Maelstrom: mitigating datacenter-level disasters by draining interdependent traffic safely and efficiently Veeraraghavan et al., OSDI’18
Here’s a really valuable paper detailing four plus years of experience dealing with datacenter outages at Facebook. Maelstrom is the system Facebook use in production to mitigate and recover from datacenter-level disasters. The high level idea is simple: drain traffic away from the failed datacenter and move it to other datacenters. Doing that safely, reliably, and repeatedly, not so simple!
Modern Internet services are composed of hundreds of interdependent systems spanning dozens of geo-distributed datacenters. At this scale, seemingly rare natural disasters, such as hurricanes blowing down power lines and flooding, occur regularly.
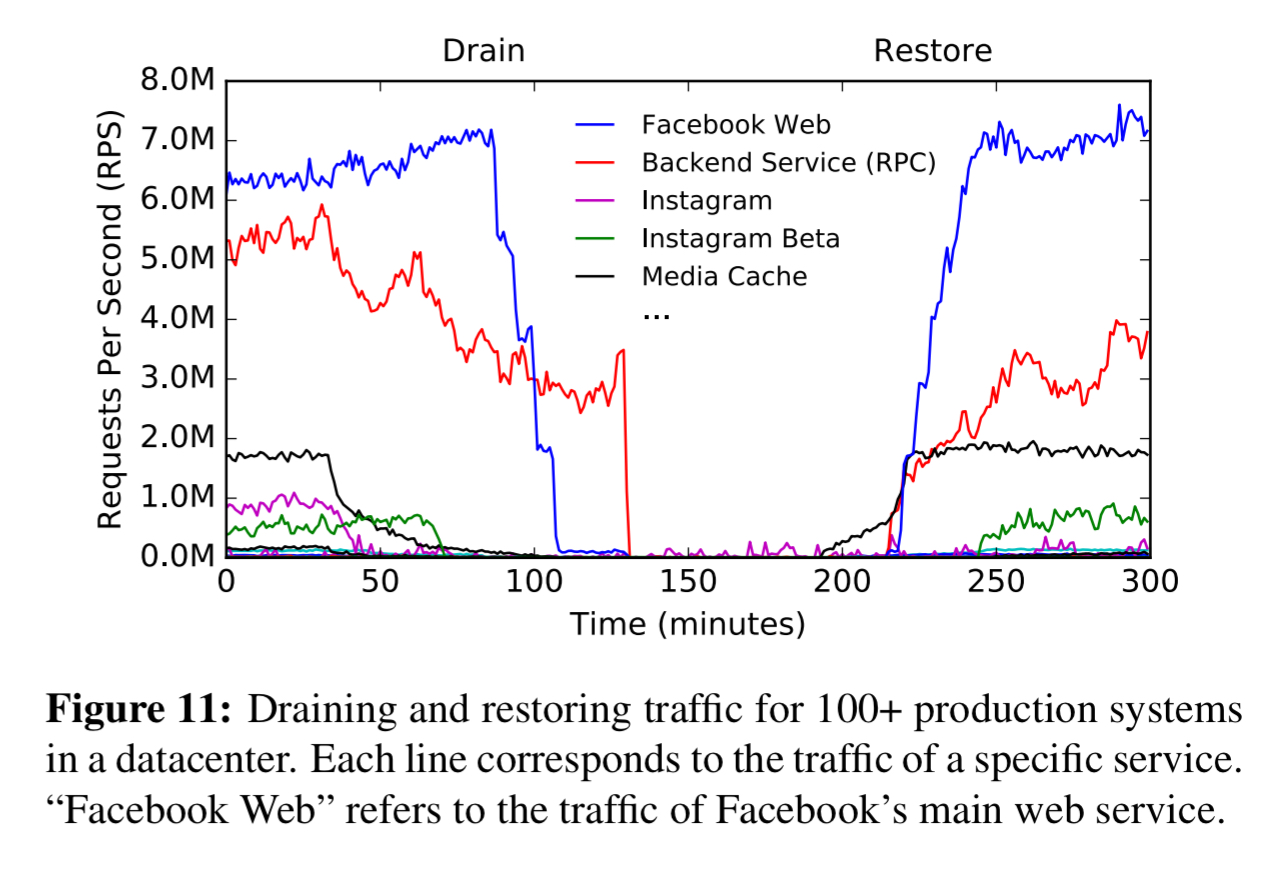
How regularly? Well, we’re told that Maelstrom has been in production at Facebook for over four years, and in that time has helped Facebook to recover from over 100 disasters. I make that about one disaster every two weeks!! Not all of these are total loss of a datacenter, but they’re all serious datacenter-wide incidents. One example was fibrecuts leading to a loss of 85% of the backbone network capability connecting a datacenter to the FB infrastructure. Maelstrom had most user-facing traffic drained in about 17 minutes, and the all traffic drained in about 1.5 hours. Once the backbone network was repaired, Maelstrom was used to restore traffic back to the datacenter.
Also in that disaster count are service-level incidents caused by software errors (bugs, misconfigurations). An alert will inform operators of a serious situation, and the operators then need to decide whether to revert the offending change(s) or fix forward after diagnosing the problem. As we saw last week, identifying the offending changes can itself take time, as does coding up and testing a fix. In these circumstances, Maelstrom can reduce the impact of failures by moving diagnosis and recovery out of the critical path.
Currently, Maelstrom drains hundreds of services in a fully automated manner, with new systems being onboarded regularly. We can drain all user-facing traffic, across multiple product families, from any datacenter in less than 40 minutes.
There are three very valuable contributions in this paper:
- The description of Maelstrom itself, a generic framework for draining heterogeneous traffic from interdependent systems safely and efficiently. (There’s a product right there!)
- An explanation of drain tests as they are practiced at Facebook: an essential component of disaster recovery.
- A sprinkling of hard-won wisdom and expectation setting for rolling out similar capabilities in your own organisation.
Draining traffic, how hard can that really be??
The conceptually simple idea of draining traffic turns out to be rather challenging in practice. In our experience, disasters ofter trigger failures that affect multiple interdependent systems simultaneously… we observe that most of today’s Internet services are composed of a number of heterogeneous systems including singly-homed and failover-based systems with complex, subtle dependencies and distinct traffic characteristics. The most challenging aspect of mitigation is to ensure that dependencies among systems are not violated.
And of course, you’d better not create any new outages or failures as a result of your draining intervention (e.g., it would be easy to cause cascading failures).
Based on affinity (aka ‘stickiness’) and state properties, there are four fundamental types of traffic that need to be considered during draining:
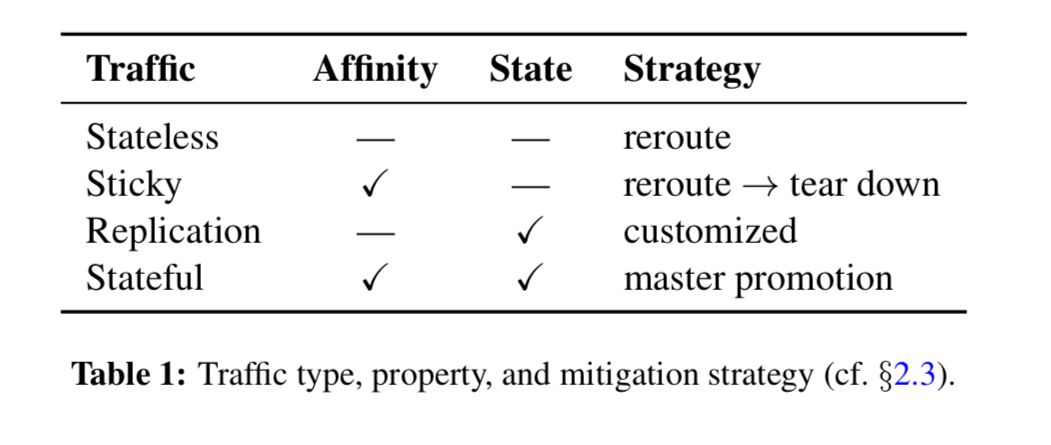
- Stateless traffic (e.g., the majority of web traffic) is easy to deal with.
- Sticky traffic (e.g. messaging) pins to particular machines maintaining session state. For sticky traffic incoming session requests need to be rerouted, and established session torn down.
- Replication traffic rerouting typically requires configuration changes or other heavyweight changes.
- Stateful traffic (e.g. hot standbys) typically requires promoting a secondary to become the new master. State may need to be carefully copied from one datacenter to another.
All of the above needs to be done in the right order as well, based on the dependency graph.
Introducing Maelstrom
Maelstrom is the system that Facebook use to execute disaster mitigation and recovery runbooks.
… a runbook specified the concrete procedure for mitigating the particular disaster scenario by draining traffic out of the datacenter; after the root causes are resolved, a corresponding recovery runbook is used to restore the traffic back…
Runbooks are made up of tasks (e.g. shifting a portion of traffic, migrating data shards, etc.) which can have dependencies between them. The Maelstrom UI can be used to launch runbooks, and monitor their progress.
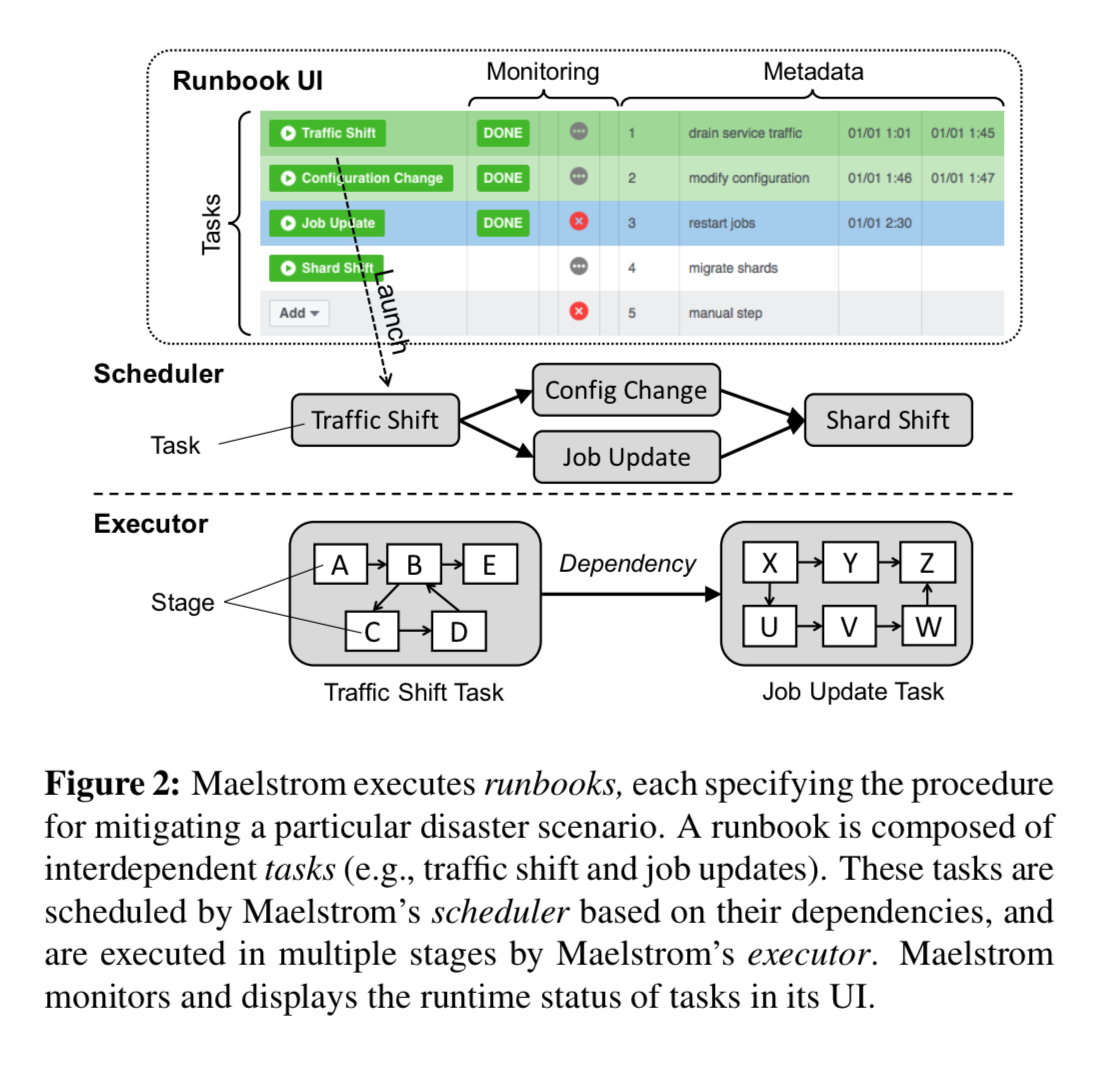
Every service maintains its own service-specific runbook for disaster mitigation. If an entire datacenter is down, a datacenter evacuation runbook is used to drain the traffic of all the services in the datacenter. Such a runbook aggregates a collection of service-specific runbooks.
Tasks are defined based on a collection of task templates. Each task has associated health metrics, pre-conditions and post-conditions, and dependencies.
We implement a library of stages that capture common operations like instructing load balancers to alter traffic allocation, managing containers and jobs, changing system configuration, migrating data shards, etc.
The Maelstrom runtime engine comprises a scheduler that determines the correct order of task execution and an executor that executes tasks and validates the results. Maelstrom compares the duration of each task to the 75th percentile of the execution time of previous runs to determine whether a task is stuck in execution. If so, an operator is alerted. “We prioritize safety over speed, and stall subsequent operations until an operator intervenes“. During execution, Maelstrom uses a closed feedback loop to pace the speed of traffic drains based on extensive health monitoring. After executing a runbook, Maelstrom performs automated critical path analysis to help optimise mitigation time by identifying bottlenecks in the dependency graphs.
Drain testing
Maelstrom can only be as good as its runbooks…
Maelstrom requires runbooks to always keep updated with our rapidly-evolving software systems and physical infrastructure. However, maintaining up-to-date information (e.g. service dependencies) is challenging due to the complexity and dynamics of systems at scale… drain tests are our practical solution to continuously verify and build trust in the runbooks.
Drain tests are fully automated tests that use Maelstrom to drain user-facing and internal service traffic away from a datacenter, just as if that datacenter was failing. Multiple drain tests are run per week to simulate various disaster scenarios, with tests being scheduled at various times to cover different traffic patterns. In addition to regular drain tests, FB also run storm tests at a quarterly cadence. Storm tests evaluate the ability to recover from the total loss of a datacenter, and are similar to Google’s DiRT and Amazon’s GameDay exercises.
Running regular drain tests is the only way to know that the runbooks will do their job when called upon in a real emergency. They operate on live production traffic and are not expected to have any user-visible or service-lever impact: if they do, a follow-up with the engineering team investigates why a given disaster scenario was not handled well.
Drain tests also force us to gain a deep understanding of our complex, dynamic systems and infrastructure, and help us plan capacity for projected demand, audit utilization of shared resources, and discover dependencies.
Drain tests are an important part of verifying that the shared infrastructure has sufficient capacity to absorb spikes in utilization caused by draining with Maelstrom. If a test identifies a bottleneck, “we work with teams to update our routing policies, traffic tagging and prioritization schemes, or bandwidth reservation configuration so we can drain services safely.“. In addition to capacity planning, traffic prioritization is used to drain user-facing traffic as soon as possible, followed by stateful service traffic. In the event of resource overload, many systems also employ graceful degradation with PID controllers (e.g., incrementally turning off ranking algorithm complexity to reduce compute demands).
Creating runbooks and onboarding services
Drain tests help ensure that runbooks are working as desired (not always the same thing as working-as-designed ;) ). One of the main challenges when onboarding a new service is discovering all of its dependencies. Three common dependency relationships often manifest:
- Bootstrapping dependencies occur when a service depends on other components to prepare its execution environment and setup configuration before serving traffic.
- RPC dependencies occur when a service makes RPCs to fetch data from other services during its operation
- State dependencies occur when depending upon traffic state across services, e.g. a proxy to coordinate and manage session establishment.
Uncovering dependencies starts with a scenario-driven questionnaire coupled with an analysis of the outputs of tracing and service discovery systems. Clues to state-based dependencies can also often be found in logs. Once dependencies are identified, they are organised into chains of parent-child dependencies in a disconnected dependency graph. Then common services are identified across chains, these often indicate highly connected components (HCCs).
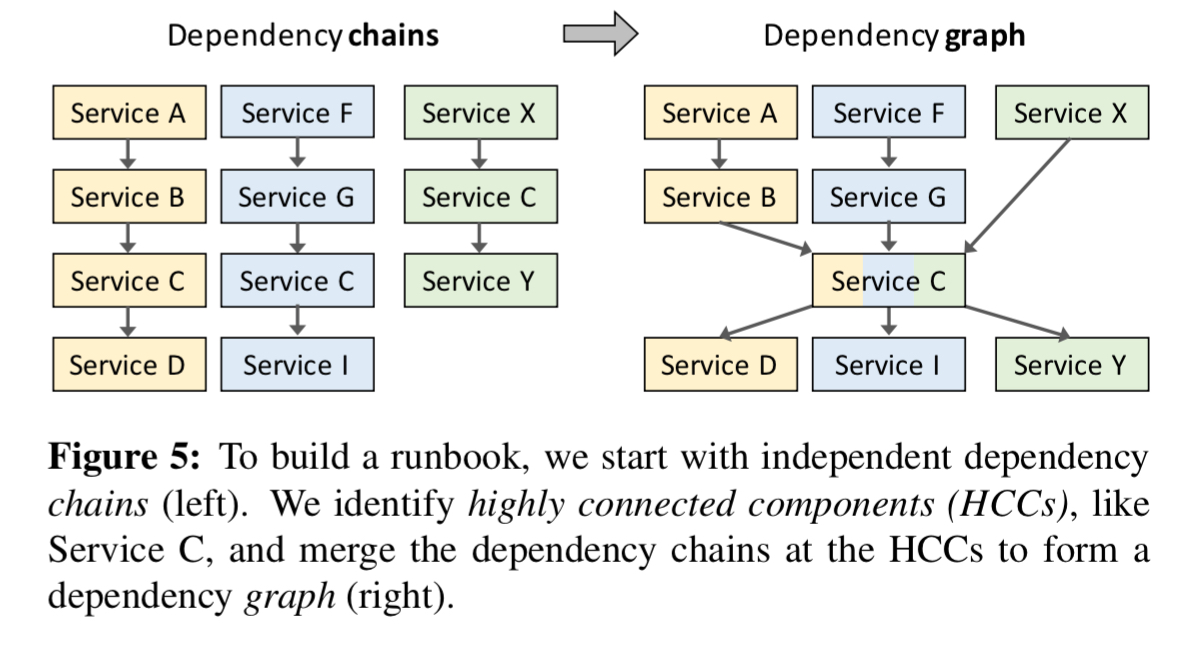
Draining a HCC service will likely require us to drain its parents first; once the HCC service is drained, its children can likely be drained concurrently.
Once the initial runbook has been constructed, Maelstrom is used to cautiously validate it via small-scale drain tests, with careful monitoring of the health of all systems involved. The radius of the drain tests is gradually enlarged until all levels of traffic drains can be performed regularly.
Lessons learned
- Drain tests help us understand interactions amongst systems in our complex infrastructure.
- Drain tests help us prepare for disaster
- Drain tests are challenging to run
- Automating disaster mitigation completely is not a goal. The original vision was to take humans out of the loop altogether. The current design is focused around helping operators triage a disaster and efficiently mitigate it.
- Building the right abstractions to handle failures is important, but takes time and iteration. The separation of runbooks and tasks allows each team to focus on their service specific policies without the need to rebuild mechanisms. Sometimes onboarding a new service does require the creation of new task templates.
- It takes time to reach maturity:
Our original tests only targeted one stateless system: our web servers. The first set of drain tests were painful – they took more than 10 hours, and experienced numerous interruptions as we uncovered dependencies or triggered failures that resulted in service-level issues…. after a year we extended drain tests to two more services: a photo sharing service and a real-time messaging service.
Four-and-a-bit years in, and Maelstrom can now drain hundreds of services.
Maelstrom in action.
Section 5 in the paper contains many examples of Maelstrom draining different types of traffic for Facebook services. I’m already over target length so won’t cover it here, but do check out the full paper for details if this topic interests you.
The last word
As our infrastructure grows, we have learned that it is critical to develop trusted tools and mechanisms to prepare for and respond to failure… Much of the focus of Maelstrom has been around ensuring that Facebook stays available when an incident affects an entire datacenter. In practice, we find that many incidents affect only a subset of hardware and software systems rather than entire datacenters. Our next focus is on building tools to isolate outages to the minimal subset of the systems they affect.

Sounds to me like “we do not have and are unable to develop distributed applications, and they’re just too many of them, so we put some scripts in place to automate moving and restarting of those tons of services. since nobody cares to properly architect and define dependencies we run regular crash tests and fix the scripts as we go.”
I’m not an expert in distributed systems but I wonder: is the state-of-art really that we cannot build these things? Or is it an artifact of starting out with 1 server and simply not having the necessary developer skill and tools in place..?