Choosing a cloud DBMS: architectures and tradeoffs Tan et al., VLDB’19
If you’re moving an OLAP workload to the cloud (AWS in the context of this paper), what DBMS setup should you go with? There’s a broad set of choices including where you store the data, whether you run your own DBMS nodes or use a service, the kinds of instance types to go for if you do run your own, and so forth. Tan et al. use the TPC-H benchmark to assess Redshift, Redshift Spectrum, Athena, Presto, Hive, and Vertica to find out what works best and the trade-offs involved.
We focused on OLAP-oriented parallel data warehouse products available for AWS and restricted our attention to commercially available systems. As it is infeasible to test every OLAP system runnable on AWS, we chose widely-used systems that represented a variety of architectures and cost models.
My key takeaways as a TL;DR:
- Store your data in S3
- Use portable data format that gives you future flexibility to process it with multiple different systems (e.g. ORC or Parquet)
- Use Athena for workloads it can support (Athena could not run 4 of the 22 TPC-H queries, and Spectrum could not run 2 of them), especially if you are doing less frequent ad-hoc queries.
Which I’m quite happy to see as my most recent data pipeline is based around Lambda, S3, and Athena, and it’s been working great for my use case.
The design space
We group the DBMS design choices and tradeoffs into three broad categories, which result from the need for dealing with (A) external storage; (B) query executors that are spun on demand; and (C) DBMS-as-a-service offerings.
With regard to external storage, you could use S3 with remote storage accessible over a REST API, or block-based storage with EBS and Instance Store (InS), with EBS being the closest match for traditional database systems. InS does now offer an NVMe variant too, and the authors perform limited testing on that as well.
For query executors that can be frequently started and stopped the authors explore performance with cold and warm caches (where applicable), and also the horizontal and vertical scaling performance.
For the as-a-service offerings, what levels of flexibility do they offer compared to running your own systems, and how do they compare on cost?
The test
The tests were done using 1000 scale factor TPC-H data (1TB uncompressed) – large enough to be I/O constrained yet still enabling queries to complete in seconds to minutes. Each systems begins from a cold start unless explicitly stated otherwise in the results. For S3 tests, data was stored in ORC format, apart from for Vertica which used its own proprietary format.
For those systems where you provide your own compute instances, the default configuration tested used a 4-node r4.8xlarge cluster with 10Gb/s networking.

For cost calculations, the costs are a combination of compute costs, storage costs, data scan costs, and software license costs.
Key findings
The experimental results focus on six main areas of comparison:
- query restrictions
- system initialisation time
- query performance
- cost
- data compatibility with other systems
- scalability
Query restrictions
Neither Spectrum nor Athena could run the full TPC-H query suite. On Athena, Q2 timed out after an hour, and Q8, Q9 and Q21 failed after exhausting resources. On Spectrum, Q15 failed because views are not supported, and Q22 failed because complex subqueries are not supported. (See §2.4 in the TPC-H Benchmark Standard for details of the queries).
System initialisation time
Initialisation time measures how easy it is to launch and use a given DBMS (doesn’t apply to Athena, which is ‘always-on’).
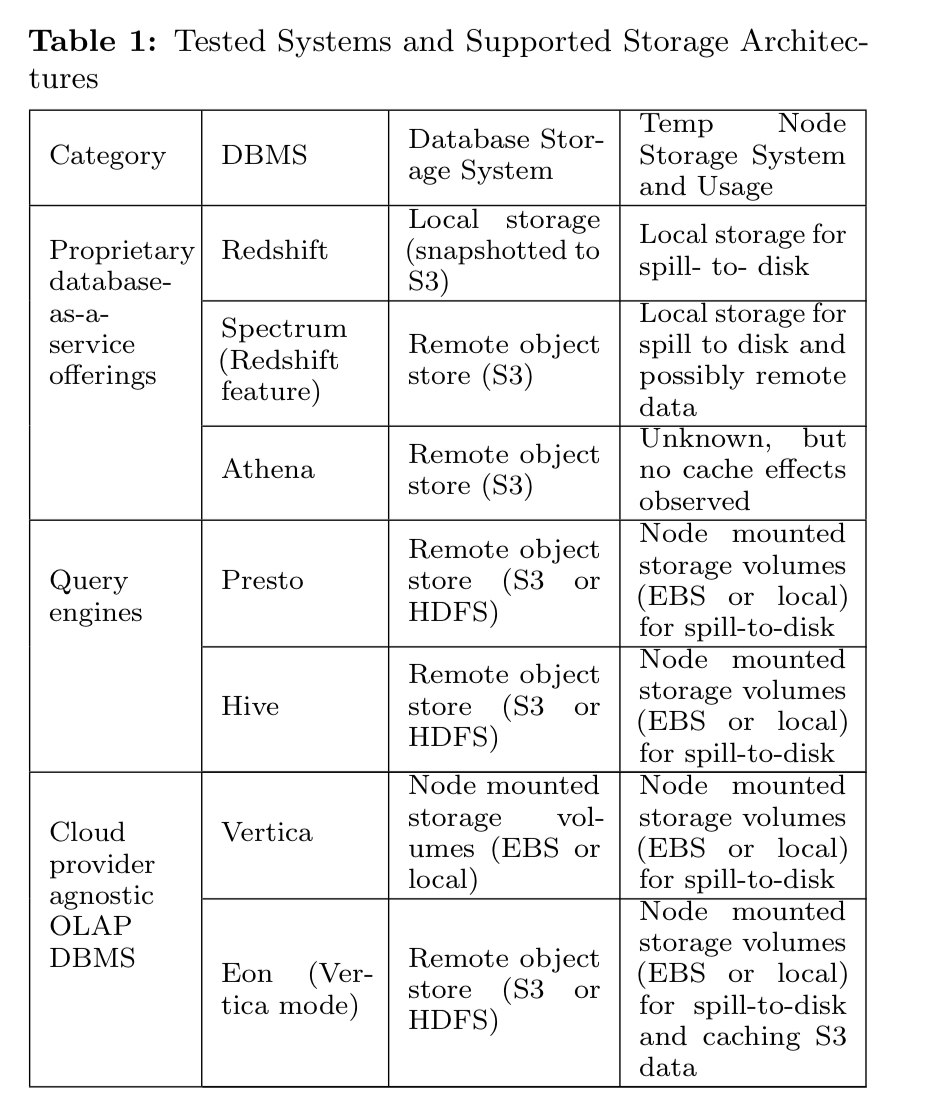
Most systems have initialisation times in the range of 5-7 minutes, with Redshift an outlier at around 12 minutes.
It is advantageous in the cloud to shut down compute resources when they are not being used, but there is then a query latency cost. All cloud nodes require time to initialize and pass system checks before a DBMS can be started, with systems using local storage like Redshift taking longest to initialize. Serverless offerings like Athena provide an alternative “instant on” query service.
Query performance
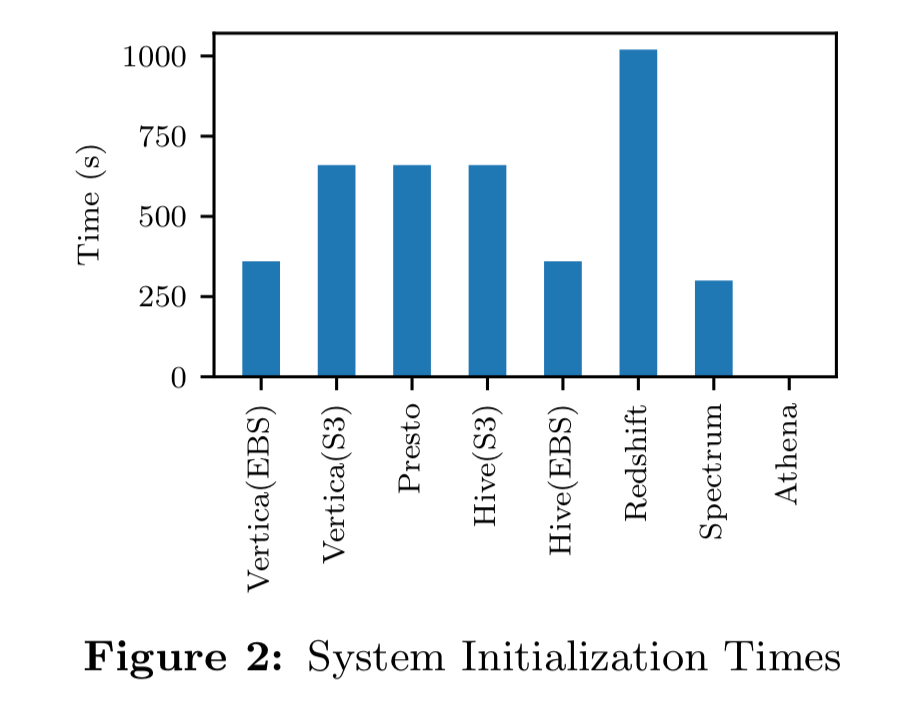
Query performance is measured from both warm and cold caches. Of the 16/22 queries that can be run across all of the system under test, Athena and Redshift are the best performers (though interestingly, not Redshift Spectrum).
If you can afford to keep it running (no initialisation costs on subsequent queries), and with a warm cache, Redshift offers the best performance for frequent querying. The warm cache benefits across the board are not as great as might be expected, but this is a characteristic of the workload where most queries are not I/O bound and those that are tend to be shorter.
Another interesting experiment here compared the effects on performance of different storage types.
In general, InS performance is faster than EBS, and EBS is faster than S3 on the same system, as expected. However, the magnitude of the difference may be exaggerated depending on how well that system utilizes a specific storage type.
The results found that there is a performance advantage from faster storage, but it’s not as big as you might think.
Using cheap remote object storage instead of more expensive EBS block storage seems fine, and even on heavily I/O bound workloads the cost advantage of S3 far exceeds its performance disadvantage.
Cost
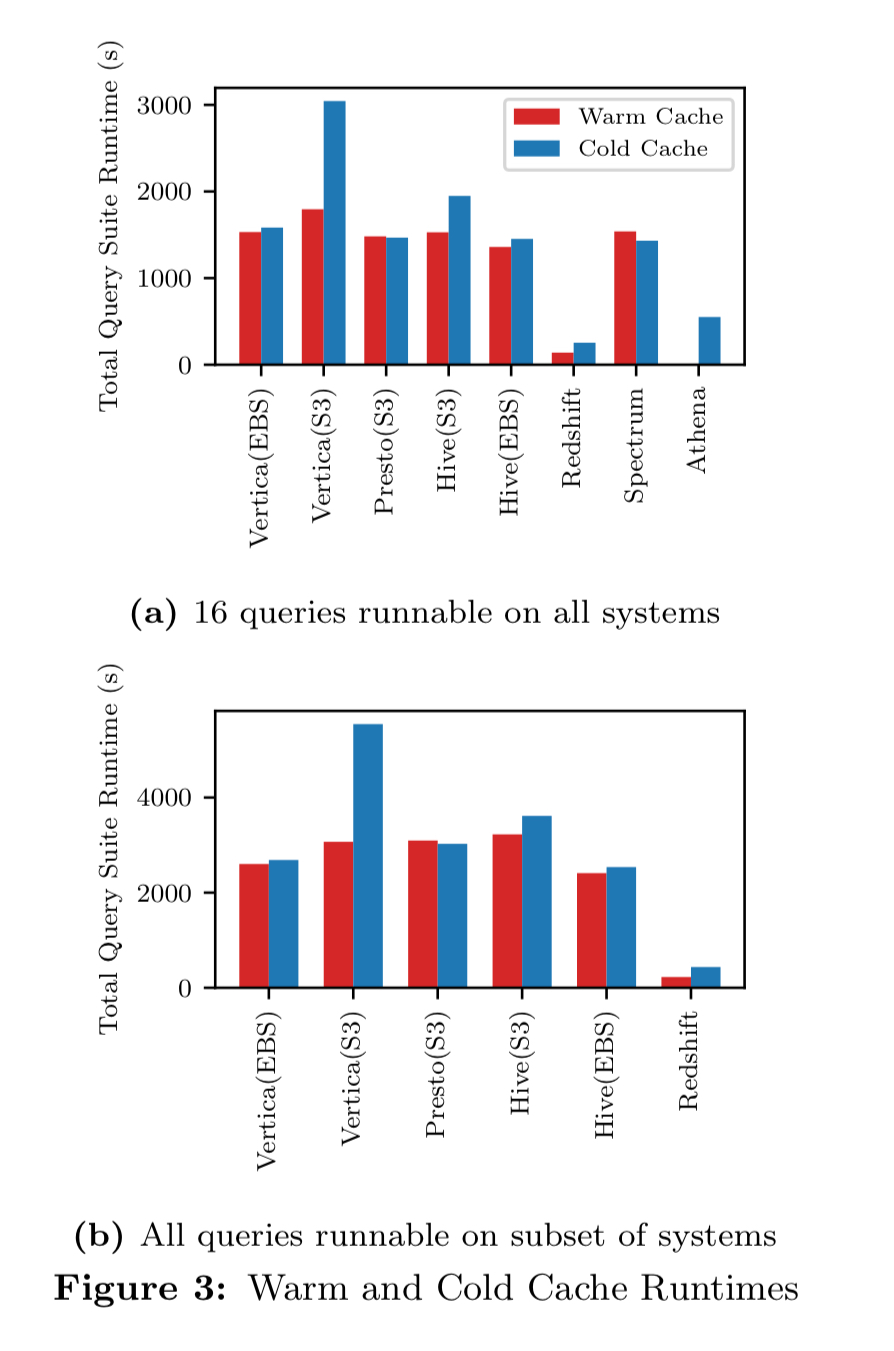
The following charts show the query costs for both cold start and subsequent runs:
Redshift Spectrum stands out as the expensive option here! “Redshift is not a cost-effective system if one relies heavily on pulling data from S3.“
Athena’s cost-per-query is on a par with other systems, which coupled with its good query performance gives it very competitive cost/performance.
Therefore, a cloud DBMS user should consider Athena as an option for select workloads and utilize storage that can be accessed by serverless options.
When it comes to the storage part of the cost equation, using EBS is much more expensive than S3. “Our setup found a 50x storage cost increase for EBS while only providing a 2x performance speedup.“
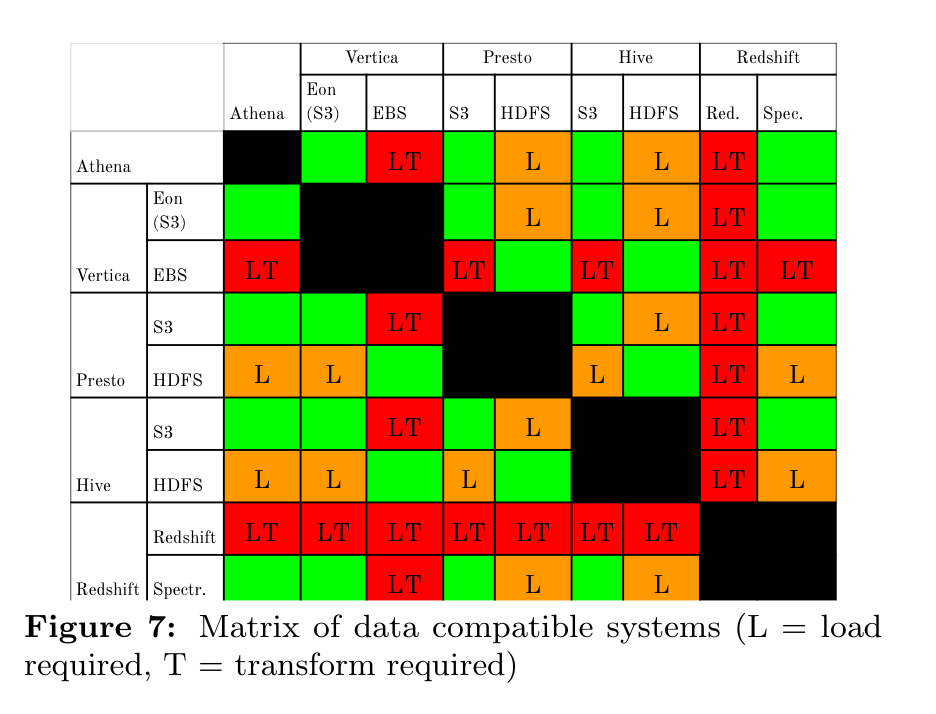
Data compatibility
Because the cloud offers the ability to easily launch new systems, being able to leverage different systems for different workloads is advantageous. However, ETL costs can make some system types infeasible to use when workloads change, thereby limiting the cloud offerings one can leverage.
Green cells in the compatibility matrix below show where systems can use compatible formats from the same storage system, e.g. ORC on S3.
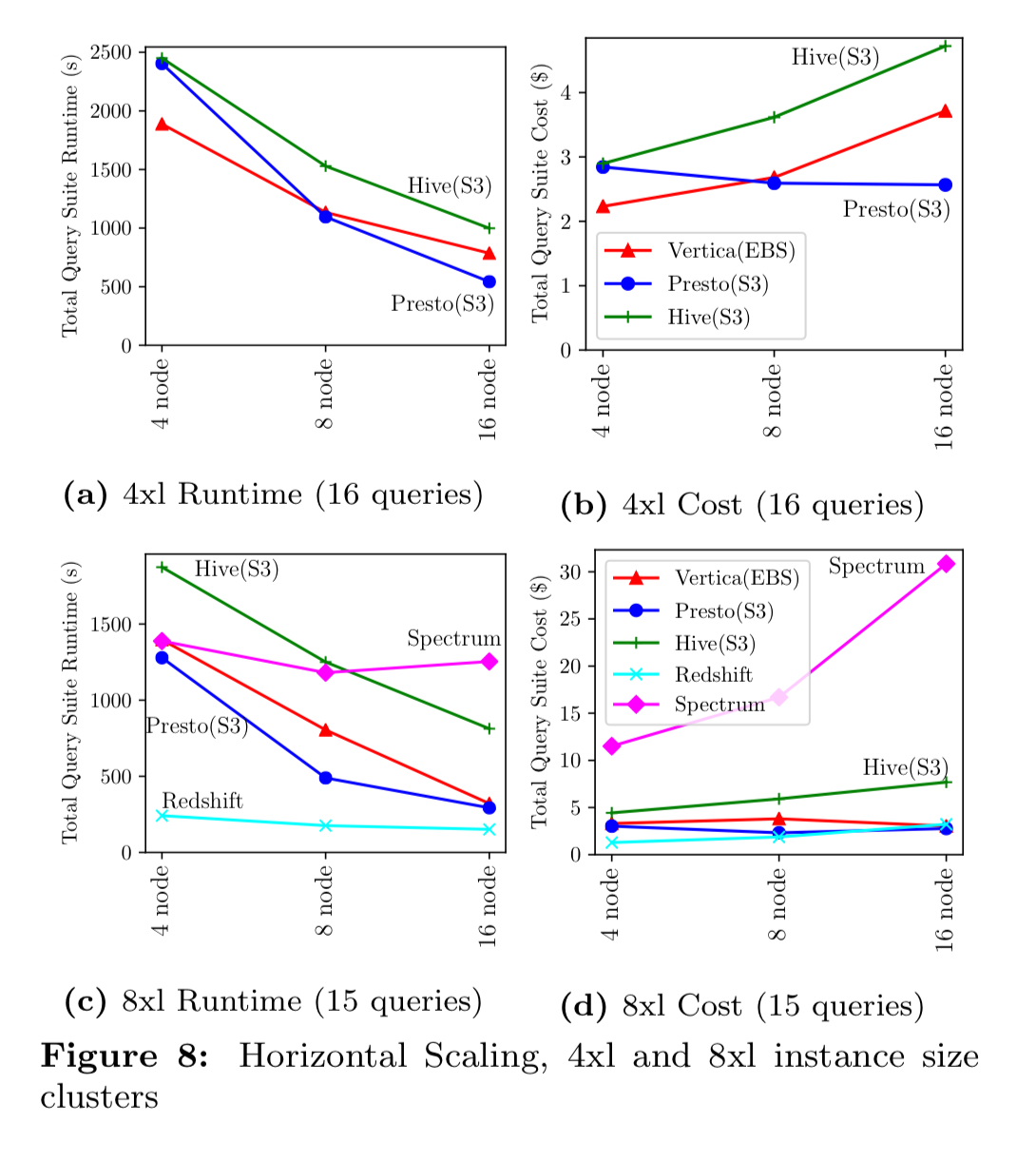
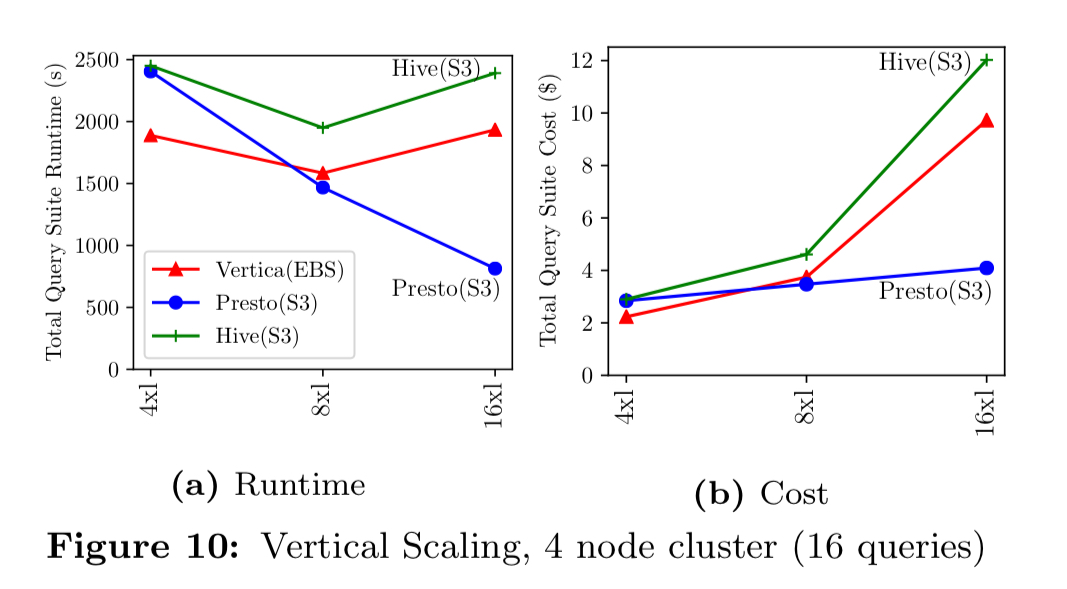
Scalability
We analyzed performance when scaling horizontally and vertically… The main theme is that horizontal scaling is generally advantageous, while vertical scaling is generally disadvantageous.
Scaling tests on AWS proprietary system are limited by the options they provide to the end user.
The last word
Each of these findings poses opportunities for future work to explore specific architectural tradeoffs further. Additionally, future studies could analyze concurrency, test a different suite such as TPC-DS, evaluate different data sizes, and evaluate more systems.

I don’t understand how these compare to AWS RDS with more traditional Relational Databases like Postgres or MySQL. Not sure if it’s in the scope of this article but why would you chose this approach (e.g. S3 + Athena) over a PostgresSQL instance on RDS? Is it cheaper since the query engine is running outside of the Database Nodes?
Thanks!
I don’t understand how these compare to AWS RDS with more traditional Relational Databases like Postgres or MySQL. Not sure if it’s in the scope of this article but why would you chose this approach (e.g. S3 + Athena) over a PostgresSQL instance on RDS? Is it cheaper since the query engine is running outside of the Database Nodes?
Thanks!