Learning a unified embedding for visual search at Pinterest Zhai et al., KDD’19
Last time out we looked at some great lessons from Airbnb as they introduced deep learning into their search system. Today’s paper choice highlights an organisation that has been deploying multiple deep learning models in search (visual search) for a while: Pinterest.
With over 600 million visual searches per month and growing, visual search is one of the fastest growing products at Pinterest and of increasing importance.
Visual search is pretty fundamental to the Pinterest experience. The paper focuses on three search-based products: Flashlight, Lens, and Shop-the-Look.

In Flashlight search the search query is a source image either from Pinterest or the web, and the search results are relevant pins. In Lens the search query is a photograph taken by the user with their camera, and the search results are relevant pins. In Shop-the-Look the search query is a source image from Pinterest or the web, and the results are products which match items in the image.
Models are like microservices in one sense: it seems that they have a tendency to proliferate within organisations once they start to take hold! (Aside, I wonder if there’s a models:microservices ratio that organisations further along their journeys tend to approximate? 1:10? , 1:20?, 1:30??).
Historically, each combination of input domain (Pinterest catalog images vs camera photos) and task (browse vs exact product retrieval) had its own set of learned embeddings (and the three applications discussed here are far from being the only uses of visual embeddings at Pinterest). This created a number of engineering challenges though:
For our visual search products alone, we developed three specialized embeddings. As image recognition architectures are evolving quickly, we want to iterate our three specialized embeddings with modern architectures to improve our three visual search products.
When you take all the deployment considerations into account on top of the development costs, and fact that these embeddings are consumed by many downstream models, it all starts to sound pretty hairy:
…this situation is further exacerbated by downstream dependencies (e.g. usage in pin-to-pin ranking) on various specific versions of our embeddings, leading us to incrementally continue to extract multiple generations of the same specialized embeddings.
In order to maintain product velocity, it was time to simplify and streamline. Despite the different input domains and optimisation objectives, could it be possible to learn one universal set of image embeddings at Pinterest that are used across all tasks? Using the Booking.com terminology, this would be a semantic layer model replacing a number of task-specific models.
That’s exactly what Pinterest did, and as well as simplifying their pipelines, they also saw a significant improvement in model performance on each of the individuals tasks! Win-win.
Building blocks: classification and multi-task learning
The foundation of Pinterest’s approach to learning embeddings is classification based, following the architecture described in ‘[Classification is a strong baseline for deep metric learning][ClassificationForDL].’ This is combined with developments from the field of multi-task learning:
Multi-task learning aims to learn one model that provides multiple outputs from one input. By consolidating multiple single models into one multi-task model, previous works have seen both efficiency and performance improvements on each task due to the inherent complementary structure that exists in separate visual tasks.
Model architecture
End-to-end it looks like this:
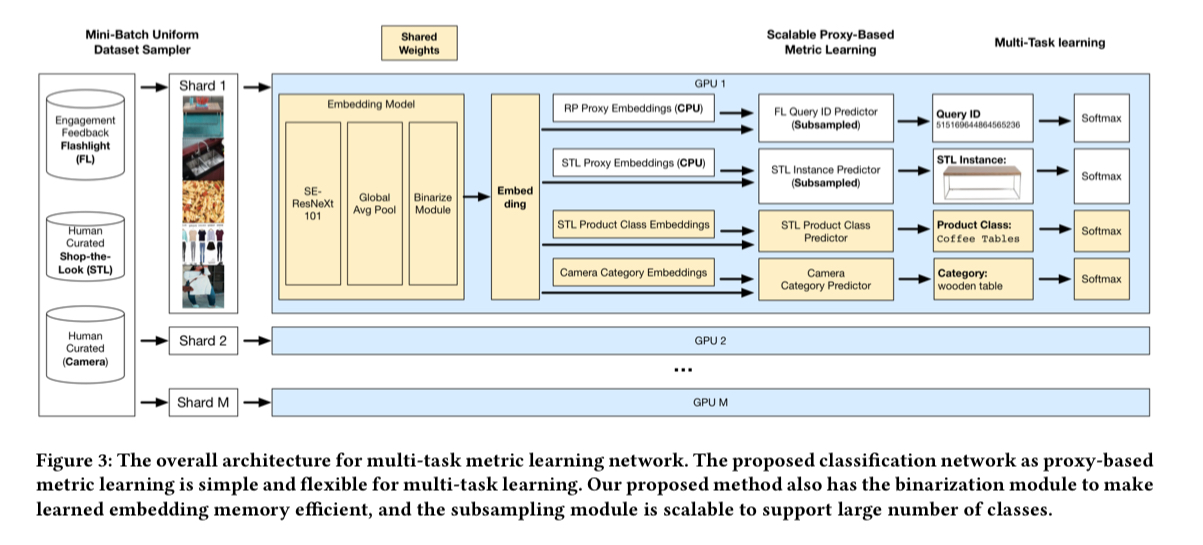
All the tasks share a common base network until the embedding is generated, and then things split off into task-specific branches. Task branches are fully connected layers, with the weights serving as the class proxies, and a softmax cross-entropy loss. To make all this work at scale, two important additional features are the use of subsampling to ensure scalability across hundreds of thousands of classes, and a binarization module to reduce the storage costs and prediction latency.
At Pinterest, we have a growing corpus of billions of images and as such we need effficient representations to (1) decrease cold storage costs, (2) reduce bandwidth for downstream consumers, and (3) improve the latency of real-time scoring.
Binarization is the process of replacing e.g. a float-based value, with a binary value (i.e., either 1 or 0) that collapses the range into two poles. For example, turning a grayscale value into either black or white.
The whole model is trained using PyTorch on one p3.16xlarge Amazon EC2 instance with eight Tesla V100 graphics cards.
Input datasets
The Flashlight, Lens, and Shop-The-Look datasets are all used as inputs to the training process.
The Flashlight dataset contains sets of related images with a shared label, ranked via engagement. It contains around 800K images across 15K semantic classes.
The Lens dataset was collected via human labelling of 540K images across 2K semantic classes. It contains a mix of product, camera, and Pinterest images under the same semantic label, so that the embeddings can learn to overcome the domain shifts.
The Shop-The-Look dataset is also a human labelled dataset. It contains 340K images across 189 semantic classes, and 50K instance (product) labels. “Images with the same instance label are either exact matches or are very similar visually as defined by an internal training guide for criteria such as design, color, and material.”
The three stages of evaluation
In addition to understanding how Pinterest collected its training datasets, it’s also interesting to look at their evaluation process. This has three parts to it: first there is offline evaluation using a held-out evaluation dataset; then a carefully controlled human judgement system is used to further assess model quality. Finally, models are evaluated using A/B testing in production.
Offline evaluation
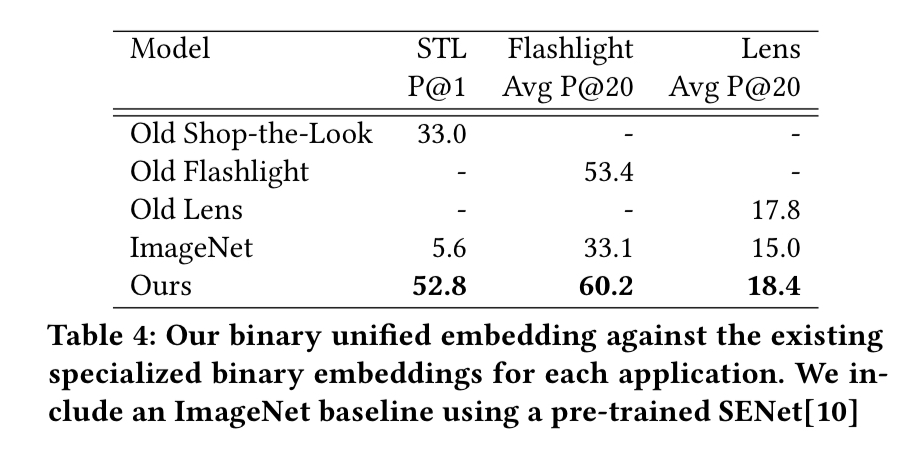
Offline measurements are the first consideration when iterating on new models.
The main results here show that the new unified embeddings outperform both an ImageNet baseline as well as all of the previous specialized embeddings.
Human judgement
Inserting a human judgement step between offline evaluation and A/B testing helps to measure end-to-end system performance before releasing an update live to users:
Practical information retrieval systems are complex, with retrieval, lightweight score, and ranking components using a plethora of features. As such it is important for us to measure the impact of our embeddings end-to-end in our retrieval systems… At Pinterest, we rely on human judgement to measure the relevance of our visual search products and use A/B experiments to measure engagement.
(Because otherwise the system could be showing images that are highly engaging, but not actually strongly related to the search?)
Using traffic-weighted samples of queries, two sets of 10K (question, answer) tasks per visual search product are built. The human judges are trained internal workers, and the questions they are answering look like this:

Human judgement results further confirm the superiority of the unified embeddings:
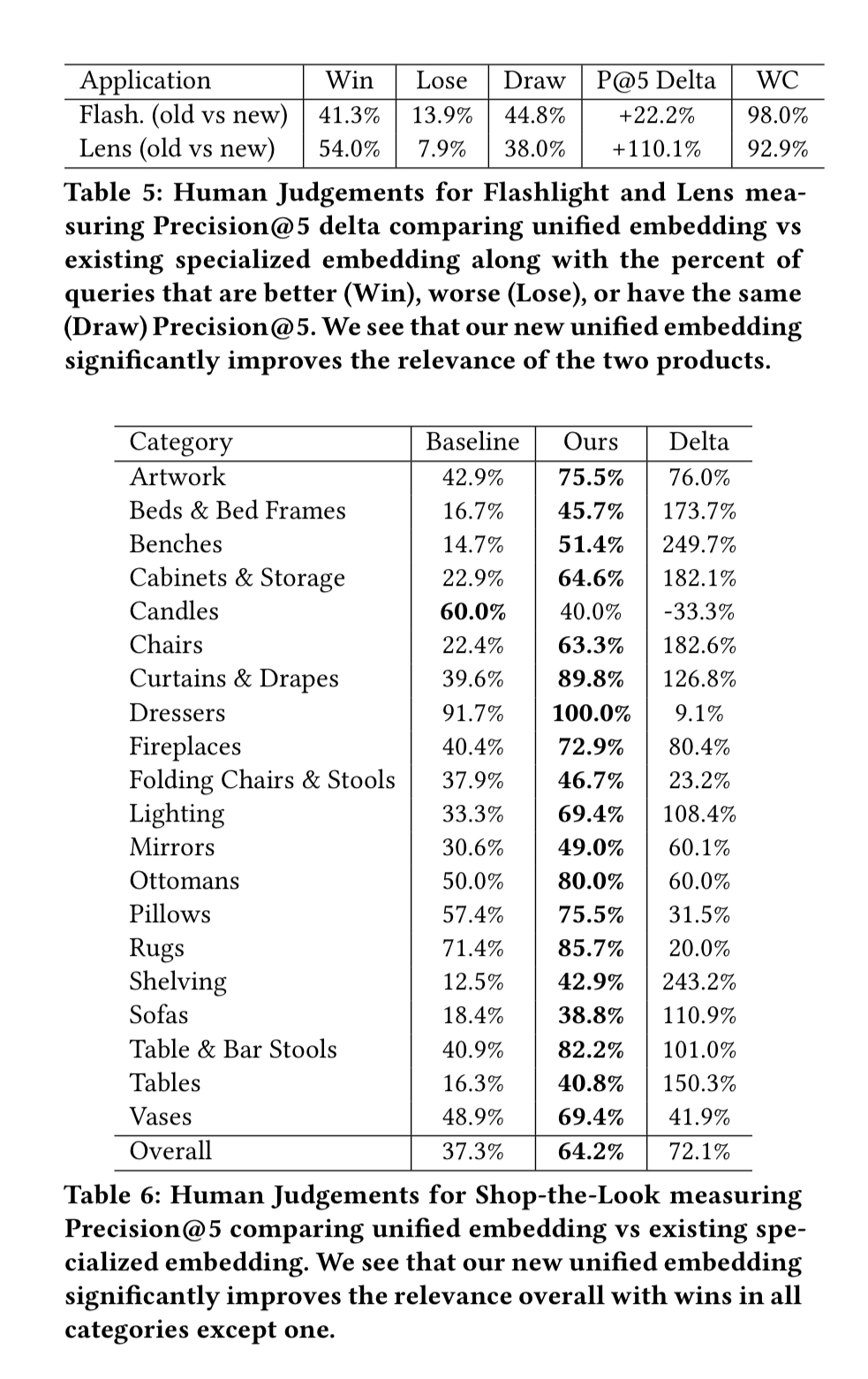
Our hypothesis for these significant gains beyond better model architecture is that combining the three datasets covered the weaknesses of each one independently.
A/B testing
A/B experiments at Pinterest are the most important criteria for deploying changes to production systems.
A/B testing for Flashlight and Lens showed significant lifts in engagement propensity and volume. (Shop-the-Look had not launched to users when initially experimenting with the unified embeddings). Given the difference in search results evident in the following figure, I’m not surprised!

The last word
Now with only one embedding to maintain and iterate, we have been able to substantially reduce experimentation, storage, serving costs as our visual search products rely on a unified retrieval system. These benefits enable us to move faster towards our most important objective – to build and improve products for our users.

One thought on “Learning a unified embedding for visual search at Pinterest”
Comments are closed.