File systems unfit as distributed storage backends: lessons from 10 years of Ceph evolution Aghayev et al., SOSP’19
Ten years of hard-won lessons packed into just 17 pages (13 if you don’t count the references!) makes this paper extremely good value for your time. It’s also a fabulous example of recognising and challenging implicit assumptions. In this case, the assumption that a distributed storage backend should clearly be layered on top of a local file system. Breaking that assumption allowed Ceph to introduce a new storage backend called BlueStore with much better performance and predictability, and the ability to support the changing storage hardware landscape. In the two years since it’s release, 70% of all Ceph users had switched to running BlueStore in production.
Ceph is a widely-used, open-source distributed file system that followed this convention [of building on top of a local file system] for a decade. Hard lessons that the Ceph team learned using several popular file systems led them to question the fitness of file systems as storage backends. This is not surprising in hindsight.
Sometimes, things that aren’t surprising in hindsight can be the very hardest of things to spot!
What is a distributed storage backend?
A distributed file system provides a unified view over aggregated storage from multiple physical machines. It should offer high bandwidth, horizontal scalability, fault tolerance, and strong consistency. The storage backend is the software module directly managing the storage device attached to physical machines.
While different systems require different features from a storage backend, two of these features, (1) efficient transactions and (2) fast metadata operations appear to be common; another emerging requirement is (3) support for novel, backward-incompatible storage hardware.
Readers of this blog properly have a pretty good idea what ‘efficient transactions’ and ‘fast metadata operations’ are all about. But let’s take a quick look at the changing hardware landscape before we go on…
The changing hardware landscape
To increase capacity, hard disk drive (HDD) vendors are introducing Shingled Magnetic Recording (SMR) technology. To use these drives efficiently, it is necessary to switch to using their backward-incompatible zone interface.
The zone interface… manages the disk as a sequence of 256 MiB regions that must be written sequentially, encouraging a log-structured, copy-on-write design. This design is in direct opposition to the in-place overwrite design followed by most mature file systems.
A similar change is happening with SSDs, where a new NVMe standard called Zoned Namespaces (ZNS) enables the flash-translation layer (FTL) to be bypassed.
Attempts to modify production file systems to work with the zone interface have so far been unsuccessful, “primarily because they are overwrite file systems.”
Ten years of building on local file systems
If you need to manage files on a local storage device, it seems pretty obvious that a file system is a good place to start. After all, there’s a lot of work that goes into a file system:
The history of production file systems shows that on average they take a decade to mature.
This was the starting assumption for Ceph and many others for over a decade.
The core of Ceph is RADOS, the Reliable Autonomic Distributed Object Store service. The RADOS Gateway object store (cf. S3), RADOS block device (cf. EBS), and CephFS distributed file system are all built on top of RADOS. RADOS has been through a number of iterations in the preceding decade+.
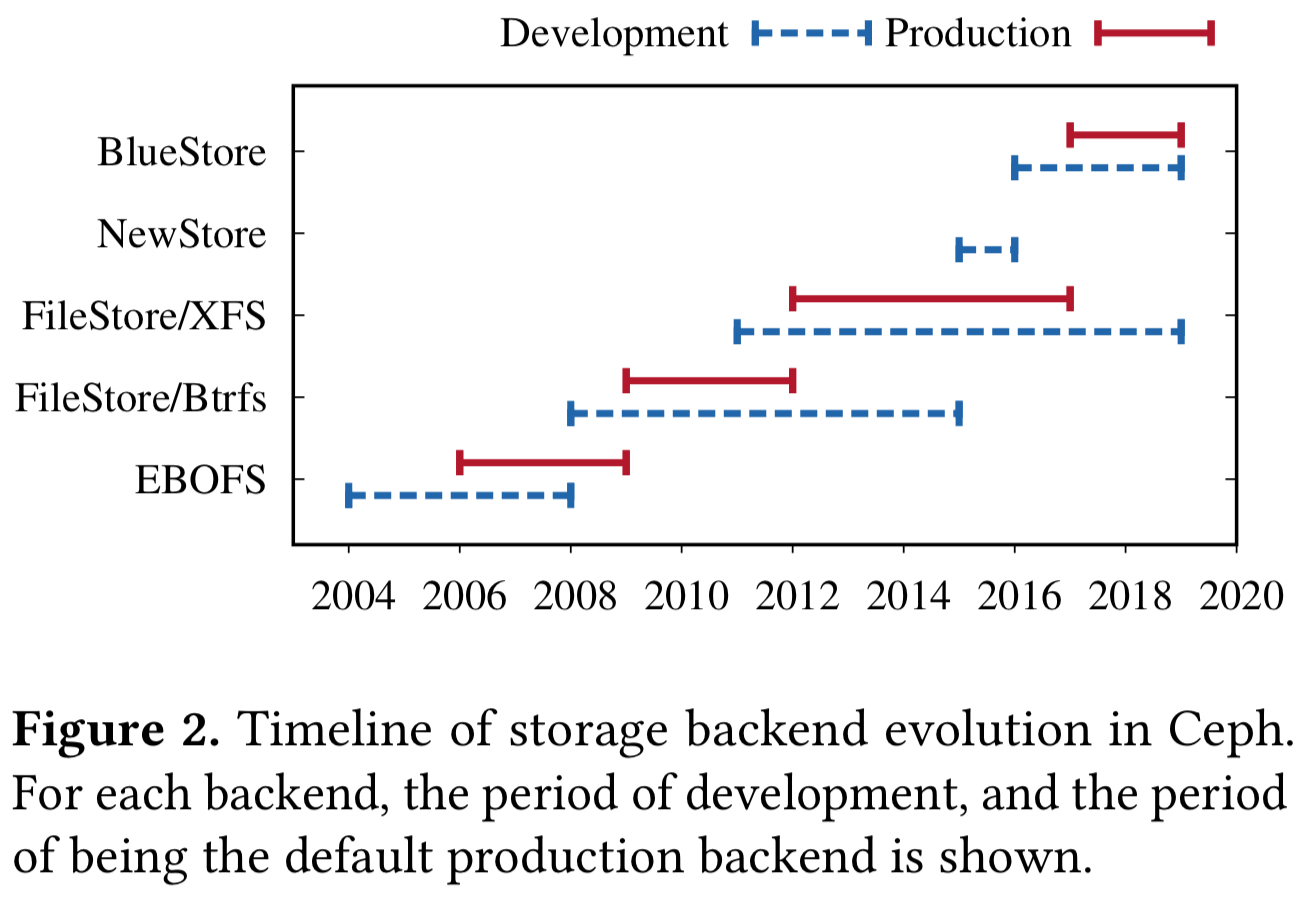
The first implementation (c. 2004) was a user-space file system called the Extent and B-Tree based object file system. In 2008, with the emergence of Btrfs, a new implementation was built taking advantage of Btrfs’ transactions, deduplication, checksums, and compression.
FileStore on Btrfs was the production backend for several years, throughout which Btrfs remained unstable and suffered from severe data and metadata fragmentation.
Btrfs was eventually abandoned in favour of XFS, ext4, and then ZFS. Of these, XFS became the defacto backend because it scaled better and had faster metadata performance.
While FileStore on XFS was stable, it still suffered from metadata fragmentation and did not exploit the full potential of the hardware.
Three challenges building storage backends on local file systems
- Implementing transactions efficiently
- Making metadata operations fast
- Supporting new storage hardware
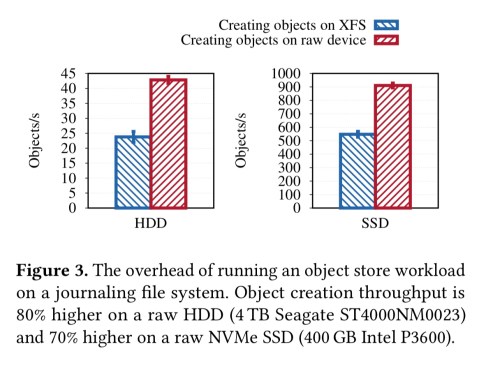
Implementing transactions efficiently
The authors tried three different strategies over time for transactions, each of them resulting in either significant performance or complexity overhead. The first approach is to hook into the internal transaction mechanism of the file system itself if it provides one. Typically though, even when the file system does provide a transaction mechanism it is too limited for the object store use case (e.g., no rollback support on Btrfs for a time, these days it just has no transaction system calls at all).
A second approach is to implement a logical WAL (write-ahead log) in user space. This led to slow read-modify-write cycles and double writes.
The third approach was to use RocksDB for metadata, which helped with some of these issues by supporting atomic metadata operations, but introduced others – notably high consistency overhead through the requirement to flush more often.
Making metadata operations fast
Ineffiency of metadata operations in local file systems is a source of constant struggle for distributed file systems.
When directories get too many files in them, enumerating the files becomes slow, so the standard practice is to create directory hierarchies with a large fan-out and a few hundred entries per directory. Managing this at scale is a costly process – there are still millions of inodes resulting in many small I/Os, and directory entries spread out on the disk over time. “When all Ceph OSDs start splitting in unison performance suffers… this is a well-known problem that has been affecting many Ceph users over the years.”
Supporting modern hardware
We looked at this issue earlier. Fundamentally the tension here is that copy-on-write overwrite semantics don’t fit with the emerging zone interface semantics.
Maybe there’s a better way…
Following FileStore on XFS, NewStore was introduced which stored object metadata in RocksDB. This alleviated issues with metadata fragmentation, but introduced problems of its own with a high consistency overhead when layered over the top of a journaling file system. NewStore was quickly followed by BlueStore, which used raw disks
BlueStore is a storage backend designed from scratch to solve the challenges faced by backends using local file systems. Some of the main goals of BlueStore were: (1) Fast metadata operations, (2) No consistency overhead for object writes, (3) Copy-on-write clone operation, (4) No journaling double-writes, (5) Optimized I/O patterns for HDD and SDD. BlueStore achieved all of these goals within just two years and became the default storage backend in Ceph.
BlueStore stores metadata in RocksDB to ensure fast metadata operations. To avoid any consistency overheads on object writes it writes data directly to raw disk, so there is only one cache flush fora data write. It also introduced a change to RocksDB (upstreamed) so that WAL files are used as circular buffers for metadata writes. RocksDB itself runs on BlueFS, a minimal file system than runs on raw storage devices. The namespace scheme allows collections of millions of objects to be split into multiple collections simply by changing the number of significant bits considered as a key.
The BlueStore backend is copy-on-write. For writes larger than the minimum allocation size BlueStore provides an efficient clone operation and can avoid journal double writes. For writes smaller than the minimum allocation size metadata and data are first inserted to RocksDB, and the asynchronously written to disk after commit.
Because BlueStore provides full control over the I/O stack, it was also possible to efficiently implement checksums and transparent compression. Moreover, RocksDB and BlueStore have both been ported to run on host-managed SMR drives, and a new effort is underway to target a combination of persistent memory and emerging NVMe devices with novel interfaces (e.g. ZNS SSDs and KV SSDs).
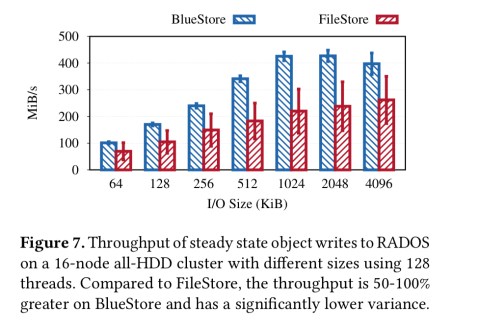
BlueStore performance highlights
For the full details of the performance evaluation, see §6 in the paper. I brief, BlueStore demonstrated 50-100% steady-state throughput improvements when compared to FileStore, which an order-of-magnitude lower tail latency.
Taking it to the next level
Three open challenges remain to eek out every last bit of performance:
- Building an efficient user space cache with dynamic resizing functionality – a problem shared by other projects such as PostgreSQL and RocksDB
- Issues with RocksDB and write-amplification on NVMe SSDs, high CPU usage for serialization and deserialization, and a threading model that prohibits custom sharding. “These and other problems with RocksDB and similar key-value stores keeps the Ceph team researching better solutions.”
- On high-end NVMe SSDs workloads are becoming increasingly CPU-bound. “For its next-generation backend, the Ceph community is exploring techniques that reduce the CPU consumption, such as minimizing data serialization-deserialization, and using the SeaStar framework with a shared-nothing model…“
We hope that this experience paper will initiate discussions among storage practitioners and researchers on fresh approaches to designing distributed file systems and their storage backends.

Is there a way to take advantage of lessons learned from the Google File System?
You wrote:
We looked at this issue earlier. Fundamentally the tension here is that copy-on-write semantics don’t fit with the emerging zone interface semantics.
Did you mean to write “in place change semantincs don’t fit…”?
Minor typo:
“In the two years since it’s release” ->
“In the two years since its release”
Out of mere curiosity, would you have any more context on why ZFS was abandoned (or btrfs may have been used before ZFS)?
good one
Wow who would have guessed that a system designed to work on one disk in one machine would not work well on many disks in many machines
Very interesting article which unfortunately used completely unrealistic hardware configuration (way too many CPU cores and NVMe IOPS and network Gbs and even RAM GB per HDD OSD) for performance testing; I’d be very surprised if anyone deployed Ceph cluster with anything resembling this hw config (even from a price/performance point of view).
Great writeup, thank you. FYI it’s ‘eke out’, not ‘eek out’ :)
thanks for sharing
Performance Management Services in Pakistan
Performance Management Solution in Pakistan