RPCValet: NI-driven tail-aware balancing of µs-scale RPCs Daglis et al., ASPLOS’19
Last week we learned about the [increased tail-latency sensitivity of microservices based applications with high RPC fan-outs. Seer uses estimates of queue depths to mitigate latency spikes on the order of 10-100ms, in conjunction with a cluster manager. Today’s paper choice, RPCValet, operates at latencies 3 orders of magnitude lower, targeting reduction in tail latency for services that themselves have service times on the order of a small number of µs (e.g., the average service time for memcached is approximately 2µs).
The net result of rapid advancements in the networking world is that inter-tier communications latency will approach the fundamental lower bound of speed-of-light propagation in the foreseeable future. The focus of optimization hence will completely shift to efficiently handling RPCs at the endpoints as soon as they are delivered from the network.
Furthermore, the evaluation shows that “RPCValet leaves no significant room for improvement” when compared against the theoretical ideal (it comes within 3-15%). So what we have here is a glimpse of the limits for low-latency RPCs under load. When it’s no longer physically possible to go meaningfully faster, further application-level performance gains will have to come from eliminating RPCs altogether.
RPCValet balances incoming RPC requests among the multiple cores of a server. Consider for example a Redis server maintaining a sorted array in memory…
… an RPC to add a new entry may incur multiple TLB misses, stalling the core for a few µs while new translations are installed. While this core is stalled on the TLB miss(es), it is best to dispatch RPCs to other available cores on the server.
In theory, how fast could we go?
Consider a 16-core server handling 16 requests. We could put anywhere from 1 to 16 queues in front of those cores. At one extreme we have a ‘16 x 1’ architecture with 16 queues each with one associated processing unit. At the other extreme is a ‘1 x 16’ architecture with one shared queue serving all 16 processing units. Or we could have e.g. a ‘4 x 4’ with 4 queues each serving 4 units, and so on…
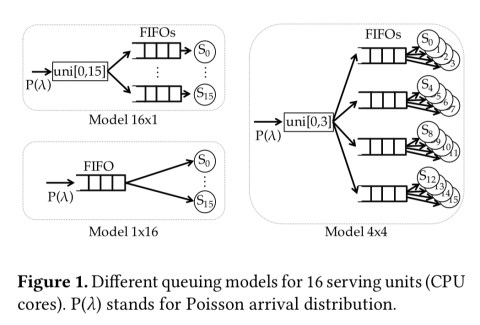
If you model that out with Poisson arrivals and variety of different service time distributions (fixed, uniform, exponential, and generalised extreme value, GEV) what you’ll find is that the ‘1×16’ architecture performs the best, and the ‘16×1’ architecture performs the worst.
1 x 16 significantly outperforms 16 x 1. 16 x 1’s inability to assign requests to idle cores results in higher tail latencies and a peak throughput 25-73% lower than 1 x 16 under a tail latency SLO at 10x the mean service time… The theoretical results suggest that systems should implement a queueing configuration that is as close as possible to a single queue (1 x 16) configuration.
In practice those models failed to account for a significant source of overhead: synchronizing across multiple cores on the single queue. When you take synchronisation into account, a dedicated queue per core starts to look like a good idea again. NICs supporting Receive-Side Scaling (RSS) can push messages into each core’s queue, but while RSS can help to achieve load distribution, it can’t truly achieving load balancing.
Any resulting load imbalance after applying these [RSS] rules must be handled by system software, introducing unacceptable latency for the most latency-sensitive RPCs with µs-scale service times.
Introducing RPCValet
RPCValet uses a push-based model, while also taking into account the current loading of the cores. It’s designed for “emerging architectures featuring fully integrated NIs and hardware-terminated transport protocols.”.
The key hardware feature is that the network interface has direct access to the server’s memory hierarchy, eliminating round trips over e.g. PCIe. Servers register a part of their DRAM into a partitioned global address space (PGAS), where every server can read and write memory in RDMA fashion. (We’re not given any details on system reconfiguration etc.).
An integrated NI can, with proper hardware support, monitor each core’s state and steer RPCs to the least loaded cores. Such monitoring is implausible without NI integration, as the latency of transferring load information over an I/O bus (e.g. ~ 1.5 µs for a 3-hop posted PCIe transaction) would mean that the NI will make delayed—hence sub-optimal, or even wrong— decisions until the information arrives.
With N participants in the system, RPCValet first writes every incoming message into a single PGAS-resident message buffer of NxS slots. Then it notifies the selected core to process the request. Message arrival and memory location are thus decoupled from the assignment of a core for processing. We have the synchronization-free zero-copy behaviour of a partitioned multi-queue architecture, together with the load-balancing flexibility of a single queue system.
In the implementation each node maintains a send and a receive buffer. Send buffers contain a valid bit indicating whether they are currently being used, and a pointer to a buffer in local memory containing the payload. Receive buffers on the other hand have slots that are size to accommodate message payloads directly.

Overall, the messaging mechanism’s memory footprint is 32 x N x S + (max_msg_size + 64) x N x S bytes. That is, a few tens of MB at most.
The implementation uses a simple scheme to estimate core loads. RPCValet simply keeps track of the number of outstanding send requests assigned to each core. Allowing only one inflight request per core corresponds to a true single-system queue behaviour, but introduces a small inefficiency waiting for the notification of completed request processing. A practical compromise is to allow two outstanding requests per core. This results in marginal performance gains over the single request design for ultra-fast RPCs with service times of a few nanoseconds.
All IN backends independently handle incoming network packets and access memory directly, but they hand off to a single NI dispatcher (over the on-chip interconnect) that is statically assigned to dispatch requests to cores for servicing.
… for modern server processor core counts, the required dispatch throughput should be easily sustainable by a single centralized hardware unit, while the additional latency due to the indirection from any NI backend to the NI dispatcher is negligible (just a few ns).
Evaluation
The evaluation is conducted using against three different service implementations: a synthetic service that emulates different service time distributions; the HERD key-value store, and the Masstree data store.
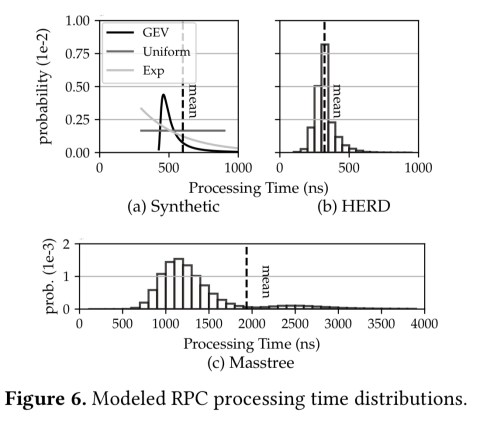
An SLO of less than or equal to 10x the mean service time is assumed in each case, and configurations are evaluated in terms of throughput under SLO.
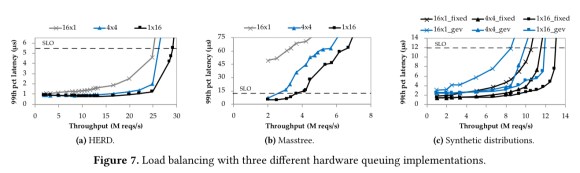
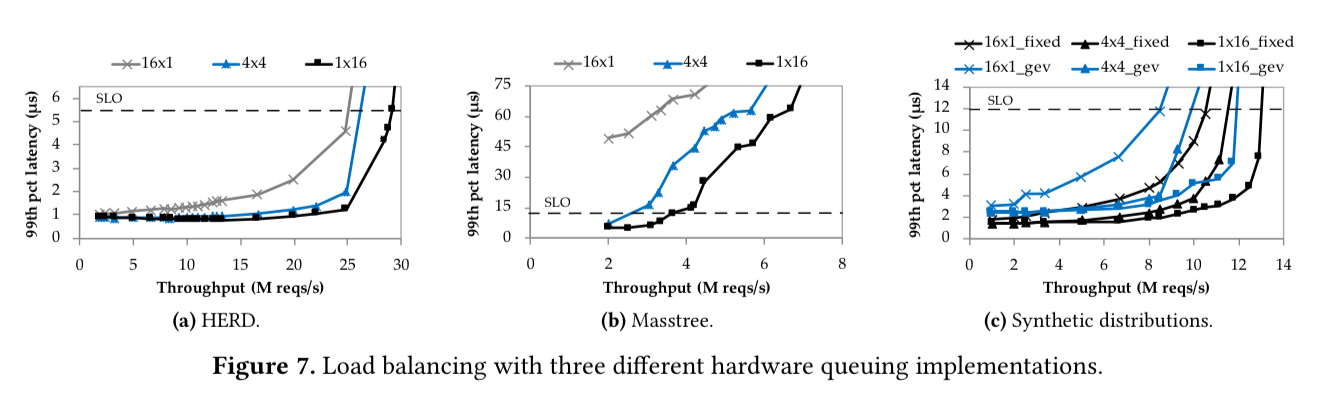
Compared to a software implementation, which requires a synchronisation primitive, the hardware implementation delivers 2.3x-2.7x higher throughput under SLO.

The following plots show the performance of different queueing arrangements under the three workloads, with the ‘1×16’ arrangement that RPCValet simulates performing the best as expected.
(Enlarge)
Compared to a theoretically optimal 1 x 16 model, RPCValet gets within 3-15% (depending on the service time distribution). “We attribute the gap between the implementation and the model to contention that emerges under high load in the implemented systems, which is not captured by the model.”
At the end of the day though:
RPCValet leaves no significant room for improvement; neither centralizing dispatch nor maintaining private request queues per core introduces performance concerns.
Throughput under tight tail latency goals is improved by up to 1.4x, and tail latency before saturation is reduced by up to 4x.

{kind=link}