Efficient synchronisation of state-based CRDTs Enes et al., arXiv’18
CRDTs are a great example of consistency as logical monotonicity. They come in two main variations:
- operation-based CRDTs send operations to remote replicas using a reliable dissemination layer with exactly-once causal delivery. (If operations are idempotent then at-least-once is ok too).
- state-based CRDTs exchange information about the resulting state of the data structure (not the operations that led to the state being what it is). In the original form the full-state is sent each time. State-based CRDTs can tolerate dropped, duplicated, and re-ordered messages.
State-based CRDTs look attractive therefore, but over time as the state grows sending the full state every time quickly becomes expensive. That’s where Delta-based CRDTs come in. These send only the delta to the state needed to reconstruct the full state.
Delta-based CRDTs… define delta-mutators that return a delta (
), typically much smaller than the full state of the replica, to be merged with the local state. The same
buffer, to be periodically propagated to remote replicas. Delta-based CRDTs have been adopted in industry as part of the Akka Distributed Data framework and IPFS.
So far so good, but the analysis in this paper reveals an unexpected issue: when updates are frequent enough that concurrent update operations are occurring between synchronisation points, delta-propagation algorithms perform no-better than sending the full state.
You can see the effect in the following chart: delta-based propagation is transmitting pretty much the same amount of data as full state-based.

Moreover, due to the overheads of computing deltas etc., delta-propagation is also consuming a lot more CPU to do so.

I’m sure you’ve also spotted in those two figures the additional data series for ‘this paper.’ Two key enhancements to the delta-propagation algorithm are introduced which greatly reduce both the amount of data transmitted and the CPU (and memory) overheads.
Some example state-based CRDTs
To bring all this to life we need a couple of examples. The paper uses grow-only CRDT counters and grow-only sets. State-based CRDTs are based upon a join semi-lattice, 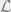

For a grow-only counter, we keep track of one (sub) counter per replica. The inc operation increments the replica-local counter, the join operator takes the higher of the two replica-local counter values for each replica, and the overall counter value is produced by summing the replica-local counters.

For a grow-only set (GSet) we just add elements to the set and the join operator is a set union.

Hasse diagrams can be used to show the evolution of the lattice. For example:

Spotting inefficiencies
Let’s look at one particular evolution of a GSet in a scenario with two replicas, A and B. In the diagram below, 







It’s easy to spot some redundancy in transmission here. At
So it’s not exactly rocket science…
> … by simply tracking the origin of each
The BP optimisation in effect says “don’t send an update back to the replica that told you about it in the first place!” In order to do that, we’ll need some extra book-keeping to remember where updates have come from. The evaluation shows this is worth it.
Here’s another example trace that shows a related issue:

Here we see that at 


> … remove redundant state in received
And that’s it! Don’t send an update back to the replica that sent it to you, and don’t send the same update to the same replica more than once.
A revised delta-based synchronisation algorithm
Now, those ideas are formalised using the notion of a join-irreducible state. A join irreducible state 



Here’s the classic delta-based synchronization algorithm for replica 

For BP, each
Evaluation
The evaluation takes place over two different network topologies. Both have 15 nodes, but one is cyclic (mesh) and one is acyclic (tree).

Each node performs an update and synchronises with its neighbours once per second, as per the table below.

Comparisons are made to vanilla delta state, delta state with each optimisation individually, delta state with both optimisations, and also state-based CRDTs (full state exchange), operation-based CRDTs, and CRDTs using the Scuttlebut anti-entropy protocol.
Here’s an analysis of the amount of data transmitted by GSet and GCounter in the tree and mesh topologies.

The first observation is that the classic delta-based synchronization presents almost no improvement, when compared to state-based synchronization.
In the tree topology, BP alone is enough to give good results, whereas the mesh topology benefits from RR.
Compared to Scuttlebut and operation-based CRDTs, delta-based CRDTs with both BP and RR have a much lower metadata overhead. The overhead can be as high as 75% with the former group, whereas the optimised delta-based algorithm can get this as low as 7.7%.

When used in the Retwis twitter clone for a moderate-to-high contention workload, the BP + RR optimisations can reduce CPU overhead by up to 7.9x compared to the classic delta-based algorithm.

State-based CRDT solutions quickly become prohibitive in practice, if there is no support for treatment of small incremental state deltas. In this paper we advance the foundation of state-based CRDTs by introducing minimal deltas that precisely track state changes.
De-dup FTW!
