Calvin: fast distributed transactions for partitioned database systems Thomson et al., SIGMOD’12
Earlier this week we looked at Amazon’s Aurora. Today it’s the turn of Calvin, which is notably used by FaunaDB (strictly “_FaunaDB uses patent-pending technology inspired by Calvin…”). As the paper title suggests, the goal of Calvin is to put the ACID back into distributed databases. I’ve put these systems back-to-back because they are both vying for attention in the serverless world, but note that really this is an apples-to-oranges thing as Aurora scales out MySQL and PostgreSQL with single writer multi-reader models, whereas Calvin supports distributed transactions over distributed databases. A closer comparison with Calvin in the AWS world would be DynamoDB, which recently added limited transaction support (single region tables). Calvin is more commonly compared against Google’s Spanner. See Daniel Abadi on this topic (note that Abadi is one of the authors of the Calvin paper, and an advisor to FaunaDB), and also on “It’s time to move on from two-phase commit.”
Calvin [is] a transaction processing and replication layer designed to transform a generic, non-transactional, un-replicated data store into a fully ACID, consistently replicated distributed database system. Calvin supports horizontal scalability of the database and unconstrained ACID-compliant distributed transactions while supporting both asynchronous and Paxos-based synchronous replication, both within a single data center and across geographically separated data centers.
The secret to Calvin’s scalability is that it sets things up in such a way that distributed commit protocols are not needed. By avoiding this bottleneck the (2012) evaluation showed Calvin able to sustain half-a-million TPC-C transactions per second on a (100-node) cluster of commodity EC2 instances, “which is immediately competitive with the world-record results currently published on the TPC-C website that were obtained with much higher-end hardware.”
The big idea: minimise the contention window
The thing that gets you into scalability problems with distributed transactions is holding locks while coordinating with remote nodes to check everyone is in agreement. This makes a large contention window during which other transactions can get backed up waiting for locks on the same items (or in optimistic schemes, a lot of aborts).
In Calvin, machines agree on the plan for handling a particular transaction outside of any transaction boundaries (i.e., before any locks are acquired). With the plan agreed a transaction can begin and each node must follow the plan exactly. At this point, not even node failure can cause the transaction to abort:
If a node fails, it can recover from a replica that had been executing the same update plan in parallel, or alternatively, it can replay the history of planned activity for the node.
There’s one important requirement for this to work though: activity plans must be deterministic so that replicas cannot diverge and history will always be recreated in exactly the same way. Calvin achieves the desired deterministic outcome by (a) using a deterministic locking protocol for transaction execution, and (b) reaching a global agreement about which transactions to attempt and in what order.
It’s interesting to observe here that whereas many of the works we’ve been looking at recently deal with the problem of ordering through commutativity, Calvin instead deals with the problem of ordering by enforcing one and only one order. That has some interesting ‘tail’ implications that we’ll come back to later.
Another interesting point of comparison, this time with Aurora, is that whereas Aurora keeps only the redo commit logs and pushes those out to the storage layer, Calvin takes the opposite approach and doesn’t use redo logging at all (instead it replicates transaction inputs in conjunction with its determinism guarantee).
System architecture
The essence of Calvin lies in separating the system into three separate layers of processing…
The sequencing layer takes transactional inputs and reaches distributed agreement on a global ordering of transactions. (I.e., we’re still solving a form of distributed consensus right here).
The scheduling layer then uses a deterministic locking scheme to orchestrate transaction execution guaranteeing equivalence to the serial order determined by the sequencing layer.
The storage layer handles all physical data layout. Any storage engine featuring a basic CRUD interface can be plugged into Calvin.
By separating the replication mechanism, transactional functionality and concurrency control (in the sequencing and scheduling layers) from the storage system, the design of Calvin deviates significantly from traditional database design which is highly monolithic, with physical access methods, buffer manager, lock manager, and log manager highly integrated and cross-reliant.
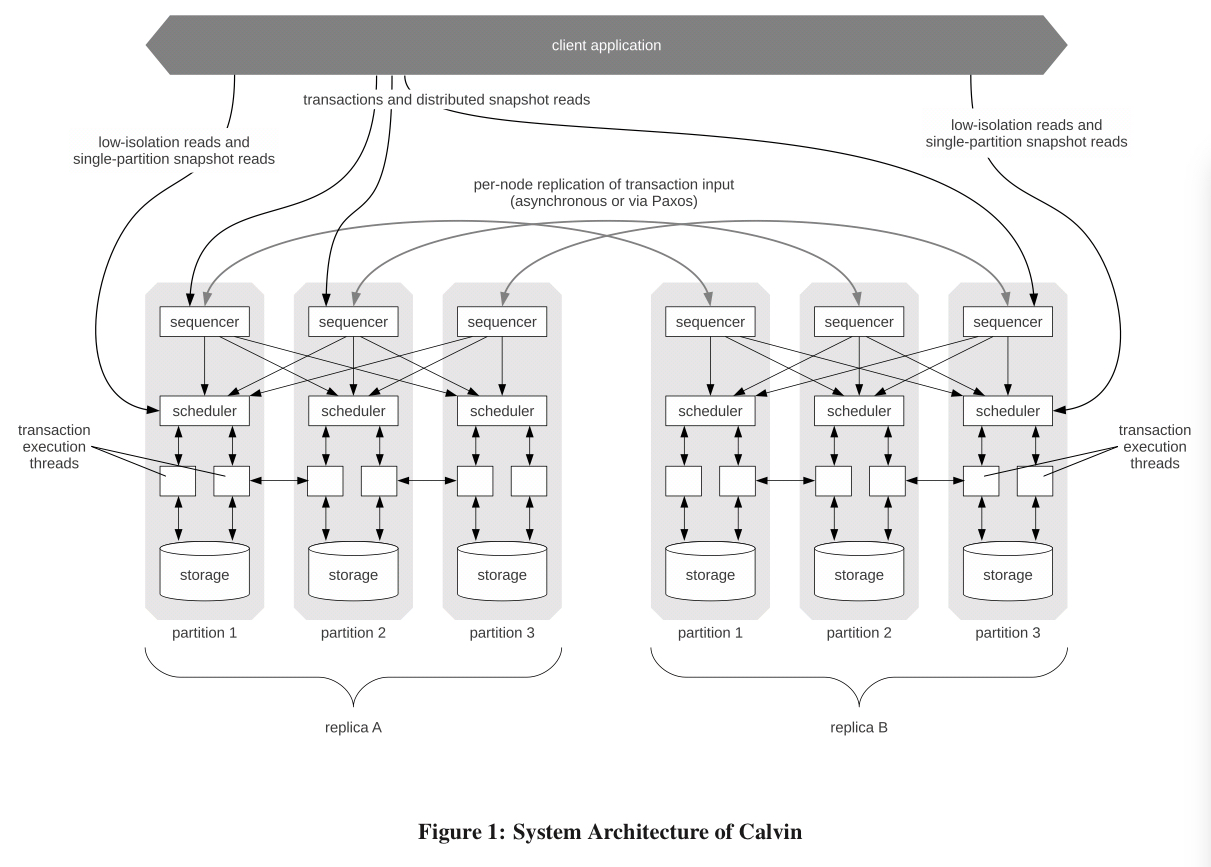
Note though that in constrast to Aurora, the storage layer component is co-located and resident with the the scheduler and sequencer components (each grey box is the figure above is a server). Each node is responsible for a partition, and a replica is a set of nodes covering all partitions.
The sequencing layer divides time into 10-millisecond epochs, with an epoch number synchronously incremented across the entire system each time (how? what if a node is unresponsive? what if a node fails…?). Each sequencer collects transaction requests from clients during the 10ms window and compiles them into a batch, then the batches are replicated across the sequencers (hence a 10ms lower bound on transaction latency). Every scheduler pieces together its own view of the global transaction order by interleaving all sequencer’s batches in a deterministic round-robin order. Calvin supports either asynchronous replication or Paxos-based synchronous replication.
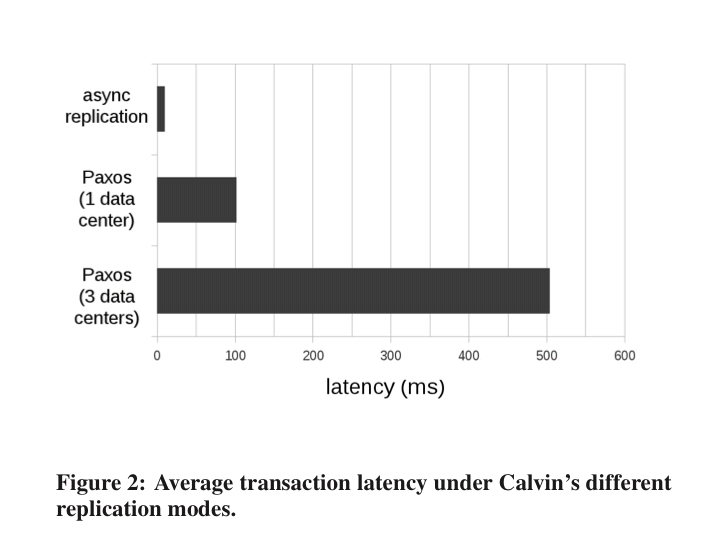
In async mode, one of the replicas is designated as a master and all transaction requests are forwarded to its sequencers. These assemble all received requests into a master list and then forward the list to the other replicas in the group. The challenge with this mode is that failover becomes complex. Hence the Paxos mode in which Paxos is used to agree on a combined batch of transaction requests for an epoch (the Calvin implementation uses ZooKeeper).
With Paxos, transaction latency is up in the 100ms+ range (could we use CURP here?):
With the storage layer separated from the scheduler, …
… both the logging and concurrency protocols have to be completely logical, referring only to record keys rather than physical data structures.
Calvin logs the inputs at the sequencing layer, with occasional checkpoints taken by the storage layer. This is possible because of the deterministic execution. Recall that requires not just global agreement on transaction ordering, but also deterministic lock acquisition during transaction execution. Calvin uses strict two-phase locking with two extra rules:
- If any pair of transactions A and B both requests exclusive locks on a local record R, then whichever transaction comes first in the global order must acquire the lock on R first.
- The lock manager must grant each lock to requesting transactions strictly in the order in which those transactions requested the lock.
One thing that leaps out here is that this requires us to know the read/write sets of transactions ahead of time. And indeed,…
Transactions which must perform reads in order to determine their full read/write sets (which we term dependent transactions) are not natively supported in Calvin since Calvin’s deterministic locking protocol requires advance knowledge of all transactions’ read/write sets before transaction execution can begin.
For such transactions you have to modify the application code a little to introduce a pre-flight “optimistic lock location prediction” (OLLP) step. This is reconnaissance query to figure out what the read/write set is likely to be. If the actual read/write set differs during execution we restart.
Dealing with disk latency
Prior work from the same team assumed an in-memory database. Whereas a commutative or non-deterministic system has freedom to execute transactions in any serial order, Calvin needs to execute transactions in the pre-determined order. So if a transaction A is stalled waiting for disk access we have to wait (whereas a non-deterministic system would be able to go ahead and run other non-conflicting transactions). To mitigate this impact, Calvin tries to ensure that transactions aren’t holding locks and waiting on disk I/O.
Any time a sequencer component receives a request for a transaction that may incur a disk stall, it introduces an artificial delay before forwarding the transaction request to the scheduling layer and meanwhile sends requests to all relevant storage components to “warm up” the disk-resident records that the transaction will access. If the artificial delay is greater than or equal to the time it takes to bring all the disk-resident records into memory, then when the transaction is actually executed, it will access only memory-resident data.
So long as the transaction really would have had to access data from disk anyway, then this additional up-front delay adds nothing to the end-to-end latency.
Now we have two new problems though: (a) how long should the delay before forward be? (i.e., how do we predict disk I/O latency), and (b) we need to track which keys are actually in memory across all storage nodes so that we know when we need to do prefetching.
Predicting disk I/O latency is both difficult (especially if you have heterogenous nodes!) and also “a particularly interesting and crucial parameter when tuning Calvin to perform well on dis—resident data under high contention.” In the evaluation, Calvin was tuned so that at least 99% of disk-accessing transactions were scheduled after their corresponding pre-fetching requests had completed.
The paper offers no scalable solution to tracking the data in memory, as of 2012 that remained ‘future work.’
Checkpointing
Calvin has three checkpointing modes, discussed §5 of the paper. I don’t have the space to discuss them all here, so I refer you to the paper for details. Of note though, is that recovery starts from a checkpoint and then exploits the deterministic nature of the database to recover by replaying transaction inputs (i.e., re-running (side-effect free we hope!) transactions).
Throughput
Here’s Calvin scaling to 500,000 tps on NewOrder (TPC-C):
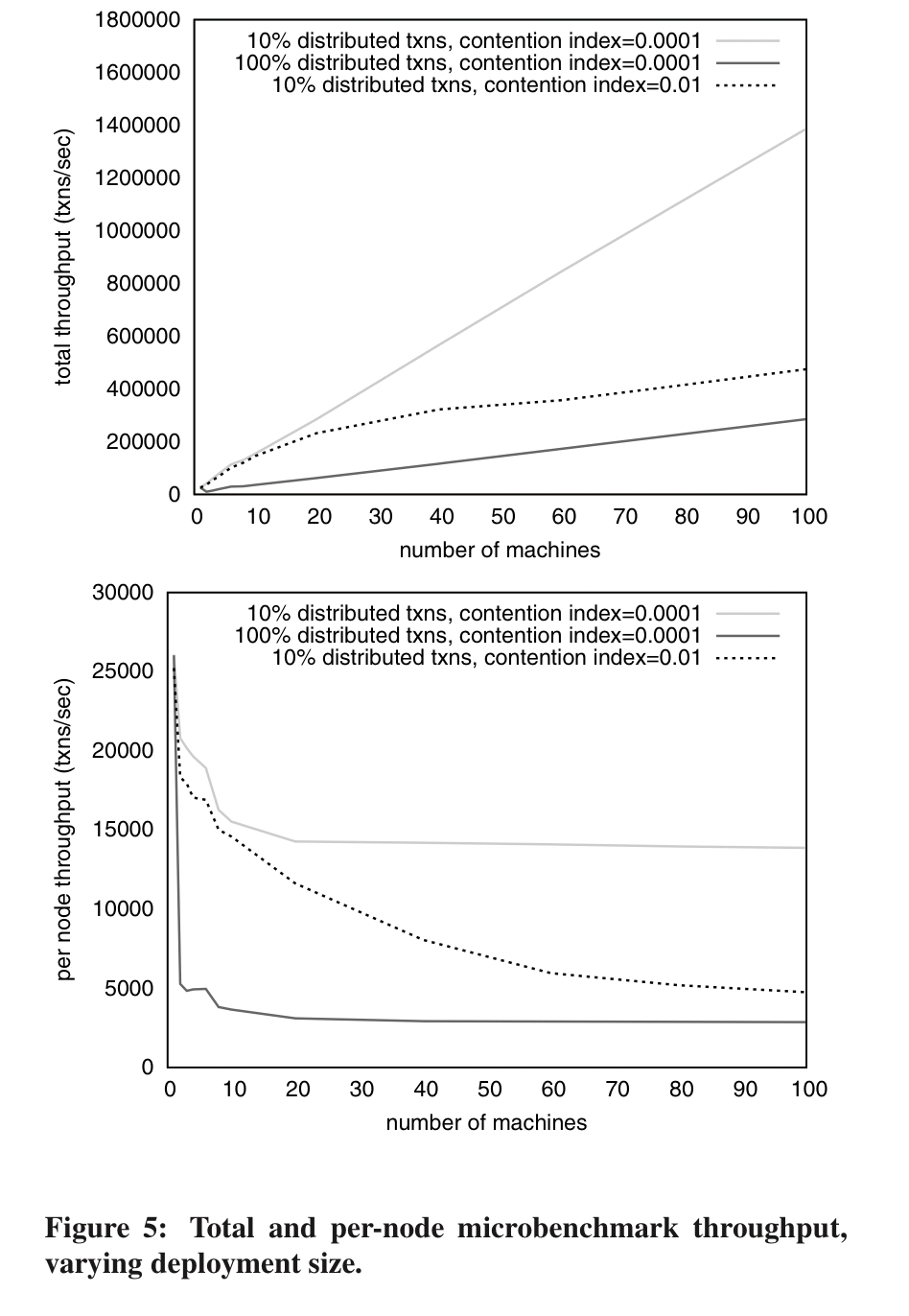
Note that the performance per-machine shows a gradual decline as more nodes are added at higher contention.
Suppose, under a high contention workload, that machine A starts executing a distributed transaction that requires a remote read from machine B, but B hasn’t gotten to that transaction yet (B may still be working on earlier transactions in the sequence, and it can not start working on the transaction until locks have been acquired for all previous transactions in the sequence). Machine A may be able to begin executing some other non-conflicting transactions, but soon it will simply have to wait for B to catch up before it can commit the pending distributed transaction and execute subsequent conflicting transactions. By this mechanism, there is a limit to how far ahead of or behind the pack any particular machine can get. The higher the contention, the tighter this limit.
This makes Calvin sensitive to slow machines (e.g. that unlucky EC2 instance), and execution process skew. With higher contention rates it becomes more likely that each machine’s random slowdowns will cause other machines to slow their execution as well.
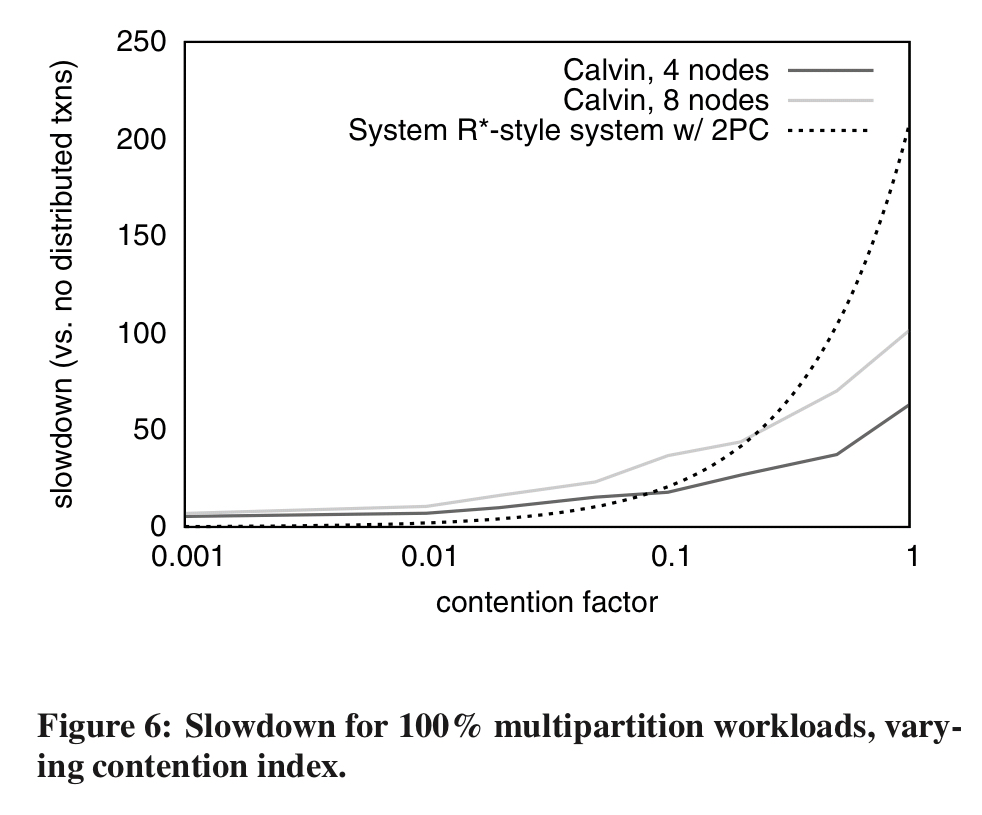
Even so, compared to two-phase commit Calvin performs much better under high contention.
Update: Matt Freels, CTO of FaunaDB, got in touch to point me at two great blog posts on the fauna.com describing how FaunaDB uses Calvin:

Is isolation really guaranteed by Calvin? Suppose shards A and B participate in the same transaction. It appears that shard A could commit its part of the transaction before shard B has even started. At that point, if a client reads from shards A and B, it will receive post-transaction data from A and pre-transaction data from B. In fact, with Calvin it looks like the window for such inconsistencies could grow quite large.