An analysis of performance evolution of Linux’s core operations Ren et al., SOSP’19
I was drawn in by the headline results here:
This paper presents an analysis of how Linux’s performance has evolved over the past seven years… To our surprise, the study shows that the performance of many core operations has worsened or fluctuated significantly over the years.
When you get into the details I found it hard to come away with any strongly actionable takeaways though. Perhaps the most interesting lesson/reminder is this: it takes a lot of effort to tune a Linux kernel. For example:
- “Red Hat and Suse normally required 6-18 months to optimise the performance an an upstream Linux kernel before it can be released as an enterprise distribution”, and
- “Google’s data center kernel is carefully performance tuned for their workloads. This task is carried out by a team of over 100 engineers, and for each new kernel, the effort can also take 6-18 months.”
Meanwhile, Linux releases a new kernel every 2-3 months, with between 13,000 and 18,000 commits per release.
Clearly, performance comes at a high cost, and unfortunately, this cost is difficult to get around. Most Linux users cannot afford the amount of resource large enterprises like Google put into custom Linux performance tuning…
For Google of course, there’s an economy of scale that makes all that effort worth it. For the rest of us, if you really need that extra performance (maybe what you get out-of-the-box or with minimal tuning is good enough for your use case) then you can upgrade hardware and/or pay for a commercial license of a tuned distributed (RHEL).
A second takeaway is this: security has a cost!
Measuring the kernel
The authors selected a set of diverse application workloads, as shown in the table below, and analysed their execution to find out the system call frequency and total execution time.
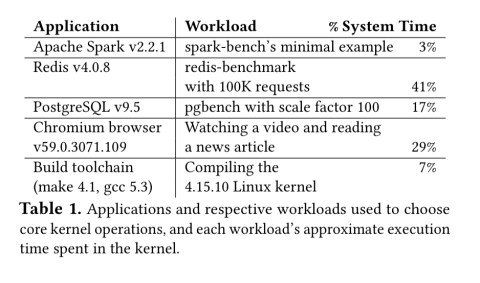
A micro-benchmark suite, LEBench was then built around tee system calls responsible for most of the time spent in the kernel.

On the exact same hardware, the benchmark suite is then used to test 36 Linux release versions from 3.0 to 4.2.0.
Headline results
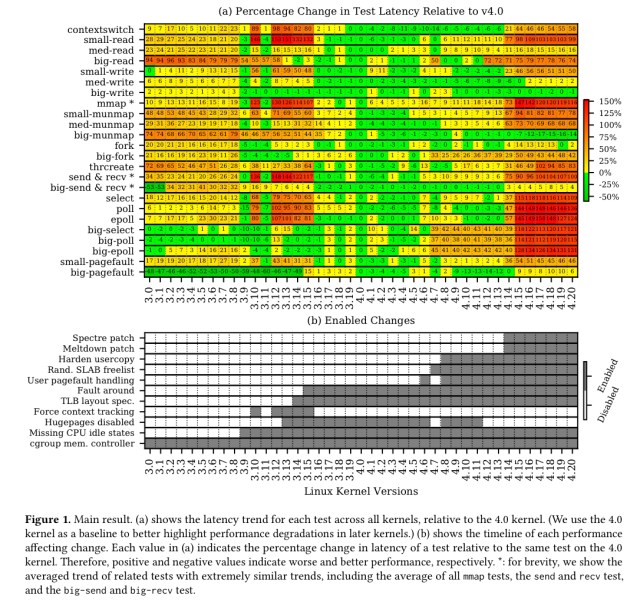
All kernel operations are slower than they were four years ago (version 4.0), except for
big-writeandbig-munmap. The majority (75%) of the kernel operations are slower than seven years ago (version 3.0). Many of the slowdowns are substantial…
The following figure shows the relative speed-up/slow-down across the benchmarked calls (y-axis) across releases (x-axis). The general pattern to my eye is that things were getting better / staying stable until around v4.8-v.14, and after that performance starts to degrade noticeably.
Analysis
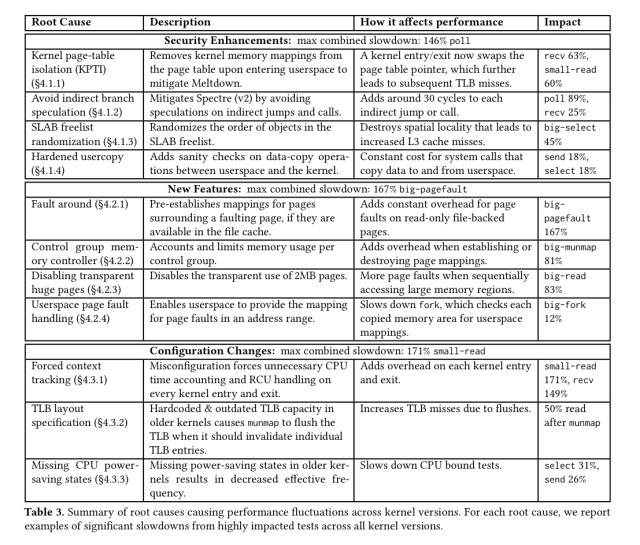
We identify 11 kernel changes that explain the significant performance fluctuations as well as more steady sources of overhead.
These changes fall into three main groups:
- (4) Security enhancements (e.g. to protect against Meltdown and Spectre) ).
- (4) New features introduced into the kernel that came with a performance hit in some scenarios
- (3) Configuration changes
In terms of the maximum combined slowdown though, it’s not the Meltdown and Spectre patches that cause the biggest slowdowns (146% cf. a 4.0 baseline), but missing or misconfigured configuration changes (171%). New features also contribute a combined maximum slowdown of 167%. If you drill down into the new features though, some of these are arguably security related too -e.g. the cgroup memory controller change for containers.
The following chart shows the impact of these 11 changes across the set of system calls under study.
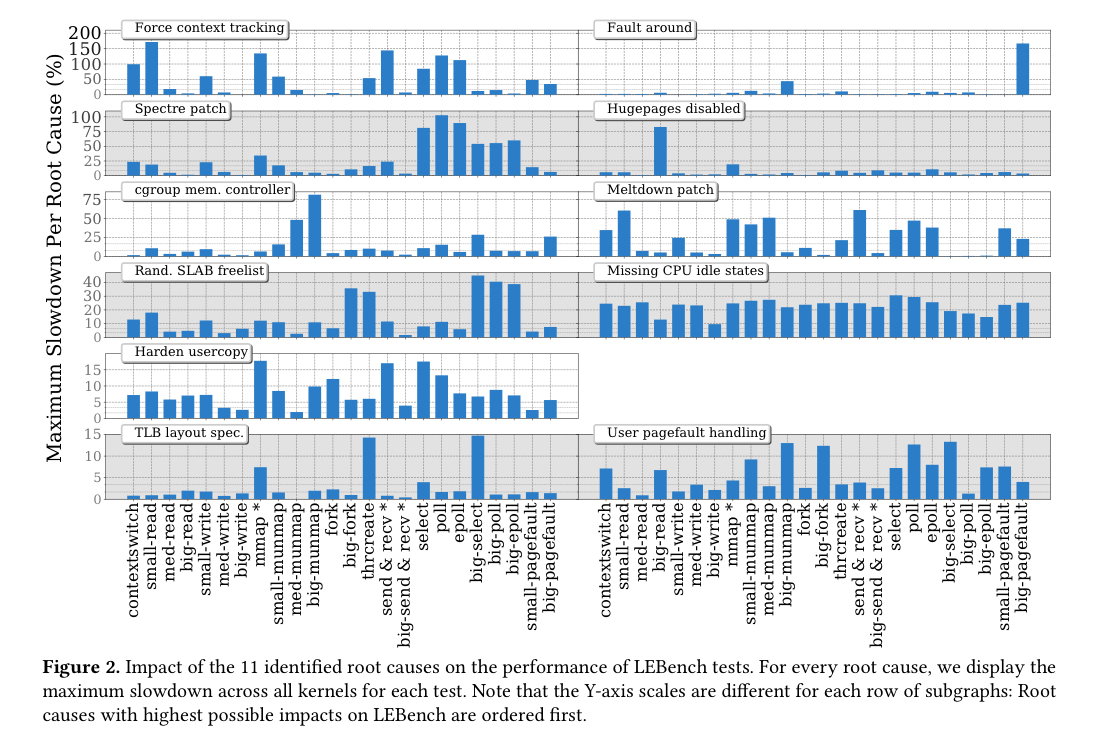
It’s possible to avoid the overheads from these 11 changes if you want to, but that doesn’t feel like a path to recommend for most of them!
With little effort, Linux users can avoid most of the performance degradation from the identified root causes by actively reconfiguring their systems. In fact, 8 out of 11 root causes can be disabled through configuration, and the other 3 can be disabled through simple patches.
Testing against real-world workloads (Redis, Apache, Nginx), disabling the 11 root causes results in maximum performance improvements in these three applications of 56%, 33%, and 34% respectively. On closer examination, 88% of the slowdowns experienced by these applications can be tied back to just four of the eleven changes: forced context tracking (a configuration error), kernel page table isolation (Meltdown protection), missing CPU idle power states (in the configuration bucket, but really due to older kernel versions lacking specifications for the newer hardware used in the benchmarking, which is kind of fair game?), and avoidance of indirect jump speculation (Spectre).
Security related root causes
- Kernel page table isolation (KPTI), introduced to protect against Meltdown. The average slowdown caused by KPTI across all microbenchmarks in 22%, with
recvandreadtests seeing 63% and 59% slowdowns. Before KPTI, the kernel and user space used one shared page table, with KPTI they have separate page tables. The main source of introduced overhead is swapping the page table pointers on every kernel entry and exit, together with a TLB flush. The flush can be avoided on processors with the process-context identifier (PCID) feature, but even this isn’t enough to avoid the reported slowdowns. - Avoidance of indirect branch speculation (the Retpoline patch) to protect against Spectre. This causes average slowdowns of 66% across the
select,poll, andepolltests. The more indirect jumps and calls in a test, the worse the overhead. The authors found that turning each indirect call here into a switch statement (a direct conditional branch) alleviates the performance overhead. ![][FIG6] - SLAB freelist randomization, which increases the difficulty of exploiting buffer overflow bugs. By randomising the order of free spaces for objects in a SLAB, there is a notable overhead (37-41%) when sequentially accessing large amounts of memory.
- The hardened usercopy patch, which validates kernel pointers used when copying data between userspace and the kernel.
New-feature related root causes
- The ‘fault-around’ feature aims to reduce the number of minor page faults, but introduces a 54% slowdown in the ‘big-pagefault’ test where its access pattern assumptions do not hold.
- The cgroup memory controller was introduced in v2.6 and is a key building block of containerization technologies. It adds overhead to tests that exercise the kernel memory controller, even when cgroups aren’t being used. It took 6.5 years (until v 3.17) for this overhead to begin to be optimised. Before those optimisations, slowdowns of up to 81% were observed, afterwards this was reduced to 9%.
- Transparent huge pages (THP) have been in and out and in and out again as a feature enabled by default. THP automatically adjusts the default page size and allocates 2MB (huge) pages, but can fall back to 4KB pages under memory pressure. Currently it is disabled by default. In what seems to be a case of damned-if-you-do, damned-if-you-don’t, without THP some tests are up to 83% slower.
- Userspace page fault handling allows a userspace process to handle page faults for a specific memory region. In most cases its overhead is negligible, but the
big-forktest sees a 4% slowdown with it.
Configuration related root causes
- Forced context tracking was released into the kernel by mistake in versions 3.10 and 3.12-15 (it’s a debugging feature using in the development of the reduced scheduling clock-ticks – RSCT – feature). It was enabled in several released Ubuntu kernels due to misconfiguration. Forced context tracking was finally switched off 11 months after the initial misconfiguration. It slowed down all of the 28 tests by at least 50%, 7 of them by more than 100%.
- The TLB layout change patch was introduced in v3.14, and enables Linux to recognise the size of the second-level TLB on newer Intel processors. It’s on the list as a configuration related problem since there was a six-month period when the earliest Haswell processors were released but the patch wasn’t, resulting in a slowdown running on those processors.
- The CPU idle power-state support patch similarly informs the kernel about fine-grained power-saving states available on Intel processors. It’s on the list because it wasn’t backported to the LTS kernel lines at the time, giving reduced performance on newer processors with those kernels.

An interesting topic to research, but a shame they botched the statistics (and benchmarking in general). These results are not believable.
For information on system calls see: “POSIX Abstractions in Modern Operating Systems”
Click to access eurosys2016posix.pdf
The issue of hardware variability was not covered:
http://shape-of-code.coding-guidelines.com/2015/02/24/hardware-variability-may-be-greater-than-algorithmic-improvement/
and there are lots of OS specific variability issues; they should have at least rebooted multiple times and rerun the benchmark.
As for picking the top 5 out of 10,000 measurements. Shoot that man!
Derek, they don’t pick the top 5 of 10k measurements – I believe they do k-best, which is the slowest 5 where adjacent values are not more than 5% apart. It certainly is an interesting choice, but not quite bad as top 5 of 10k as you make it out to be.