Three key checklists and remedies for trustworthy analysis of online controlled experiments at scale Fabijan et al., ICSE 2019
Last time out we looked at machine learning at Microsoft, where we learned among other things that using an online controlled experiment (OCE) approach to rolling out changes to ML-centric software is important. Prior to that we learned in ‘Automating chaos experiments in production’ of the similarities between running a chaos experiment and many other online controlled experiments. And going further back on The Morning Paper we looked at a model for evolving online controlled experiment capabilities within an organisation. Today’s paper choice builds on that by distilling wisdom collected from Microsoft, Airbnb, Snap, Skyscanner, Outreach.io, Intuit, Netflix, and Booking.com into a series of checklists that you can use as a basis for your own processes.
Online Controlled Experiments (OCEs) are becoming a standard operating procedure in data-driven software companies. When executed and analyzed correctly, OCEs deliver many benefits…
The challenge with OCEs though, as we’ve seen before, is that they’re really tricky to get right. When the output of those experiments is guiding product direction, that can be a problem.
Despite their great power in identifying what customers actually value, experimentation is very sensitive to data loss, skipped checks, wrong designs, and many other ‘hiccups’ in the analysis process… Bad data can be actively worse than no data, making practitioners blinded with pseudoscience.
The checklists in this paper are designed to help you avoid those pitfalls and maximise your chances of success:
In this paper, based on synthesized experience of companies that run thousands of OCEs per year, we examined how experts inspect online experiments. We reveal that most of the experiment analysis happens before OCEs are even started, and we summarize the key analysis steps in three checklists.
The experiment lifecycle
Once an experimentation culture embeds itself with a team, then a continuous cycle of experimentation emerges. During ideation a set of proposed changes are generated and considered for evaluation. The chosen ideas are transformed into experiments which are first designed and then executed. Once the experiment is over, an analysis and learning phase examines and interprets the results. This may in turn generation more ideas for the next ideation cycle…
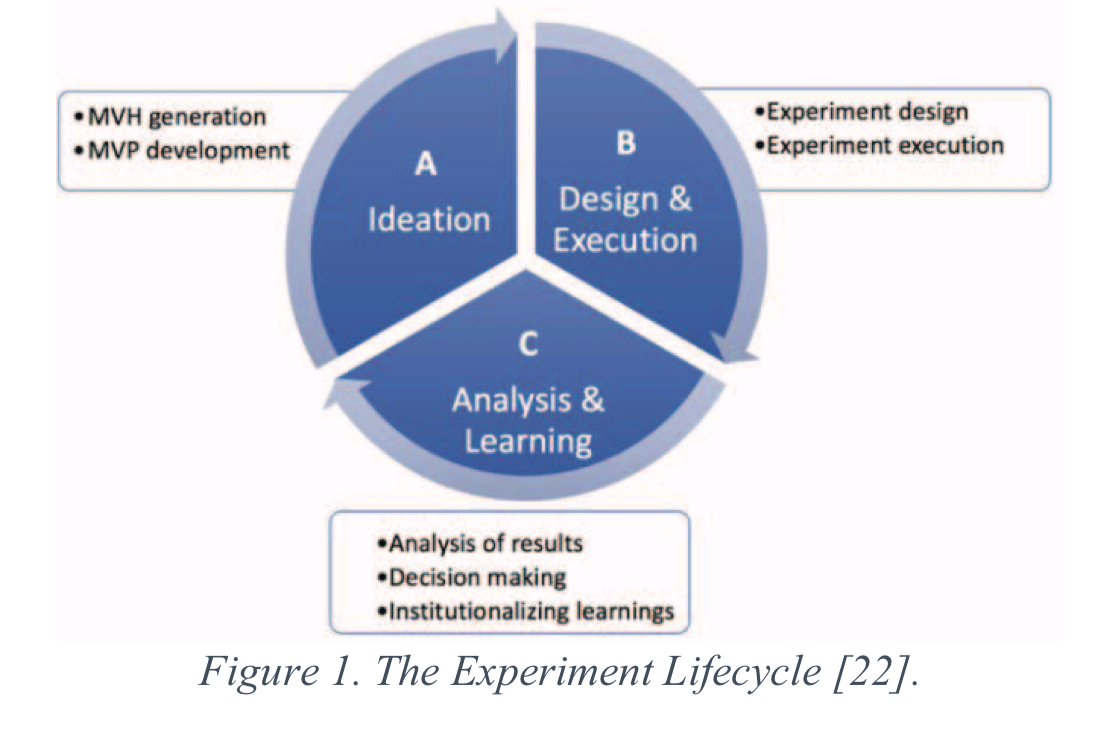
The three main checklists in this paper cover experiment design, experiment execution, and experiment outcome analysis.
Experiment design analysis checklist
- Experiment hypothesis is defined and falsifiable
- Experiment design to test the hypothesis is decided
- Metrics and their expected movement are defined
- Required telemetry data can be collected
- The risk associated with testing the idea is managed
- The minimum size effect and OCE duration are set
- Overlap with related experiments is handled
- Criteria for alerting and shutdown are configured
- Experiment owners for contact are known
- Randomisation quality is sufficient
Starting with the hypothesis,
Every change for testing should be introduced with a description of what the change that will be evaluated is, who will see the change, what the expected impact is, and how this impact is connected to the top-level business goals. Most importantly, an impact analysis should contain a line of reasoning— belief— that explains why a change is expected to have an impact.
A good template for formulating the hypothesis is: “Based on [qualitative/quantitive] insight, we predict that [change X] will cause [impact Y].”
The simplest experiment design is the single factor OCE, where one change to the product is being applied in the treatment group. Other experiment designs are available.
Metrics for the experiment should include not only the direct metrics of the feature under test, but also data quality metrics, guardrail metrics, and business success metrics.
Experiment analysis should contain a minimum effect size – the minimum Δ% in the metrics of interest that we care about detecting due to the new feature or change in the code, as well as the duration of the experiment. This is a trickier problem than it seems…
The smaller the minimum effect size (not the same as the expected effect size) we want to reliably detect, the more data we need and hence the longer the experiment will need to run. Given minimum effect size and standard deviation (estimated based on historical data), experiment duration can be determined using a standard statistical formula. Most important to note is that we’re figuring out up front how long the experiment needs to run for – not just firing it up and stopping the minute the results seem encouraging, that way leads to trouble!
Care must be taken to correctly randomise users into experiment variants in the presence of poor instrumentation, data loss, and various corner cases (e.g. null ids, churn, …). You should validate that your randomisation is working correctly via a series of A/A tests.
Experiment execution analysis checklist
- No serious data quality issues are present
- The experiment is not causing excessive harm
- The possibility of early stopping is evaluated
While the experiment is executing it needs to be continuously monitored. If data quality metrics start to go off, the whole result of the experiment is in jeopardy.
…data quality tests can be executed on the collected data. One such test is the simple Sample Ratio Mismatch (SRM) which utilizes the Chi-Squared test to compared the ratio of the observed user counts in the variants against the configured ratio.
The guardrail and key success metrics need to be monitored to ensure the experiment is not causing excessive harm. If degradation exceeds some threshold (which you decided ahead of time in step 8 of the experiment design checklist), then the experiment should be stopped.
A good practice for technically demanding experiments that may be hard to rollback instantly is to gradually increase the size of the treatment group and example metrics for large degradations at different stages, for example, after a few hours, a day, a week, etc..
(c.f. progressive delivery)
Early stopping is highly problematic and you should only do it if you really know what you’re doing: “we recommend relying on experimentation platform recommendations rather than leaving the issues in the hands of experimenters.”
Experiment debrief analysis checklist
- The experiment has sufficient power
- Data quality metrics are not negative
- Metrics are examined for selecting the winner
- Novelty effects are excluded
- In-depth analysis has been performed
- Skewed data is treated
- Coordinated analysis of experiments is done
- Validation of experiment outcome is conducted
- Experiment learnings are institutionalised
To ensure the results of the experiment can be trusted you need to verify (1) that you did indeed collect at least the required minimum number of units in the experiment variants, as calculated during step 6 of your experiment design, and (2) that the data quality metrics are not negative.
Given this, then feature metrics should be checked to ensure the feature is functioning as expected, success metrics should be evaluated to determine whether the feature results in long-term benefit, and guardrail metrics should be checked to ensure there are no negative impacts. Some changes can attract user attention in a positive way just through their novelty, but this effect may wear off over time. An analysis over time can help to detect this.
Experiments should also be analyzed in depth in order for interesting insights to be discovered, that could be used to iterate on the feature or provide ideas for new features. For example, although an experiment is neutral overall, one segment of users may have very positively reacted on the new feature, while another segment reacted negatively. These types of heterogeneous movements are common in experiments at scale and should be detected (see ‘Effective online experiment analysis at large scale’).
Part of this in-depth analysis should also be checking for outliers skewing the data.
If an experiment has only marginally impacted the metrics they should be executed again to validate the results, preferably with higher power.
At the end of the process, the learnings coming out of the experiment can be much richer than just whether or not a change has an impact on the product. A system for capturing and sharing all the learnings from experiments should be put in place, and ultimately well integrated into the experimentation platform.
Three signs your OCEs may be going awry
- Multiple experiments are being run with no coordination, including the potential for multiple concurrent experiments impacting the same part of a product. The recommended remedy is to appoint an Experiment Coordinator responsible for prioritising and scheduling experiments.
- A/A tests are consistently failing (or you aren’t running A/A tests at all). “Our advice is not to proceed with an A/B test if a series of A/A tests fails, but rather debug the experimentation system to discover the root cause.” One possible cause for this is technical differences in how the control and treatment are applied, independent of the treatment. For example, if the treatment involves an extra redirect step that the control doesn’t, treatment pages will load slower and as we have seen in previously papers, performance can have a significant impact on test results.
- Consistently failing to decide on a course of action after evaluating experiment results. Generally this points to a weakness in defining good success metrics (see ‘Measuring Metrics’ for advice on this). Making ship criteria explicit in the experiment design is another solution here.
Putting the checklists into practice
Section IV.E in the paper contains a short discussion on putting the checklists into practice. One of the key recommendations here is to automate as many of the checks as possible, and to make checklist item status highly visible.
The checklists in this paper should be seen as a starting point towards increasing the trustworthiness of experimentation in the software industry. However, similarly to checklists in other industries, they likely need to be adapted for the company that uses them.

Thanks, Adrian: this summary was a nice read. With the caveat that I have not read the full paper, these recommendations seem obvious from an applied statistics perspective, so it seems that the value of the paper is in giving a formalization of these best practices to a community of practitioners that lacks training in design of experiments. I’m curious now about what new statistical frontiers have been identified in design of experiments on the web scale.