Experiences with approximating queries in Microsoft’s production big-data clusters Kandula et al., VLDB’19
I’ve been excited about the potential for approximate query processing in analytic clusters for some time, and this paper describes its use at scale in production. Microsoft’s big data clusters have 10s of thousands of machines, and are used by thousands of users to run some pretty complex queries. These clusters are in high demand and approximate query processing both saves their users time and lightens the overall load on the cluster.
What’s especially nice about this paper is that we get a glimpse into the practical adoption issues of persuading users that it’s ok to approximate too.
We have implemented support for query time sampling in production big-data clusters at Microsoft: these clusters consist of tens of thousands of multi-core, multi-disk servers and are used by developers from many different businesses including Bing, Azure, and Windows. In total, the clusters store a few exabytes of data and are primarily responsible for all of the batch analytics at Microsoft.
Approximate query support
Control over approximation is put into the hands of the user via extensions to the query language. In particular, support for expressing sampling requirements as part of SELECT statements. For example, here’s the original ‘query #5’ from TPC-H:

And here’s a rewritten version that uses uniform sampling over rows:

Three different sampling operators are supported:
UNIFORM(p)selects rows uniformly at random with probability p.UNIVERSE(p,D)finds all the distinct values in column D, then selects column values uniformly at random from among them with probability p. All rows with selected values are output.DISTINCT(p, D, f)ensures that at least f rows are output for every distinct value in column D. If the original dataset has more than f rows for a given column value, the additional rows are output with probability p.
A small example might help bring this to life. In the table below the ticks represent rows that might be selected by the different sampling operators.
| Col1 | Col2 | Uniform(0.5) | Universe(0.5, Col2) | Distinct(0.5, Col2, 1) |
| ABC | 123 | ✅ | ✅ | ✅ |
| DEF | 123 | ✅ | ||
| GHI | 123 | ✅ | ✅ | ✅ |
| JKL | 456 | |||
| MNO | 456 | ✅ | ✅ | |
| PQR | 456 | ✅ | ||
| STU | 456 | ✅ | ||
| VWX | 456 | ✅ | ✅ | |
| YZ | 789 | ✅ | ✅ | |
| BCA | 012 | ✅ | ✅ |
The Universe sampler works well when being pushed down in the query plan below a join. It has the property that joining the universe samples of two relations is identical to taking the same (selected column values) sample of the join result.
The Distinct sampler is a bit more expensive to implement, but has the property that we’ll get an output for every distinct value when using e.g. a GROUP BY.
All three sampling strategies are heavily used at Microsoft.

Use cases
Microsoft are running hundreds of sampled jobs every day. The median query has in excess of 10 SQL-like SELECT statements, but some queries may have several hundred!
We see that at least 50% of the jobs take over 60 hours of execution time, read over 10TB of data, and write over 100GB. A sizable fraction of the jobs are much larger.
What are all these jobs doing??
- There is the classic approximate query processing use case of aggregate queries for decision support. Queries seen in this category may contain groups with tens of columns, and user-defined filters, aggregations, projections, joins and group-bys.
- Creating training datasets for machine learning! The sampling operators turn out to be great for creating training and test datasets with desired properties.
More complex usages include dividing the dataset into silos (e.g. based on predicates over some feature values), sampling each silo with a different probability and then union’ing the results. We believe that the user goal here is to construct representative training sets to ensure that the learnt models are not biased towards just the more frequent samples.
- Explicit output sampling – for example to create a smaller representative version of an output so that it can be used for human analysis or as an input into desktop-scale tools.
The authors also observed explicit sampling jobs that perform some complex and detailed computation on a sampled relation, without ever correcting for the effect of sampling. Here the assertion is that users are sampling with some intent other than approximating the results of an unsampled query. Could some of them just be users getting it wrong though??
For jobs that do use sampling, nearly all of them are recurring. Perhaps this is where the biggest payback comes in return for investing in building sampled versions of queries. It’s also where users can have the greatest confidence in the sampled outputs though – because they have historical trends and data to compare them to.
Implementation
Individual samplers need to be built to be high throughput and memory efficient. Uniform and Universe samplers are fairly straightforward in this regard. The Distinct sampler is a little more complex as it needs to maintain some state – for which the current implementation uses a heavy hitter sketch.
The higher-order bit though is not just making the individual samplers fast, but making sure you sample at the right point in the query plan:
Using these sample operators, queries will see a sizable improvement in cost and latency only if substantial work executes in the query plan after the samplers; that is, samplers execute early in the query plan and subsequent operators benefit from working on smaller sampled relations. Hence, query optimizer transformations which push samplers down without affecting plan accuracy can improve performance.
Plan transformation rules are used to push samplers down in query plans without affecting accuracy. Here, “two query expressions are said to be equivalent if every subset of rows in the output relation has the same probability of occurring in either expression.” There are three groups of rules for pushing samplers below projection, selection, and joins respectively (see §2.2 in the paper).
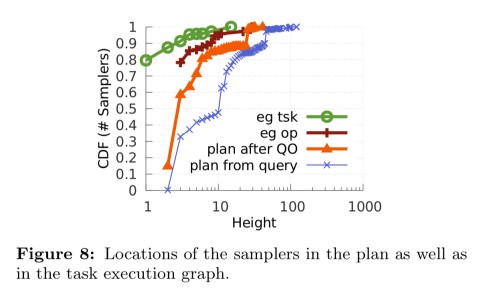
Comparing the ‘plan from query’ and ‘plan after query optimisation’ lines in the CDF below you can see the effect of the optimisation in the increased depth of sample operators.
Benefits
The paper presents results on TCP-H (which looks a bit like a toy compared to the real production queries, but is useful for comparison), as well as from some production-like queries.
8 out of the 22 TPC-H queries cannot be advantaged by sampling. Of the other 14 all but one improve. The exception, query #6 does not do enough work after the sampling to benefit. Five queries improve substantially on both latency and total compute hours. Analysis suggests that the change in TPC-H answer quality is insignificant.
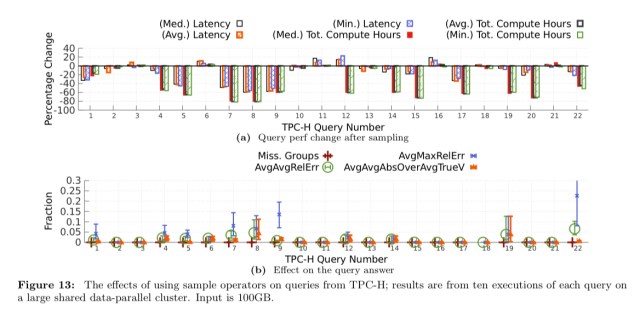
Note that this result has zero overhead; that is, no apriori samples or indices need to be maintained, no other relational operators have to change, and there is no constraint on how input is partitioned or stored.
For the larger more production-like query analysed in §4.2.1, the sampled job consumes 2,000 fewer cluster hours and finishes roughly 3 hours earlier. The accuracy was considered adequate by the developer.
Such case studies lead us to strongly believe that the batched log analytics jobs that are prevalent in production big-data clusters can benefit substantially from query-time sampling.
Persuading users to approximate
Despite all these benefits, it’s interesting to note that end-users are cautious in their adoption of sampling. The more data-science literate users are more comfortable with it, but in general:
Whether or not users will use approximations, in some sense, appears akin to a religious belief; user who hesitate initially will often remain unconvinced with logical explanations.
During his talk at VLDB, Kandula explained that this is despite tactics such as dual-running of sampled and unsampled queries, or e.g. running sampled queries most days and an unsampled query once a week.
One issue is with queries whose outputs are consumed downstream by another group or groups. Introducing sampling here requires coordinated discussion of answer quality across multiple groups. Another issue is simply finding the time and motivation to go in and change an already working script / query. Wielding a stick helps:
Efficiency mandates which force groups to reduce their cluster usages (and long queues in backlogged clusters) were often a good motivation for users to consider approximations.
What next?
Currently the team at Microsoft are focusing on improvements in two main directions:
- Encouraging adoption / ease of use:
- Support for automatically injecting sample operators into recurring job queries where fine-grained statistics are available to guide the process.
- Automatically rewriting aggregates to add confidence intervals or other a posteriori error estimates
- Further improving the performance of sampling, for example with a richer set of pushdown rules
Further reading on this topic: “Trading off accuracy for speed in PowerDrill” Buruiană et al., ICDE’16 (PowerDrill is a Google internal system).

One thought on “Experiences with approximating queries in Microsoft’s production big-data clusters”
Comments are closed.