Sharding the shards: managing datastore locality at scale with Akkio Annamalai et al., OSDI’18
In Harry Potter, the Accio Summoning Charm summons an object to the caster of the spell, sometimes transporting it over a significant distance. In Facebook, Akkio summons data to a datacenter with the goal of improving data access locality for clients. Central to Akkio is the notion of microshards (μ-shards), units of data much smaller than a typical shard. μ-shards are defined by the client application, and should exhibit strong access locality (i.e., the application tends to read/write the data in a μ-shard together in a small window of time). Sitting as a layer between client applications and underlying datastores, Akkio has been in production at Facebook since 2014, where it manages around 100PB of data.
Measurements from our production environment show that Akkio reduces latencies by up to 50%, cross-datacenter traffic by up to 50%, and storage footprint by up to 40% compared to reasonable alternatives.
Akkio can support trillions of μ-shards and many 10s of millions of data access requests per second.
Motivation
Our work in this area was initially motivated by our aim to reduce service response times and resource usage in our cloud environment which operates globally and at scale… Managing data access locality in geo-distributed systems is important because doing so can significantly improve data access latencies, given that intra-datacenter communication latencies are two orders of magnitude smaller than cross-datacenter communication latencies: e.g. 1ms vs 100ms.
At scale, requests issued on behalf of one end-user are likely to be processed by multiple distinct datacenters over time. For example, the user may travel from one location to another, or service workload may be shifted from one location to another.
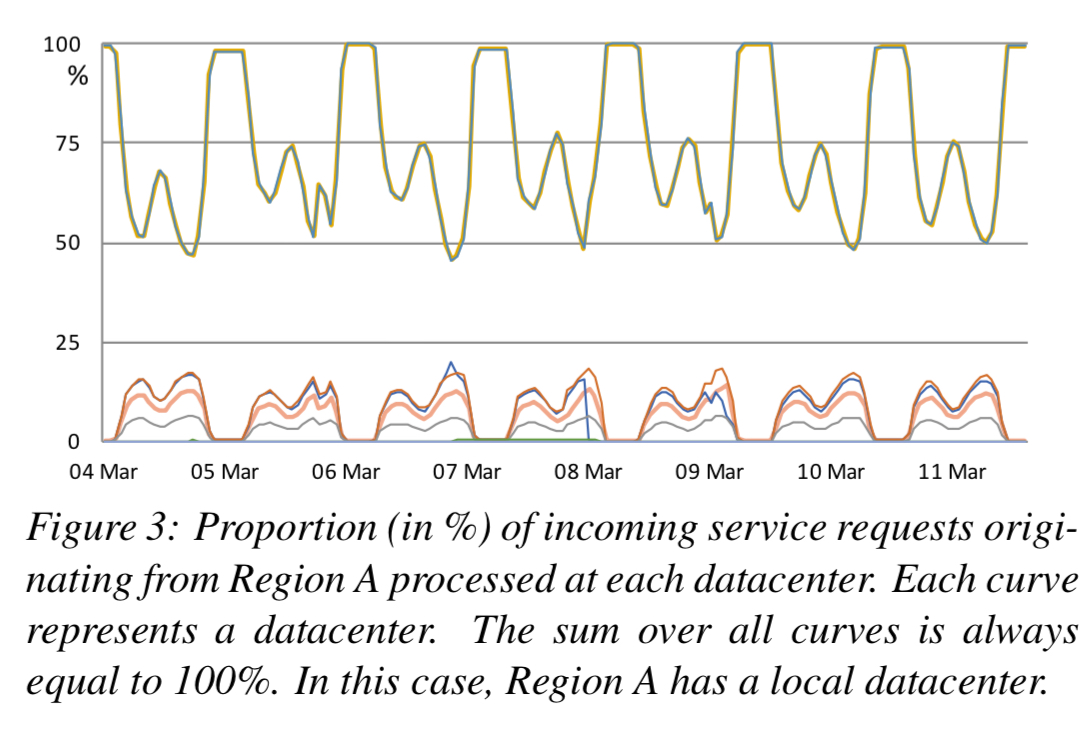
One way to get data locality for accesses is to fully replicate all data across all datacenters. This gets expensive very quickly (the authors estimated $2 million per 100PBs per month for storage, plus costly WAN cross-datacenter bandwidth usage on top).
We could cap those costs by setting a caching budget, but for many of the workloads important to Facebook distributed caching is ineffective. For acceptable hit rates we still need to dedicate large amounts of hardware resources, and these workloads have low read-write ratios. Beyond the cost and latency implications there’s one further issue: “many of the datasets accessed by our services need strong consistency… it is notable that the widely popular distributed caching systems that are scalable, such as Memcached or Redis, do not offer strong consistency. And for good reason.”
Why not just use shards?
Don’t datastores already partition their data using shards though (e.g. through key ranges or hashing)? There are two issues with the existing sharding mechanism from an Akkio perspective:
- Shard sizes are set by administrators to balance shard overhead, load balancing, and failure recovery. They tend to be on the order of a few tens of gigabytes.
- Shards are primarily a datastore concern, used as the unit for replication, failure recovery, and load balancing.
At Facebook, because the working set size of accessed data tends to be less than 1MB, migrating an entire shard (1-10GB) would be ineffective.
μ-shards
Making shards smaller (and thus having many more of them) interferes with the datastore operations, and moving shards as a unit is too heavyweight. So Akkio introduces a new layer on top of shards, μ-shards.
μ-shards are more than just smaller shards, a key difference is that the application itself assigns data to μ-shards with high expectation of access locality. μ-shard migration has an overhead an order of magnitude lower than shard migration and its utility is far higher.
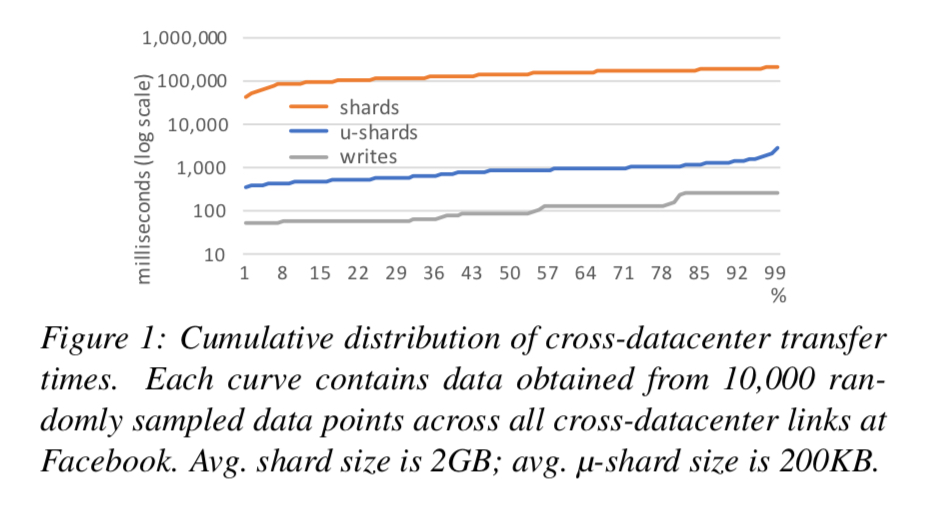
Each μ-shard is defined to contain related data that exhibits some degree of access locality with client applications. It is the application that determines which data is assigned to which μ-shard. At Facebook, μ-shard sizes typically vary from a few hundred bytes to a few megabytes in size, and a μ-shard (typically) contains multiple key-value pairs or database table rows. Each μ-shard is assigned (by Akkio) to a unique shard in that a μ-shard never spans multiple shards.
Examples of applications that fit well with μ-shards include:

The design of Akkio
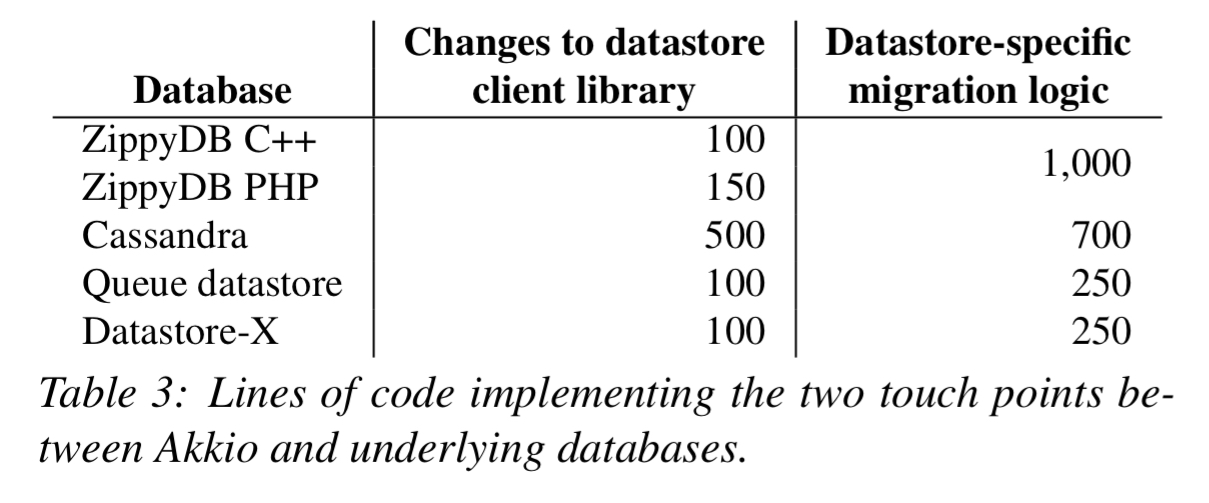
Akkio is implemented as an layer inbetween client applications and an underlying datastore. The paper focuses on Akkio’s integration with Facebook’s ZippyDB, but it’s design enable use with multiple backend datastores. The Akkio client library is embedded within the database client library, exposing an application-managed μ-shard id on all requests. It is up to the application to establish it’s own μ-shard naming scheme.
The Akkio location service maintains a location database that the client can use to map μ-shards to storage servers so that it knows where to direct requests. An access counter service is used to track all accesses, so that μ-shard placement and migration decisions can be made. It is the responsibility of the data placement service (DPS) to decide where to place each μ-shard.
The Akkio Client Library asynchronously notifies the DPS that a μ-shard placement may be suboptimal whenever a data access request needs to be directed to a remote datacenter. The DPS re-evaluates the placement of a μ-shard only when it receives such a notification.
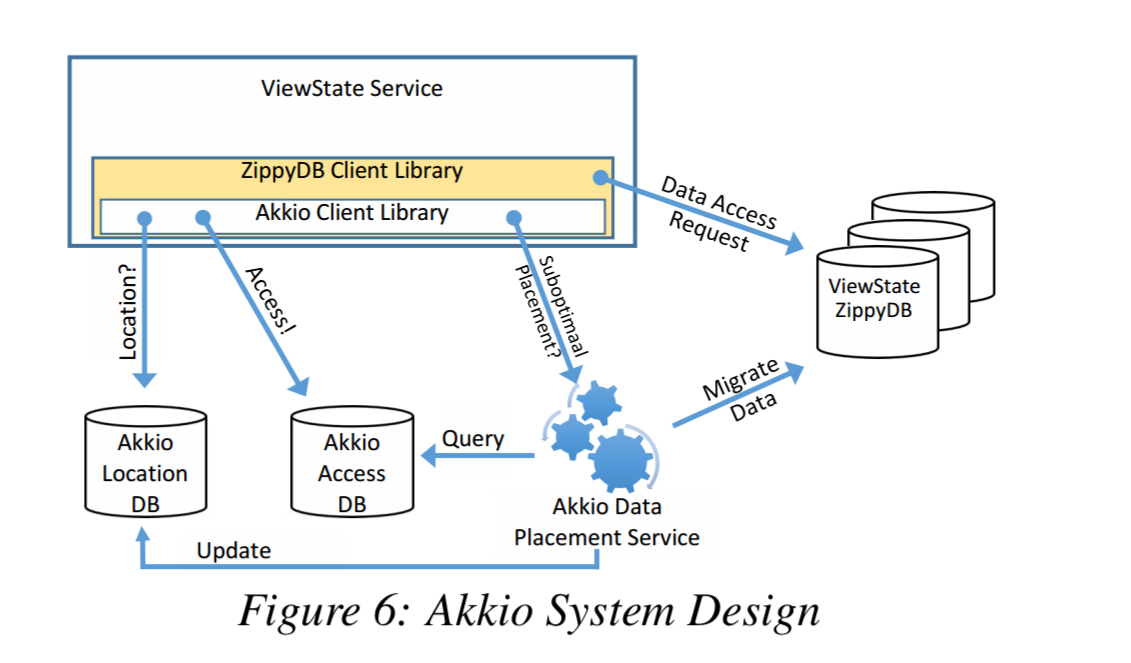
Location information is configured with an eventually consistent replica at every datacenter: the dataset is relatively small, on the order of few hundred GB. If a client reads a stale location and gets a miss it will query a second time requesting that the cache by bypassed (and subsequently updated). Storage required for access counters is also low, less than 200GB per datacenter at Facebook.
All the main action happens in the data placement service, which is tailored for each backend datastore:
There is one DPS per Akkio-supported backend datastore system that is shared among all of the application services using instances of the same datastore system. It is implemented as a distributed service with a presence in every datacenter.
The createUShard() operation is called when a new μ-shard is being created and DPS must decide where to initially place it. evaluatePlacement() is invoked asynchronously by the Akkio client library whenever a data access request needs to be directed to a remote datacenter. DPS first checks its policies to see if initiating a migration is permissible (details of the policy mechanism are mostly out of scope for this paper), and whether a migration is already in process. If migration is permissible it determines the optimal placement for the μ-shard and starts the migration.
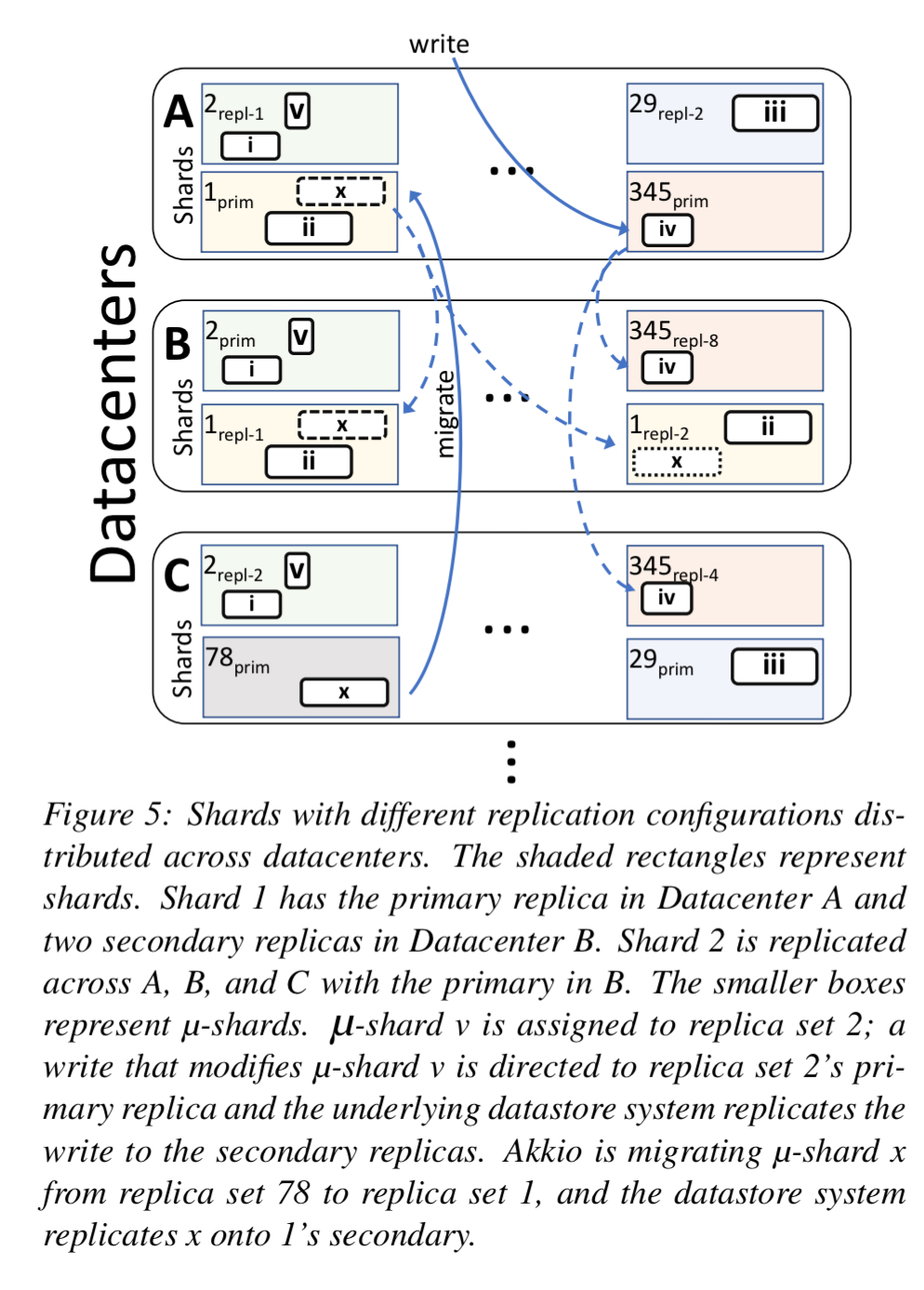
μ-shard placement
To understand placement in the context of ZippyDB, we first need to look briefly at how ZippyDB manages shards and replicas. ZippyDB partitions data horizontally, with each partition assigned to a different shard. Shards can be configured to have multiple replicas which form a shard replica set and participate in a shard-specific Paxos group. The replication configuration of a shard identifies not only the number of replicas, but also how they are to be distributed over datacenters, clusters, and racks, and the degree of consistency required. Replica sets that all have the same configuration from a replica set collection.
When running on ZippyDB, Akkio places μ-shards on, and migrates μ-shards between different such replica set collections.
ZippyDBs Shard Manager assigns each shard replica to a specific ZippyDB server conforming to the policy. The assignments are registered in a directory service.
For initial placement of a μ-shard, the typical strategy is to select a replica set collection with primary replica local to the requesting client and secondary replica(s) in one of the more lightly loaded datacenters. For migration a scoring system is used to select the target replica set collection from those available. First datacenters are scored based on the number of times the μ-shard was accessed from that datacenter over the last X-days, with stronger weighting for more recent accesses. Any ties are then broken by scoring datacenters based on the amount of available resources within them.
When working on top of ZippyDB, Akkio makes use of ZippyDB’s access control lists and transactions to implement migrations. The move algorithm looks like this:

On top of Facebook’s Cassandra variant (which doesn’t support ACLs, though the open-source Cassandra does), a different migration strategy is needed:

Now, that’s all well and good but here’s the part I still don’t understand. The underlying sharding system of the datastore controls placement. Data items are assigned to shards by some partitioning scheme (e.g. by range partitioning, or by hash partitioning). So when we move a μ-shard from one shard (replica collection set) to another, what is really happening with respect to those keys? Are they being finagled in the client so that e.g. they end up in the right range? (Have the right hash value????!). I feel like I must be missing something really obvious here, but I can’t see it described in the paper. Akkio does allow for some minimal changes to the underlying datastore to accommodate μ-shard migrations, but these changes are minimal:
Akkio in production
The evaluation section contains multiple examples of Akkio in use at Facebook, which we don’t have space to cover in detail. The before-and-after comparisons (in live production deployments) make compelling reading though:
- ViewState data stores a history of content previously shown to a user. Replica set collections are configured with two replicas in one local datacenter, and third in a nearby datacenter. Akkio is configured to migrate μ-shards aggressively.
Originally, ViewState data was fully replicated across six datacenters. Using Akkio with the setup described above let to a 40% smaller storage footprint, a 50% reduction of cross-datacenter traffic, and about a 60% reduction in read-and write latencies compared to the original non-Akkio setup.
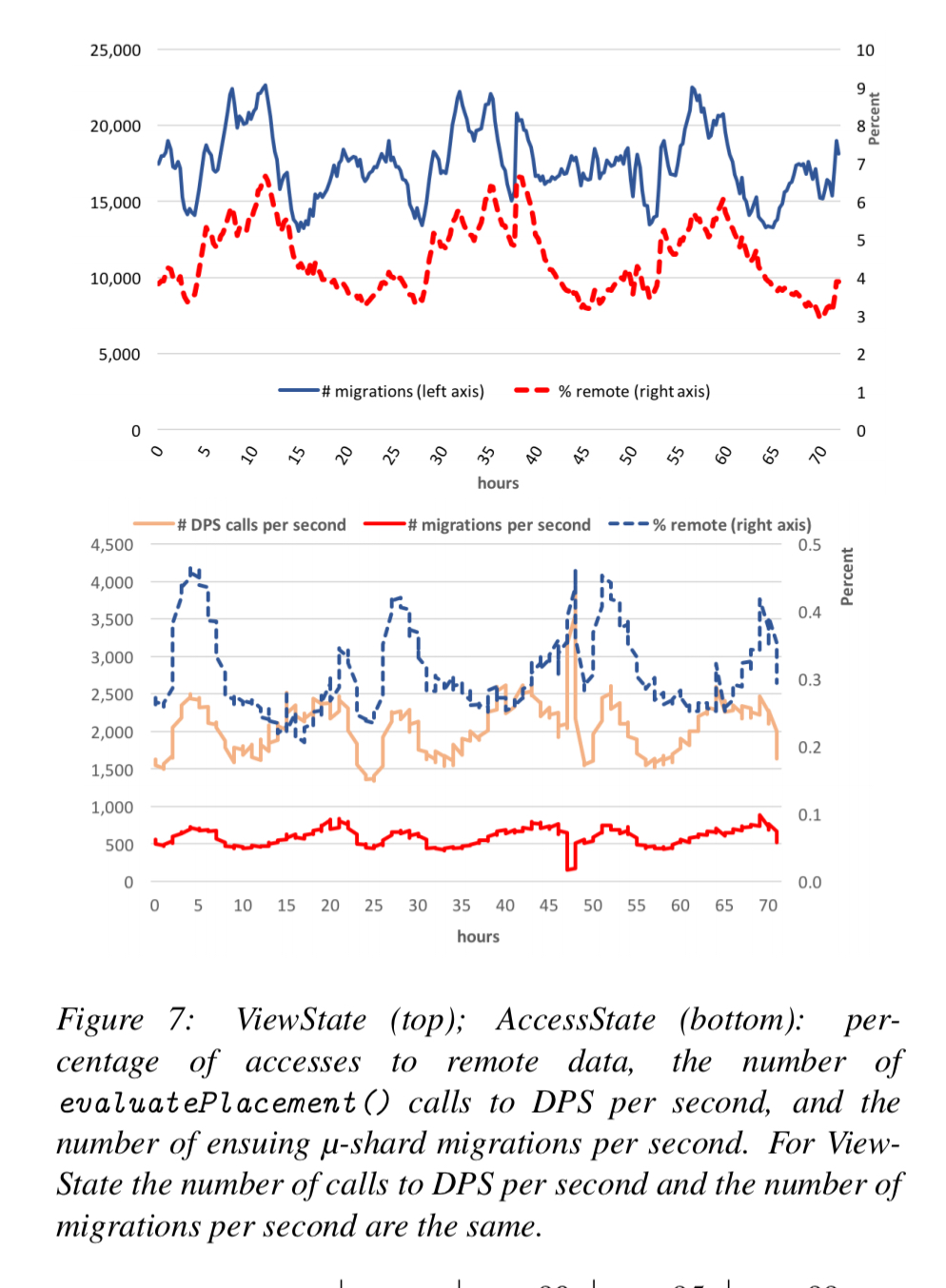
- AccessState stores information about user actions taken in response to displayed content. Akkio once more decreased storage footprint by 40%, and cross-datacenter traffic by 50%. Read latency was unaffected, but write latency reduced by 60%.
- For Instagram ‘Connection-Info’ Akkio enabled Instagram to expand into a second continent keeping both read and write latencies lower than 50ms. “This service would not have expanded into the second continent without Akkio.”
- For the Instagram Direct messaging application, Akkio reduced end-to-end message delivery latency by 90ms at P90 and 150ms at P99. (The performance boost in turn delivered improvements in key user engagement metrics).
Up next: migrating more applications to Akkio, and supporting more datastore systems on the backend (including MySQL). In addition…
… work has started using Akkio (i) to migrate data between hot and cold storage, and (ii) to migrate data more gracefully onto newly created shards when resharding is required to accommodate (many) new nodes.

Maybe just a too dumb attempt to answer your question: I guess data items are stored with respect to a u-shard id and to locate it, there is always the indirection over the DPS to get the shard id itself. So probably ranged/hashed keys never need to be reallocated, just because there are none on the u level.
“Data items are assigned to shards by some partitioning scheme (e.g. by range partitioning, or by hash partitioning)”
From my understanding, this is precisely not the case here: before every data access, there is a “getLocation” call to the Location Service to fetch the right replica set based on some application-defined criteria. So it seems there is no hash or range involved here, but just a global “key -> location” map (itself distributed and cached in each datacenter)
Thank you for this article. Your blog is the first thing i check