PlanAlyzer: assessing threats to the validity of online experiments Tosch et al., OOPSLA’19
It’s easy to make experimental design mistakes that invalidate your online controlled experiments. At an organisation like Facebook (who kindly supplied the corpus of experiments used in this study), the state of art is to have a pool of experts carefully review all experiments. PlanAlyzer acts a bit like a linter for online experiment designs, where those designs are specified in the PlanOut language.
We present the first approach for statically checking the internal validity of online experiments. Our checks are based on well-known problems that arise in experimental design and causal inference… PlanAlyzer checks PlanOut programs for a variety of threats to internal validity, including failures of randomization, treatment assignment, and causal sufficiency.
As well as pointing out any bugs in the experiment design, PlanAlyzer will also output a set of contrasts — comparisons that you can safely make given the design of the experiment. Hopefully the comparison you wanted to make when you set up the experiment is in that set!
Experimental design with PlanOut
PlanOut is a open source framework for online field experiments, developed by and extensively used at Facebook. To quote from the project page, “PlanOut … was created to make it easy to run and iterate on sophisticated experiments in a statistically sound manner while satisfying the constraints of deployed Internet services.” The paper ‘Designing and deploying online field experiments’ (Bakshy 2014) describes the language and its usage at Facebook (one for The Morning Paper backlog?).
PlanOut itself has been ported many programming languages at this point. Its core role is to provide randomised parameter values (the values to be used during the execution of an experiment) to runtime services:
PlanOut provides randomized parameter values to Internet services. Instead of using constants for user interface elements or switches controlling the rollout of a new feature or ranking model, just use PlanOut to determine the value of these parameters. Now you have an experiment. (PlanOut project page)
Defining an experiment looks like this:
class MyExperiment(SimpleExperiment):
def assign(self, params, userid):
params.button_color = UniformChoice(
choices=['#ff0000', '#00ff00'],
unit=userid)
params.button_text = UniformChoice(
choices=['I voted', 'I am a voter'],
unit=userid)
And in your application code you would interact with PlanOut like this:
my_exp = MyExperiment(userid=42)
color = my_exp.get('button_color')
text = my_exp.get('button_text')
We have spoken with data scientists and software engineers at several firms that use PlanOut, and they have stated that the mapping from experiments to samples was what drew them to the PlanOut framework. The mapping avoids clashes between concurrently running experiments, which is one of the primary challenges of online experimentation.
What can go wrong in experiment design?
Regular readers of The Morning Paper will be well aware that there’s plenty that can go wrong in the design and interpretation of online controlled experiments (see e.g. ‘A dirty dozen: twelve common metric interpretation pitfalls in online controlled experiments’) . PlanAnalyzer is aimed at detecting threats to internal validity, the degree to which valid causal conclusions can (or cannot!) be drawn from a study.
Three of the most serious threats to validity in causal inference are selection bias, confounding, and a lack of positivity.
- Selection bias occurs when the sample chosen for treatment and analysis in the experiment differs in a systematic way from the underlying population. It can occur due to non-proportional sampling (sampling from a sub-group that does not resemble the population), dropout (aka attrition) where data is lost before recording results, and failing to properly randomise the mapping from subjects to treatments. PlanAlyzer can catch selection bias bugs in this latter category.
- Confounding occurs when there is a variable that causes both treatment and outcome. Fully randomised treatment assignment ensures that there are no confounding variables. When a fully randomised experiment isn’t possible or desirable, random assignment can be conditioned on some feature of the unit under test. This can introduce confounding, and requires that the feature that influenced assignment be recorded. PlanAlyzer can check for this.
- Lack of positivity occurs when your sample contains no instances from a subgroup. To be able to correct for this, the situation must first be detected. PlanAlzer can check for lack of positivity.
How PlanAlyzer works
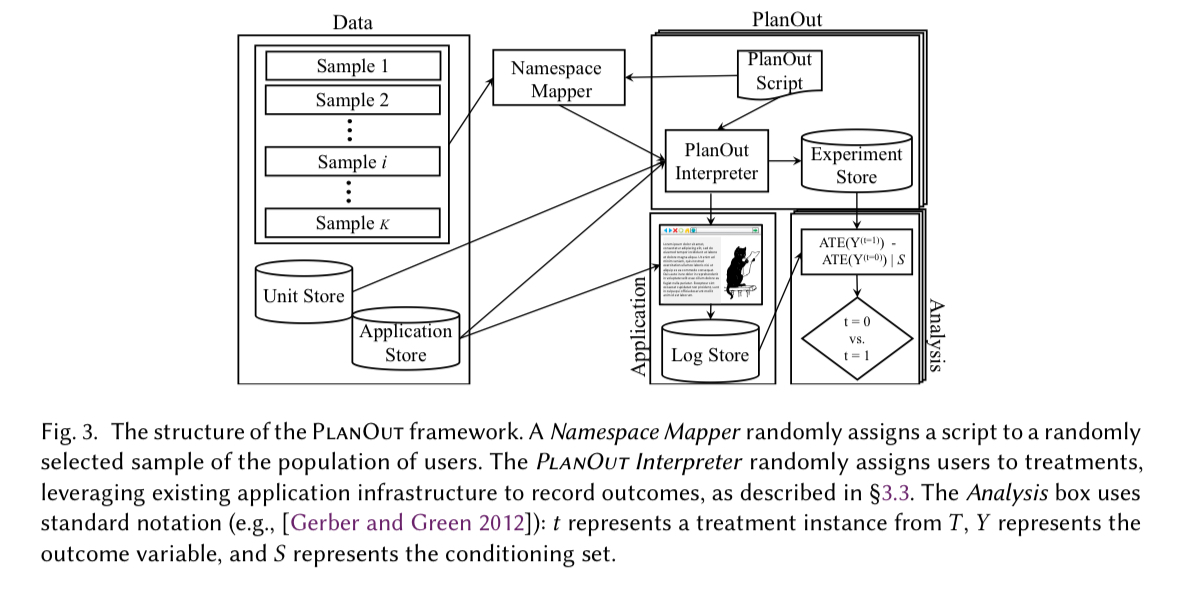
PlanAlyzer is a command line tool for checking PlanOut programs.
PlanAlyzer (1) checks whether the input script represents a randomized experiment by validating the presence of random assignment and the absence of any failures related to selection bias, unrecorded cofounders, or positivity; and (2) generates all valid contrasts and their associated conditioning sets for the ATE estimator.
ATE here stands for average treatment effect, i.e. the thing we would like to measure. Sometimes we need to condition on variables in order to be able to safely estimate treatment effect, in which case we have CATE: the conditional average treatment effect.
Here’s an example of the contrast output generated by PlanAlyzer:
Conditioning set: {}
============
Avg(Y|dynamic_policy=true) - Avg(Y|dynamic_policy=false)
Conditioning set:
{emerging_market : true}
============
Avg(Y|max_bitrate=400, dynamic_policy=false) -
Avg(Y|max_bitrate=750, dynamic_policy=false)
Conditioning set:
{emerging_market : false; established_market : true}
============
Avg(Y|max_bitrate=400, dynamic_policy=false) -
Avg(Y|max_bitrate=750, dynamic_policy=false)
By convention, Y is used to represent the outcome of interest (number of videos watched in the experiment above). The contrast output above tells us for example that we can safely measure the impact of a dynamic bitrate policy across the board, but we need to much more careful if we want to start analysing the impact based on market or maximum available bitrate. To translate that into understandable terms for this particular experiment:
Whether a user is in an emerging market or an established market determines their probability of being assigned the high or low bit rate, but the market may also have an influence on the average percentage of videos watched (Y). Therefore, naively aggregating over the high and low bit rates for the country-based experiment would not be correct.
In addition to a PlanOut program you can optionally supply PlanOut with additional inputs specifying external sources of randomness, the cardinality of variables’ domains, and whether variables are constant or time-varying. If you don’t supply this information, PlanAlyzer will try to infer it (conservatively).
Under the covers, PlanAlyzer builds a data-dependence graph for a PlanOut program and uses this to propagate variable label information.
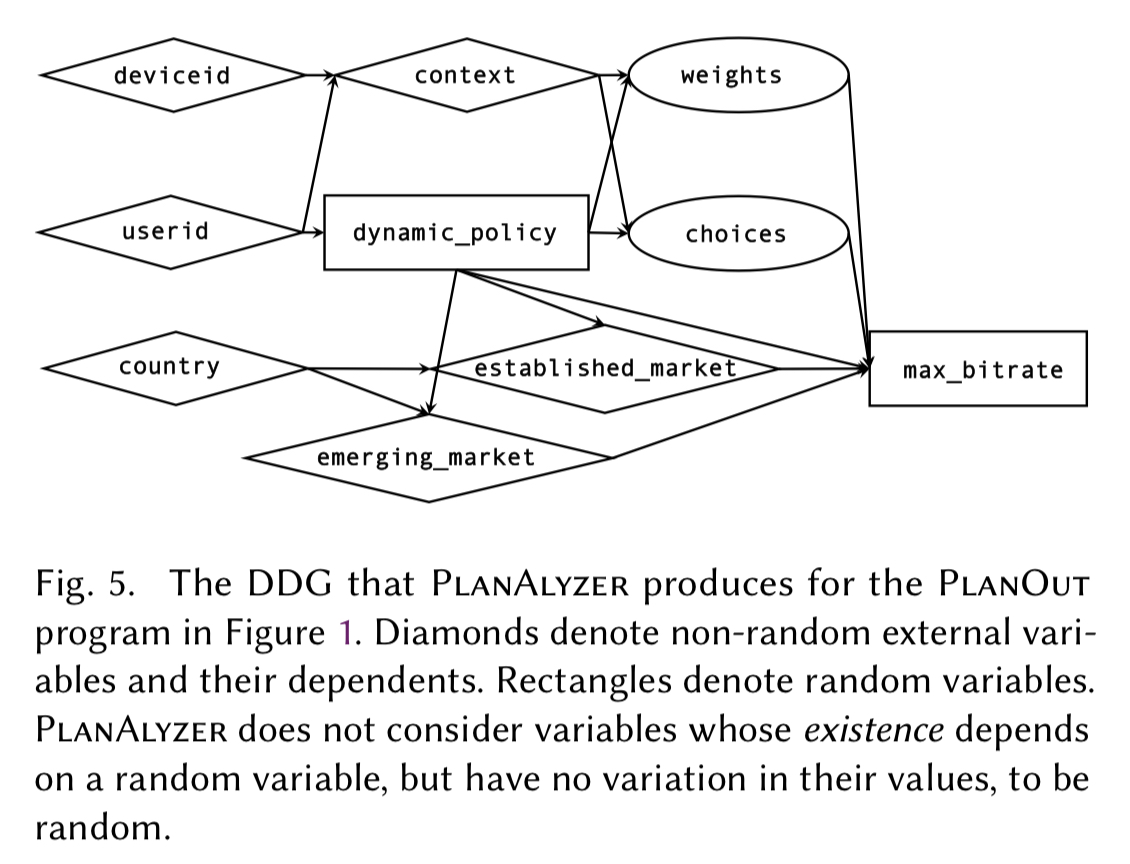
Using the graph, PlanAlyzer then checks for randomization, treatment assignment, and causal sufficiency errors:
Randomisation failure checks:
- Recording data on a path that is not randomised
- Units of randomisation with low cardinality
- Path-induced determinism
Treatment assignment failure checks:
- Treatments with zero probability of being assigned (positivity errors)
- There are fewer than two treatments that may be compared along a path
- Dead code blocks containing treatment assignment
Causal sufficiency errors
- Allowing an unrecorded variable to bias treatment assignment§
Analysing PlanOut experiments at Facebook
Facebook provided a corpus of PlanOut scripts that we used to evaluate PlanAlyzer via a single point of contact. This corpus contains every PlanOut script written between 3 August 2015 and 3 August 2017… Facebook also provided us with a corpus of manually specified contrasts that were used in the analysis of the experimentation scripts that were actually deployed.
The corpus is divided into three sections (A, B, and C) depending on whether or not the script was deployed, and whether or not the script executions were analysed using some form of ATE. The Corpus stats make for interesting reading just to understand the scale of experimentation (e.g., 240 unique deployed and contrast analysed experiments authored by 30 unique authors over the 2 year period – more than two a week).
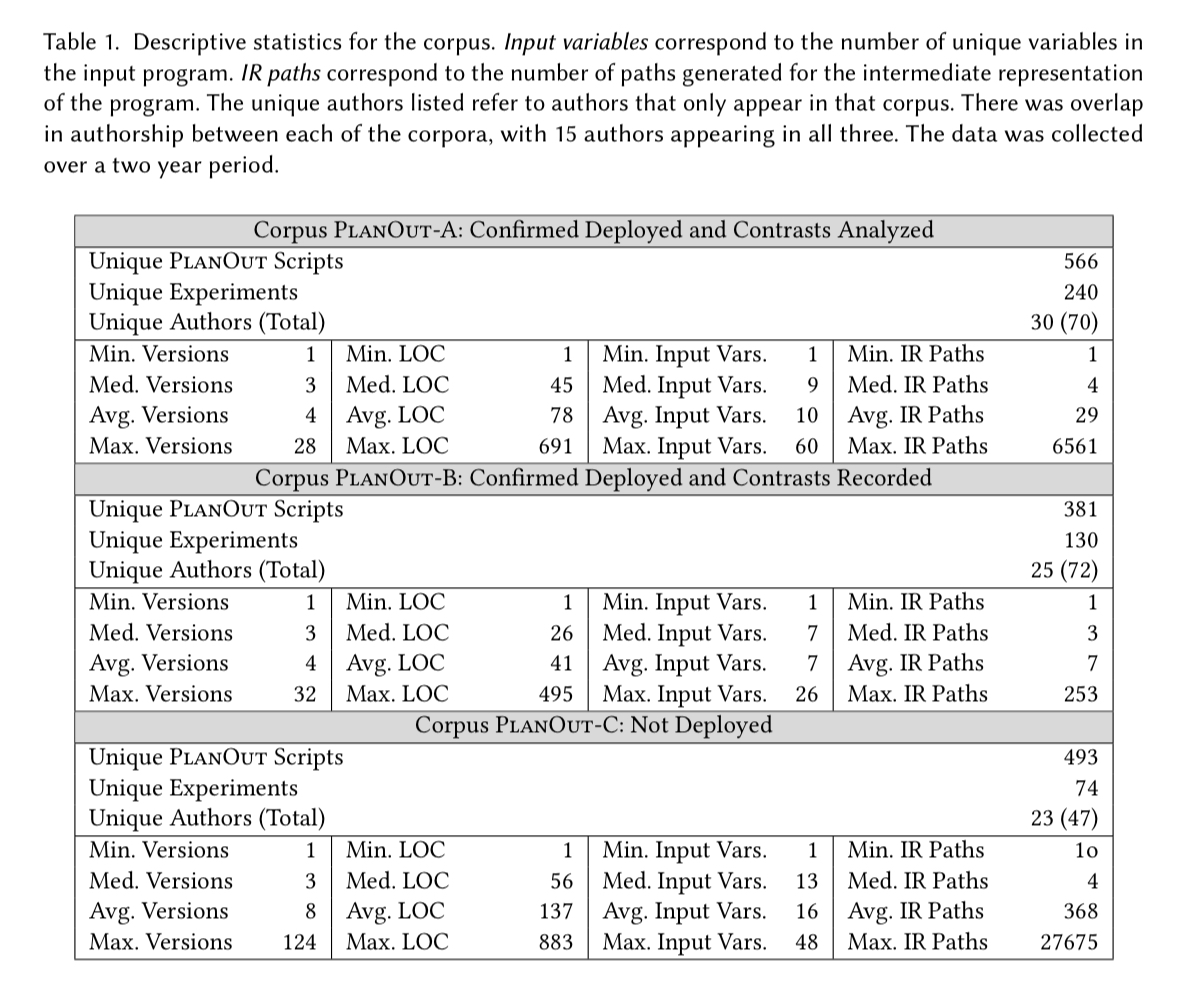
PlanOut-A is the gold standard group: all scripts were vetted by experts before deployment, with some component analysed using ATE. This scripts are mostly in pretty good shape when analysed with PlanAlyzer:
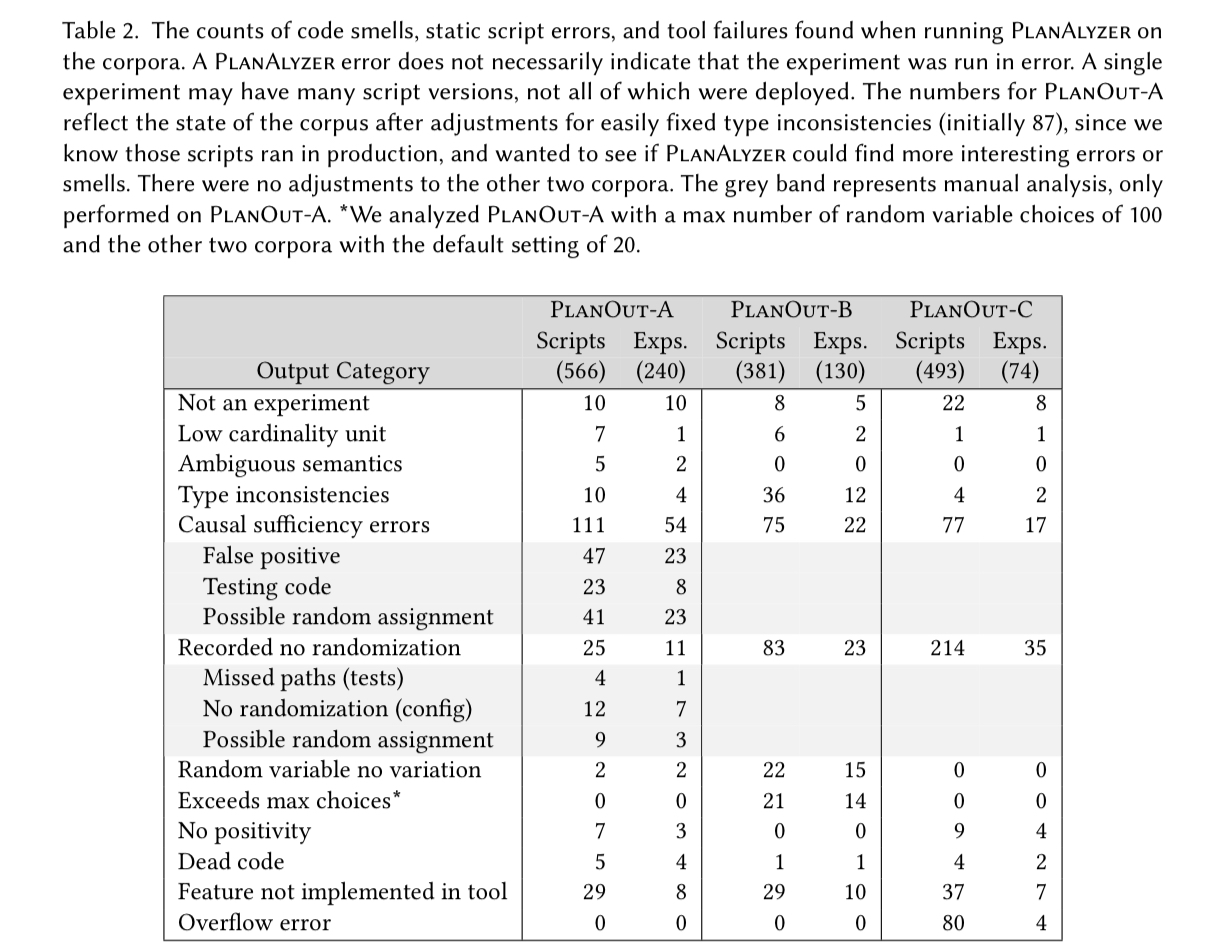
Real-world PlanOut scripts unsurprisingly contained few errors, since they were primarily written and overseen by experts in experimental design. For example, of the 25 recorded paths with no randomization, nine contained a special gating function that may sometimes be random, depending on its arguments…
To create some more buggy experimental designs for PlanAlyzer to detect, the authors injected mutations into fifty of the scripts from PlanOut-A. When analyzing this corpus, PlanAlzyer produced only one false negative and one false positive.
PlanAlyzer’s contrast reporting was also comparable with the human-specified gold standard (finding equivalent contrast for 78 of 95 experiments). The longest runtime for PlanAlyzer was about three minutes.

One thought on “PlanAlyzer: assessing threats to the validity of online experiments”
Comments are closed.