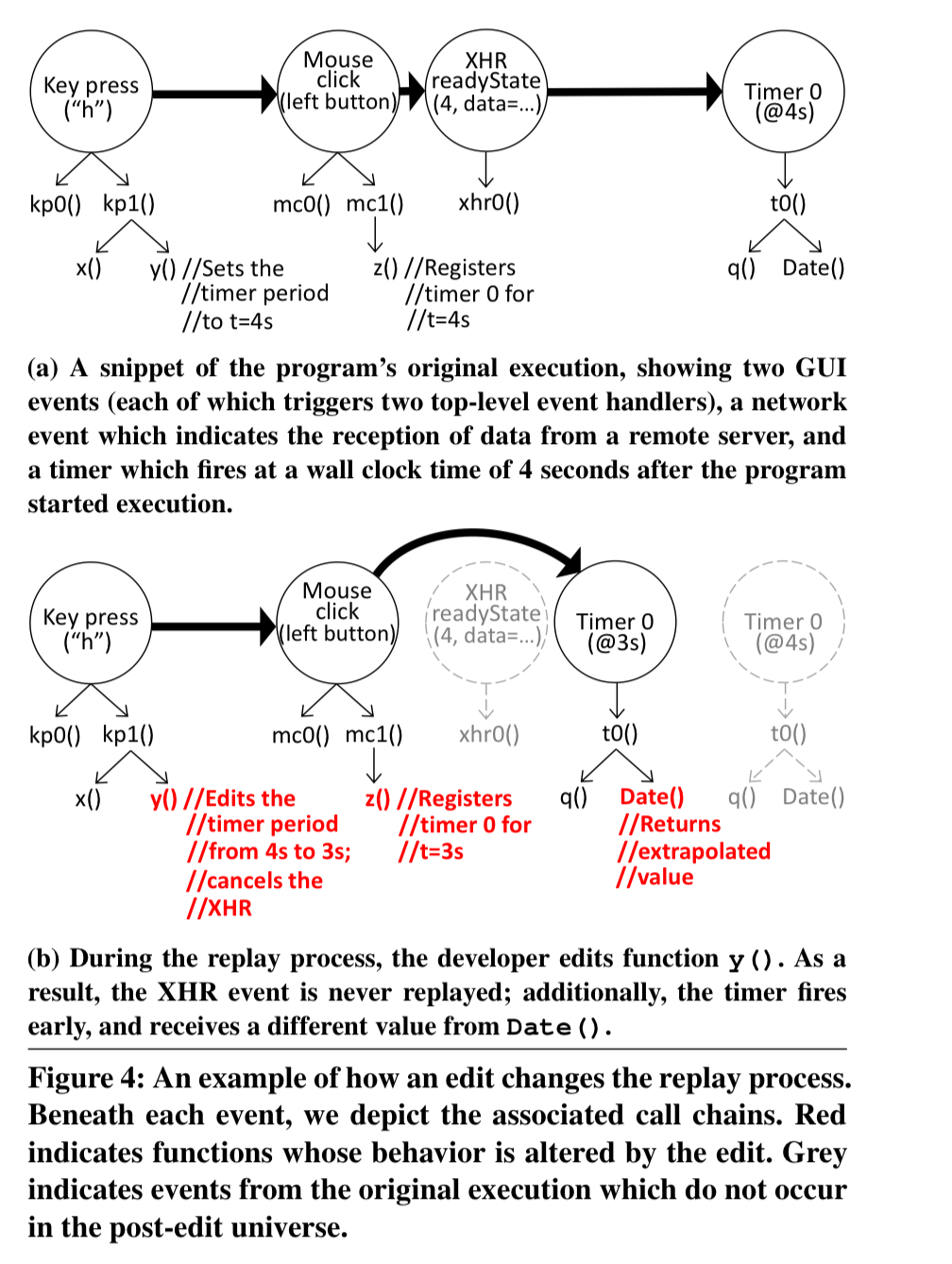
Reverb also allows a developer to modify server-side responses, uses similar techniques to those just discussed to handle divergent scenarios.
Is that really feasible?
Intuition might suggest that tracking all deterministic and nondeterministic events would produce huge logs. However, in the Alexa Top 300 pages, the median number of reads and writes that occur during page load are 13,275 and 6,328 respectively. Those numbers are surprisingly low, given the fact that an average web page includes 401 KB of JavaScript source code…
Implementation details
Reverb uses a modified version of Scout to log reads and writes to the JavaScript heap and DOM. Scout is extended to also log nondeterministic events such as mouse clicks and timer firings. The NEATO visualisation library is used to display data flow graphs.
During replay Reverb uses Mahimahi to serve browser-side content, and the MetaES JavaScript interpreter to support speculative edit-and-continue.
Evaluation
Across the top 300 Alexa sites the gzipped logs have a median size of 45.4 KB (95%-ile size 113.2 KB), and it takes 7.8 seconds on average to generate a full data-flow graph. The client-side instrumentation only slows down the median page load by 5.5%.
The paper contains a case study of the authors debugging EtherCalc using Reverb. The following figure shows an annotated wide-area debugging session using the tool:
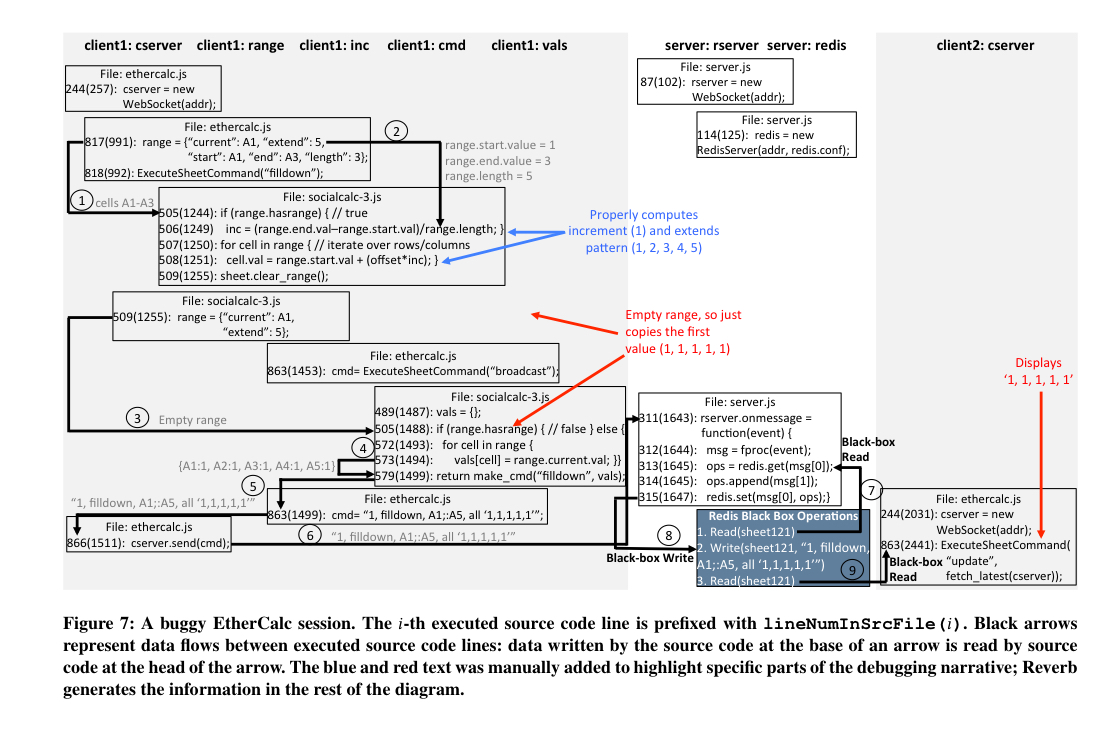
The authors were able to find the source of the bug, supply a speculative bug fix, and verify that it worked.
Reverb was also successfully used to recreate five historic jQuery bugs from the public bug database, and verify the known-good fix using speculative replay.
Of course you’d hope the authors were able to use their own tool effectively! The evaluation also includes a small study with six front-end web developers asked to debug a problem in a web app. Three users used Reverb, and three used traditional debugging. The Reverb users were faster at debugging the problem (all within 10 minutes, two within 5) than the non-Reverb users (two between 5 and 10 minutes, one failing to find the bug within 10 minutes).
It’s a small sample, but they liked it:
When asked, "Would Reverb-style data flow operations be a useful compliment to standard debugging primitives?", all six participants said yes. Furthermore, all three Reverb users declared, without prompting, that speculative edit-and-continue would be a powerful debugging technique.

4 thoughts on “Reverb: speculative debugging for web applications”
Comments are closed.