Applying deep learning to Airbnb search Haldar et al., KDD’19
Last time out we looked at Booking.com’s lessons learned from introducing machine learning to their product stack. Today’s paper takes a look at what happened in Airbnb when they moved from standard machine learning approaches to deep learning. It’s written in a very approachable style and packed with great insights. I hope you enjoy it as much as I did!
Ours is a story of the elements we found useful in applying neural networks to a real life product. Deep learning was steep learning for us. To other teams embarking on similar journeys, we hope an account of our struggles and triumphs will provide some useful pointers.
An ecosystem of models
The core application of machine learning discussed in this paper is the model which orders available listings according to a guest’s likelihood of booking. This is one of a whole ecosystem of models which contribute towards search rankings when a user searches on Airbnb. New models are tested online through an A/B testing framework to compare their performance to previous generations.
The time is right
The very first version of search ranking at Airbnb was a hand-written function.
Replacing the manual scoring function with a gradient boosted decision tree (GBDT) model gave one of the largest step improvements in homes bookings in Airbnb’s history.
There were many successful iterations of that approach to follow, but eventually performance saturated and it was hard to make any further improvements. “This made the moment ripe for trying sweeping changes to the system.”
You need to be this tall
Note that the Airbnb team already had experience with machine learning, data pipelines in place, and an online controlled experiment platform available. From this foundation, they took their first steps towards neural networks.
For teams started to explore machine learning, we would recommend a look at ‘Rules of machine learning’ as well.
Is it worth it?
Airbnb moved from their starting point with a Gradient Boosted Decision Tree (GBDT) model towards deep neural networks in stages. Overall, the transition was “one of the most impactful applications of machine learning at Airbnb.” The charts below show the improvements over time in the key offline metric, normalised discounted cumulative gain (NDCG), and in gains in bookings achieved online with the deployed models.
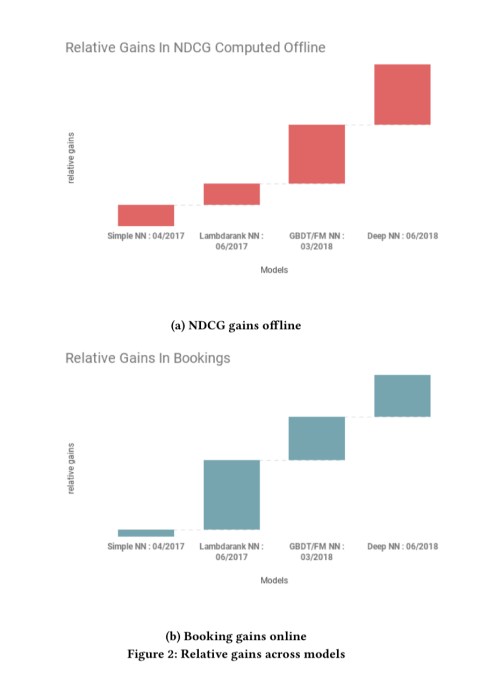
Of course this version of the truth edits out of all the detours and failed attempts along the way: “Reality is studded with unsuccessful attempts that outnumber the successful ones…”
Don’t be a hero
Andrej Karpathy has advice regarding model architecture: don’t be a hero. Well, that’s not how we started…
But after a few aborted attempts, the first neural network model deployed to production was a simple one with a single hidden layer with 32 fully-connected ReUL activations. It proved neutral on booking performance when compared with the previous GBDT model. It wasn’t a wasted exercise though:
The value of the whole exercise was that it validated that the entire NN pipeline was production ready and capable of serving live traffic.
Don’t be a hero, in the beginning
Not being a hero got us off to a start, but not very far. In time we would adapt Kapathy’s advice to: don’t be a hero, in the beginning.
The first big breakthrough in booking gains came by combining the NN with ideas from Lambdarank. Whereas the original NN used the same features as the GDBT model, “Lambdarank gave us a way to directly optimize the NN for NDCG.”
The Lambdarank model used pairs of {booked, not-booked} examples as inputs to training, and weighed each pairwise loss by the difference in NDCG resulting from swapping the ordering in the pair. The end result was that booked listing tended to move towards the top of the search results.
Let’s use all the things
The success path documented in this paper is based on neural network models, but there were other models under investigation as well. These gave similar end performance in some cases, but the listings that they up-ranked were quite different. So the next iteration tried to combine the strengths of the NN approach with features from the GBDT model and a factorization machine model as additional inputs.
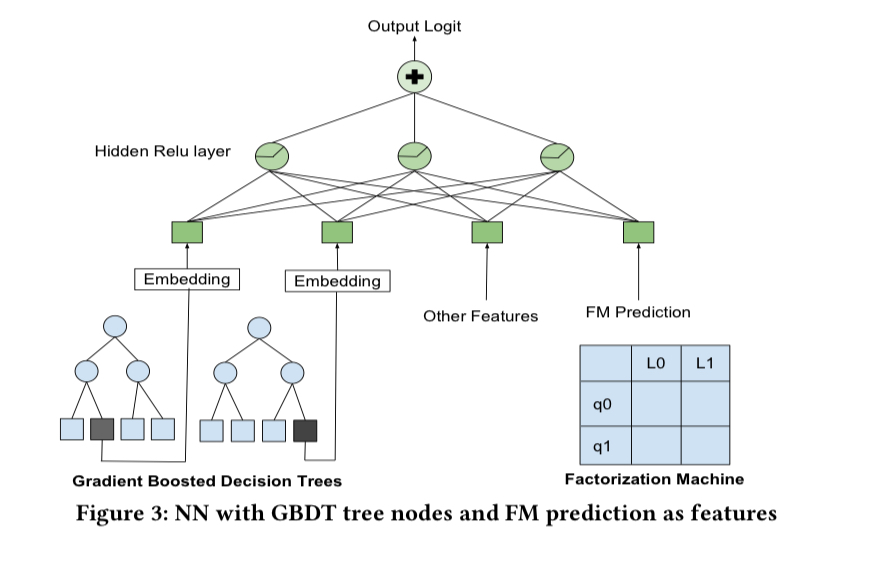
It did give a boost in bookings, but at a cost.
The complexity of the model at this point was staggering, and some of the issues mentioned in ‘Hidden technical debt in machine learning’ began to rear their heads.
(See also the related ‘Machine Learning: the high-interest credit card of technical debt’.)
Dump the complexity
In our final leap, we were able to deprecate all that complexity by simply scaling the training data 10x and moving to a DNN with 2 hidden layers.
(So not that deep really!)
But it was comparatively wide compared to the first versions: an input layer with 195 features, feeding a first hidden layer with 127 fully connected ReLUs and a second hidden layer with 83 fully connected ReLUs.
Feeding the model
Running alongside the evolution in model architectures there was a corresponding evolution in the features fed into those models.
In our very first attempt at training a NN, we simply took all the features used to train the GBDT model and fed it to the NN. This went down very badly.
The first improvement came from applying feature normalisation (GDBTs aren’t especially sensitive to exact numeric values, but NNs are). This mapped features into a small range of values largely in {-1,1} with the median at 0.
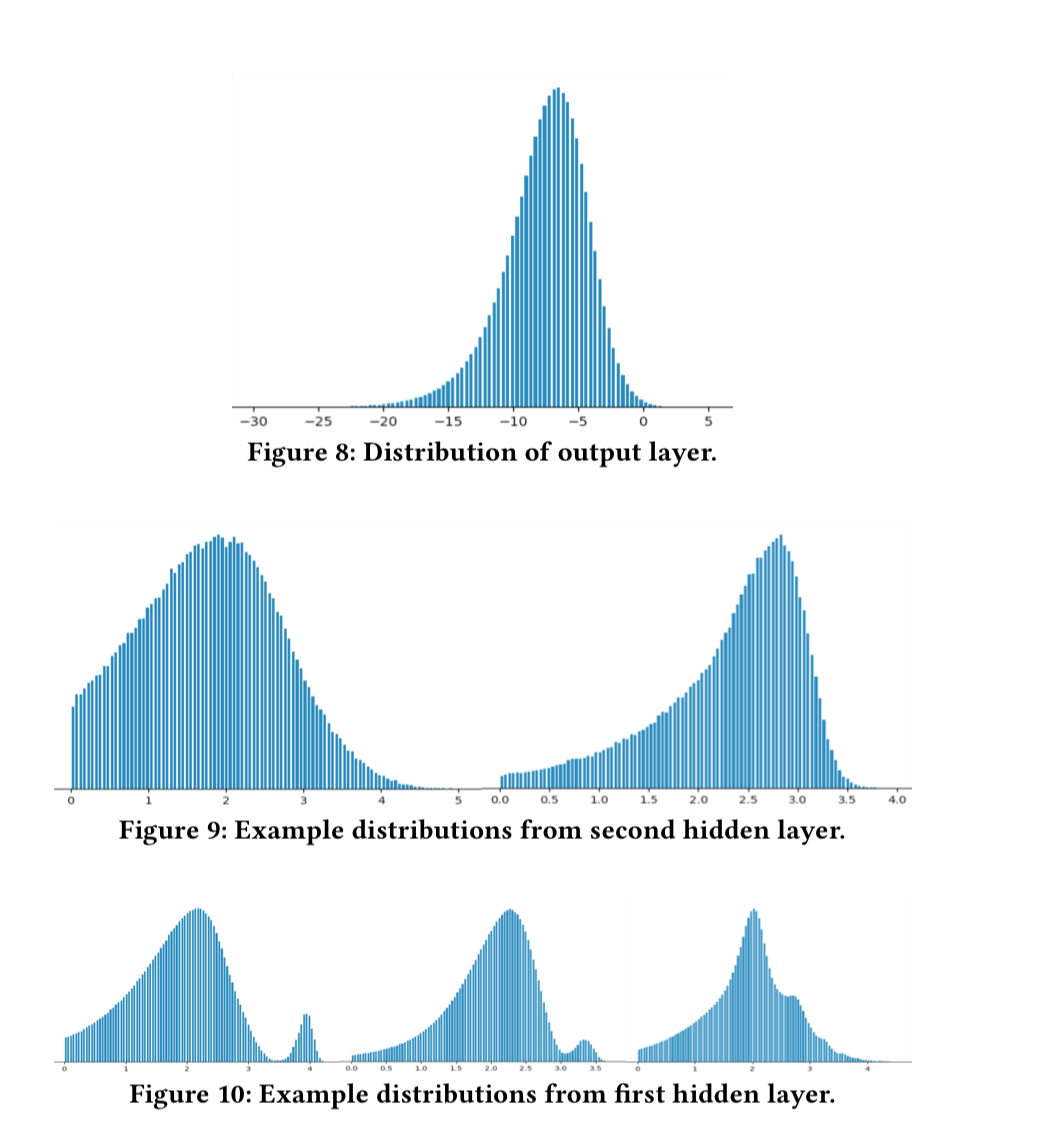
The next big improvement came from ensuring that the distributions of these features were smooth. Striving for smooth distributions helped with spotting bugs, encouraging generalisation, highlighting areas where a little more feature engineering would be useful, and uncovering additional features a model may be missing.
Answering exactly why DNNs are good at generalizing is a complicated topic at the forefront of research. Meanwhile, our working knowledge is based on the observation that in the DNNs built for our application, the outputs of the layers get progressively smoother in terms of their distributions… The smooth distributions coming from the lower layers ensure that the upper layers can correctly ‘interpolate’ the behavior for unseen values. Extending this intuition all the way to the input layer, we put our best effort to ensure the input features have a smooth distribution.
Tuning the model
Neural networks bring with them a large hyperparameter space to explore. In the end, simple worked best at Airbnb.
For our application, we found it hard to improve upon the performance of Adam with its default settings… Having swept the learning rate issue under the LazyAdamOptimizer carpet, we just opted for a fixed batch size of 200 which seemed to work for the current models.
Understanding the model
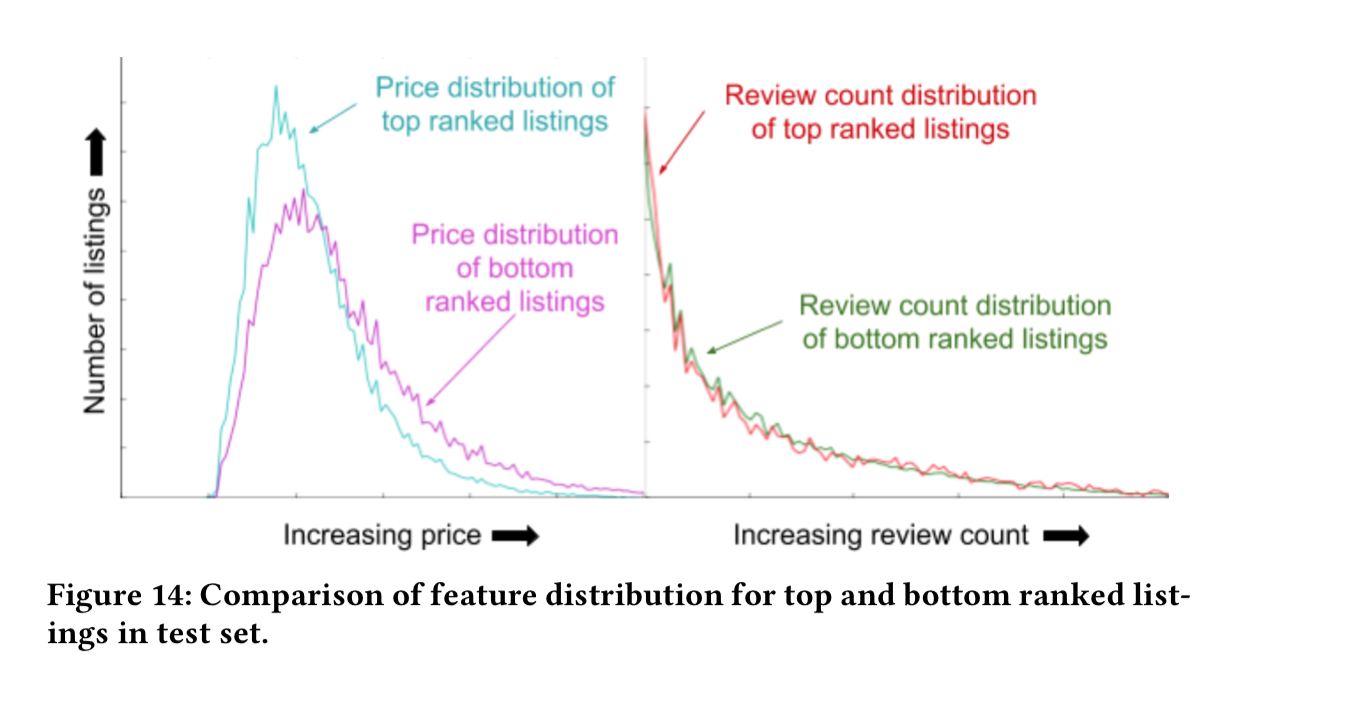
One of things that became harder with the move to NNs was understanding what the model was actually doing and why. After trying a variety of tactics, thing that worked best for Airbnb was a home-grown tool called TopBot, a top-bottom analyser. TopBot compares distribution plots of feature values from listings ranked highly to the distribution plots of feature values from listing ranked at the bottom. This comparison highlights how the model is utilising features in the different value ranges.
For example, the plots below show the sensitivity of the model to price, but also reveal that this version of the model was not utilising reviews as expected.
Benefits and learnings
Moving to deep learning is about more than just changing the internals of your model, it’s also a change of scale. “As a result, it required rethinking the entire system surrounding the model.”
So would we recommend deep learning to others? That would be a wholehearted Yes. And it’s not only because of the strong gains in the online performance of the model. Part of it has to do with how deep learning has transformed our roadmap ahead. Earlier the focus was largely on feature engineering, but after the move to deep learning, trying to do better math on the features manually has lost its luster. This has freed us up to investigate problems at a higher level, like how can we improve our optimization objective, and are we accurately representing all our users?
Two years in, the team at Airbnb are just getting started…

What I don’t like about their Figure 2 is that the “old and worse” model is always measured in March-April. The “new and improved” model is always measured in June. When do you think people make more bookings on AirBnB, March/April or June? The answer could easily be June, just in time for the July/August vacation peak…
In any case, given strong seasonal variations in bookings, I don’t know how much I can trust their Figure 2. Also, it could be that AirBnB is just getting more and more popular with each passing month, so the numbers would have gone up regardless if they deployed the new model or stayed with the old one… What they should have done is deploy a new model for some population of customers and let others use an old one, and test both populations at the same time. Without such experimental rigour, it’s hard to tell if the improvements are due to new models or other external factors.
I agree with Sasha. The analysis of temporal correlation is not shown here. Even though the data modeling pipeline is solid here, but I do not really get the point about the model comparison without dealing with their error (residual) variation.
What surprises me about Figure 2 is that the “old and worse” model is always measured in March-April. The “new and improved” model is always measured in June. When do you think people make more bookings on AirBnB, March/April or June? The answer could easily be June, just in time for the July/August vacation peak…
In any case, given strong seasonal variations in bookings, I don’t know how much I can trust their numbers. Also, it could be that AirBnB is just getting more and more popular each month, so the numbers would have gone up regardless if AirBnB deployed the new model or stayed with the old one… I wish the authors had deployed a new model for some population of customers, let others use an old one, and test both populations at the same time.
If it’s A/B testing, like it is mentioned at the beginning, the data with old/new algo should be collected in parallel during the same period of type. But you are right, that A/B tests done with different models at different time periods could be biased due to reasons you have pointed. So, correct comparison of different models should be done testing them all in parallel at the same period of time.