Local-first software: you own your data, in spite of the cloud Kleppmann et al., Onward! ’19
Watch out! If you start reading this paper you could be lost for hours following all the interesting links and ideas, and end up even more dissatisfied than you already are with the state of software today. You might also be inspired to help work towards a better future. I’m all in :).
The rock or the hard place?
On the one-hand we have ‘cloud apps’ which make it easy to access our work from multiple devices and to collaborate online with others (e.g. Google Docs, Trello, …). On the other hand we have good old-fashioned native apps that you install on your operating system (a dying breed? See e.g. Brendan Burns’ recent tweet). Somewhere in the middle, but not-quite perfect, are online (browser-based) apps with offline support.
The primary issue with cloud apps (the SaaS model) is ownership of the data.
Unfortunately, cloud apps are problematic in this regard. Although they let you access your data anywhere, all data access must go via the server, and you can only do the things that the server will let you do. In a sense, you don’t have full ownership of that data— the cloud provider does.
Services do get shut down1, or pricing may change to your disadvantage, or the features evolve in a way you don’t like and there’s no way to keep using an older version.
With a traditional OS app2 you have much more control over the data (the files on your file system at least, which if you’re lucky might even be in an open format). But you have other problems, such as easy access across all of your devices, and the ability to collaborate with others.
Local-first software ideals
The authors coin the phrase “local-first software” to describe software that retains the ownership properties of old-fashioned applications, with the sharing and collaboration properties of cloud applications.
In local-first applications… we treat the copy of the data on your local device — your laptop, tablet, or phone — as the primary copy. Servers still exist, but they hold secondary copies of your data in order to assist with access from multiple devices. As we shall see, this change in perspective has profound implications…
Great local-first software should have seven key properties.
- It should be fast. We don’t want to make round-trips to a server to interact with the application. Operations can be handled by reading and writing to the local file system, with data synchronisation happening in the background.
- It should work across multiple devices. Local-first apps keep their data in local storage on each device, but the data is also synchronised across all the devices on which a user works.
- It should work without a network. This follows from reading and writing to the local file system, with data synchronisation happening in the background when a connection is available. That connection could be peer-to-peer across devices, and doesn’t have to be over the Internet.
- It should support collaboration. “In local-first apps, our ideal is to support real-time collaboration that is on par with the best cloud apps today, or better. Achieving this goal is one of the biggest challenges in realizing local-first software, but we believe it is possible.“
- It should support data access for all time. On one level you get this if you retain a copy of the original application (and an environment capable of executing it). Even better is if the local app using open / long lasting file formats. See e.g. the Library of Congress recommended archival formats.
- It should be secure and private by default. “Local-first apps can use end-to-end encryption so that any servers that store a copy of your files only hold encrypted data they cannot read.”
- It should give the user full ownership and control of their data. “…we mean ownership in the sense of user agency, autonomy, and control over data. You should be able to copy and modify data in any way, write down any thought, and no company should restrict what you are allowed to do.“
How close can we get today?
Section 3 in the paper shows how a variety of different apps/technologies stack up against the local-first ideals.
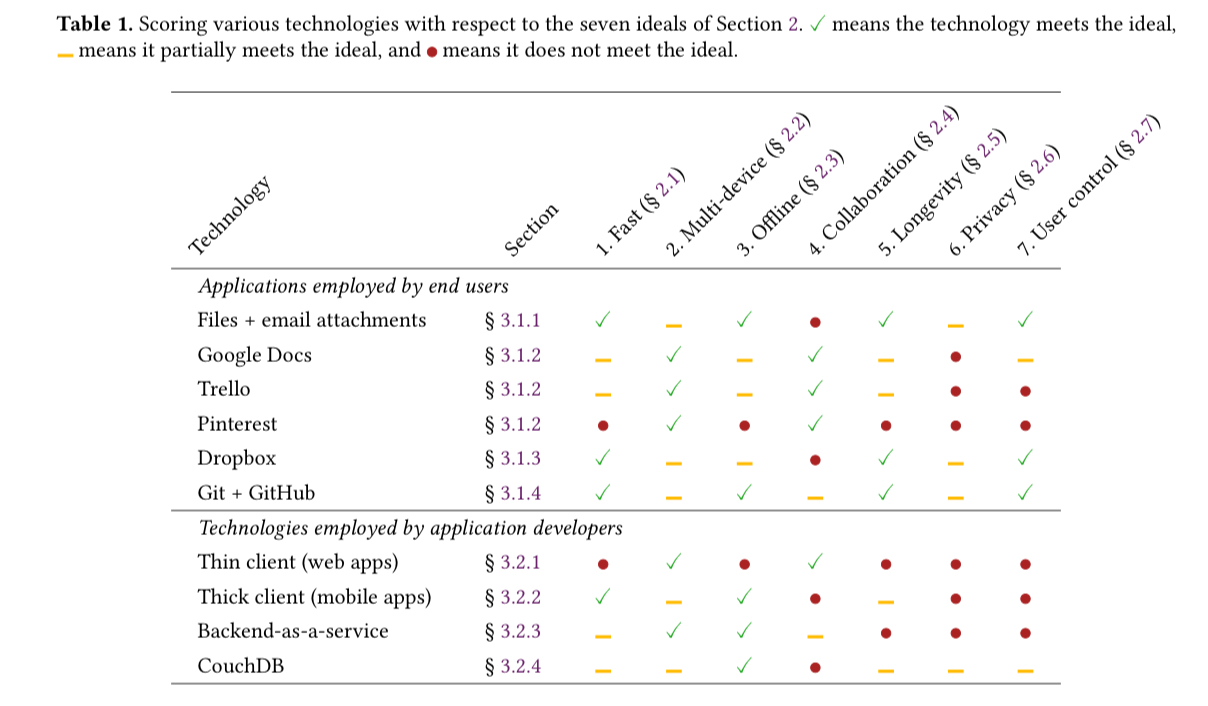
The combination of Git and GitHub gets closest, but nothing meets the bar across the board.
… we speculate that web apps will never be able to provide all the local-first properties we are looking for, due to the fundamental thin-client nature of the platform. By choosing to build a web app, you are choosing the path of data belonging to you and your company, not to your users.
Mobile apps that use local storage combined with a backend service such as Firebase and its Cloud Firestore take us closer to the local-first ideal, depending on the way the local data is treated by the application. CouchDB also gets an honourable mention in this part of the paper, only being let down by the difficulty of getting application-level conflict resolution right.
CRDTs to the rescue?
We have found some technologies that appear to be promising foundations for local-first ideals. Most notably the family of distributed systems algorithms called Conflict-free Replicated Data Types (CRDTs)… the special thing about them is that they are multi-user from the ground up… CRDTs have some similarity to version control systems like Git, except that they operate on richer data types than text files.
While most industrial usage of CRDTs has been in server-centric computing, the Ink & Switch research lab have been exploring how to build collaborative local-first client applications built on top of CRDTs. One of the fruits of this work is an open-source JavaScript CDRT implementation called Automerge which brings CRDT-style merge operations to JSON documents. Used in conjunction with the dat:// networking stack the result is Hypermerge.
Just as packet switching was an enabling technology for the Internet and the web, or as capacitive touchscreens were an enabling technology for smart phones, so we think CRDTs may be the foundation for collaborative software that gives users full ownership of their data.
The brave new world
The authors built three (fairly advanced) prototypes using this CRDT stack: a Trello clone called Trellis, a collaborative drawing program, and a ‘mixed-media workspace’ called PushPin (Evernote meets Pinterest…).
If you have 2 minutes and 10 seconds available, it’s well worth watching this short video showing Trellis in action. It really brings the vision to life.
In section 4.2.4 of the paper the authors share a number of their learnings from building these systems:
- CRDT technology works – the Automerge library did a great job and was easy to use.
- The user experience with offline work is splendid.
- CRDTs combine well with reactive programming to give a good developer experience. “The result of [this combination] was that all of our prototypes realized real-time collaboration and full offline capability with little effort from the application developer.”
- In practice, conflicts are not as significant a problem as we feared. Conflicts are mitigated on two levels: first, Automerge tracks changes at a fine-grained level, and second, “users have an intuitive sense of human collaboration and avoid creating conflicts with their collaborators.”
- Visualising document history is important (see the Trellis video!).
- URLs are a good mechanism for sharing
- Cloud servers still have their place for discovery, backup, and burst compute.
Some challenges:
- It can be hard to reason about how data moves between peers.
- CRDTs accumulate a large change history, which creates performance problems. (This is an issue with state-based CRDTs, as opposed to operation-based CRDTs).
Performance and memory/disk usage quickly became a problem because CRDTs store all history, including character-by-character text edits. These pile up, but can’t be easily truncated because it’s impossible to know when someone might reconnect to your shared document after six months away and need to merge changes from that point forward.
It feels like some kind of log-compaction with a history watermark (e.g., after n-months you might not be able to merge in old changes any more and will have to do a full resync to the latest state) could help here?
- P2P technologies aren’t production ready yet (but “feel like magic” when they do work).
What can you do today?
You can take incremental steps towards a local-first future by following these guidelines:
- Use aggressive caching to improve responsiveness
- Use syncing infrastructure to enable multi-device access
- Embrace offline web application features (Progressive Web Apps)
- Consider Operational Transformation as the more mature alternative to CRDTs for collaborative editing
- Support data export to standard formats
- Make it clear what data is stored on device and what is transmitted to the server
- Enable users to back-up, duplicate, and delete some or all of their documents (outside of your application?)
I’ll leave you with a quote from section 4.3.4:
If you are an entrepreneur interested in building developer infrastructure, all of the above suggests an interesting market opportunity: “Firebase for CRDTs.”
- This link to ‘Our Incredible Journey’ handily provides a good example— it will take you first to a page announcing that Tumblr has been acquired by Automattic, on which you can agree to the new terms of service should you wish. ↩
- Not the new breed of OS apps that are really just wrapped browsers over an online service ↩

Nice post
Are you familiar with the Scuttlebutt protocol, and it’s collection of applications (https://scuttlebutt.nz/)? I’d love to see your analysis of how well that system meets the criteria you’ve referenced.
*its
What main features do you think this “Firebase for CRDTs” should have?