Orca: differential bug localization in large-scale services Bhagwan et al., OSDI’18
Earlier this week we looked at REPT, the reverse debugging tool deployed live in the Windows Error Reporting service. Today it’s the turn of Orca, a bug localisation service that Microsoft have in production usage for six of their large online services. The focus of this paper is on the use of Orca with ‘Orion,’ where Orion is a codename given to a ‘large enterprise email and collaboration service that supports several millions of users, run across hundreds of thousands of machines, and serves millions of requests per second.’ We could it ‘Office 365’ perhaps? Like REPT, Orca won a best paper award (meaning MR scooped 2 out of the three awards at OSDI this year!).
Orca is designed to support on-call engineers (OCEs) in quickly figuring out the change (commit) that introduced a bug to a service so that it can be backed out. (Fixes can come later!). That’s a much harder task than it sounds in highly dynamic and fast moving environments. In ‘Orion’ for example there are many developers concurrently committing code. Post review the changes are eligible for inclusion in a build. An administrator periodically creates new builds combining multiple commits. A build is the unit of deployment for the service, and may contain from one to hundreds of commits.
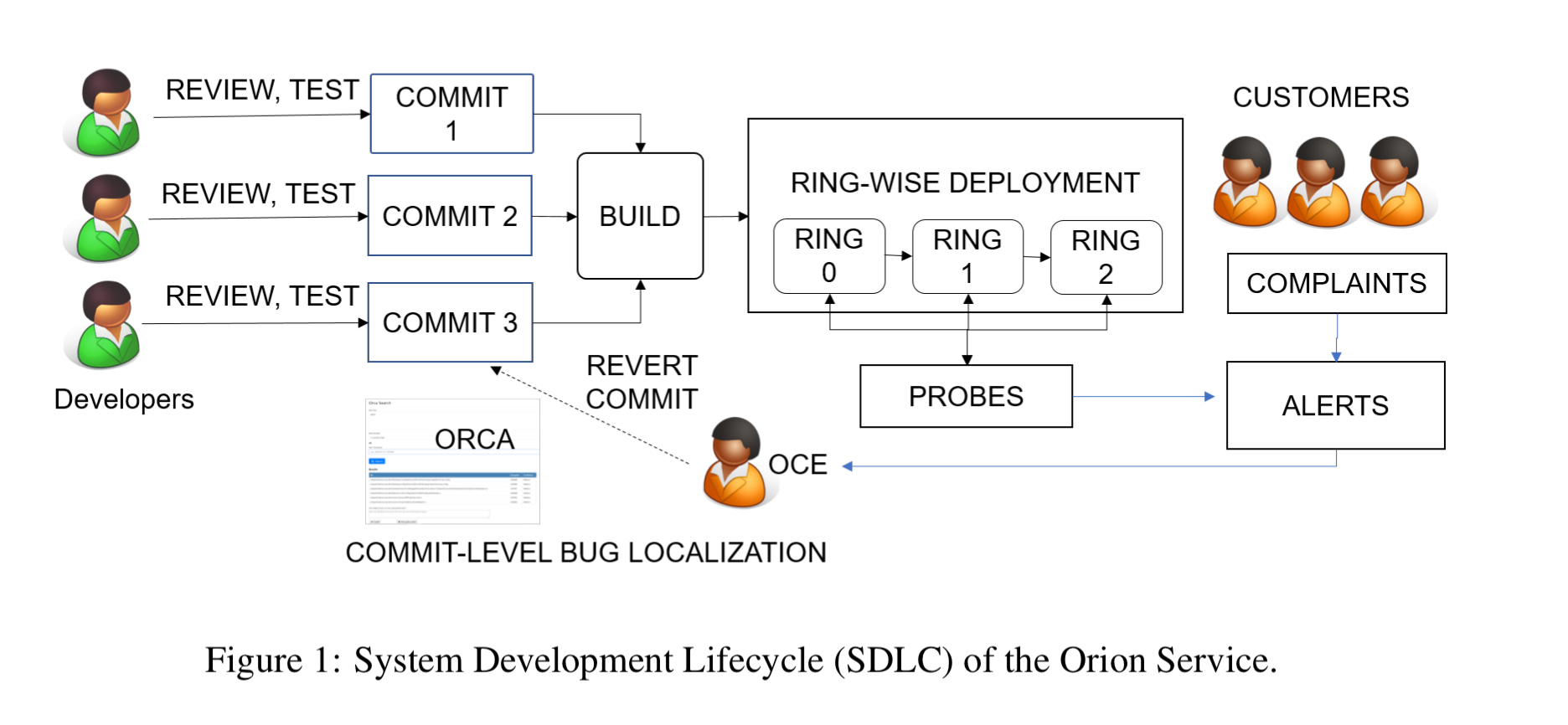
There’s a staged roll-out process where builds move through rings. A ring is just a pre-determined set of machines that all run the same build. Builds are first deployed onto the smallest ring, ring 0, and monitored. When it is considered safe the build will progress to the next ring, and so on until it is finally deployed world wide.
Roughly half of all Orion’s alerts are caused by bugs introduced through commits. An OCE trying to trace an alert back to a commit may need to reason through hundreds of commits across a hierarchy of builds. Orca reduced the OCE workload by 3x when going through this process. No wonder then that it seems to be spreading rapidly within Microsoft.
Example post-deployment bugs
Over a period of eight months, we analyzed various post-deployment bugs and the buggy source-code that caused them. Table 2 (below) outlines a few characteristic issues.
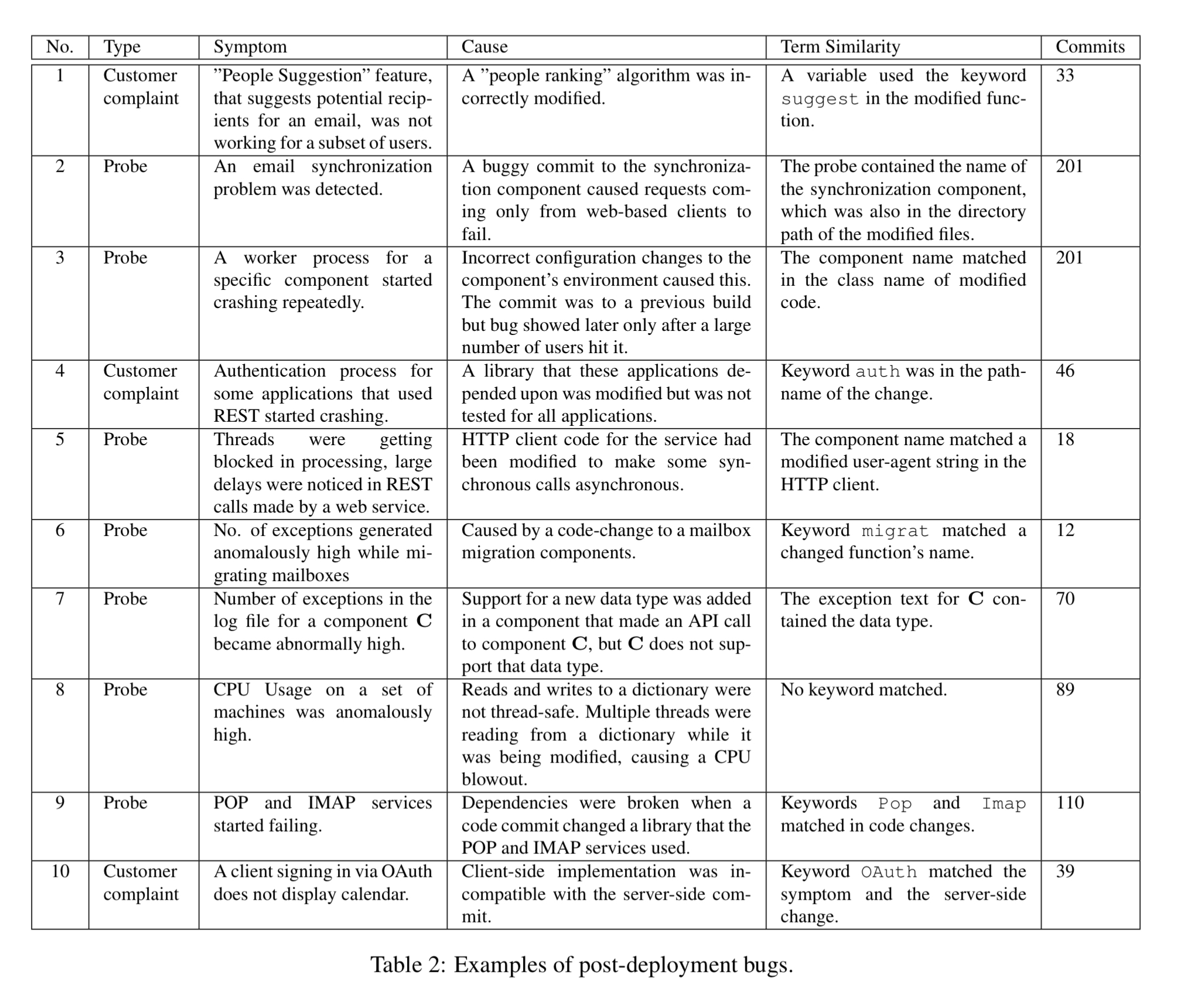
The commits column in the table above shows the number of candidate commits that an OCE had to consider while triaging the issue. Post-deployment bugs fall pre-dominantly into the following categories:
- Bugs specific to certain environments (aka ‘works for me!’)
- Bugs due to uncaptured dependencies (e.g. a server-side implementation is modified but the corresponding client change has not been made)
- Bugs that introduce performance overheads (that only emerge once a large number of users are active)
- Bugs in the user-interface whereby a UI feature starts misbehaving and customers are complaining.
Studying the bugs and observing the OCEs gave a number of insights that informed Orca’s design:
- Often the same meaningful terms occur both in the symptom and the cause. E.g. in bug no 1 in the above table the symptom is that the People Suggestion feature has stopped working, and the commit introducing the problem has a variable ‘suggest’.
- Testing and anomaly detection algorithms don’t always find a bug immediately. A bug can start surfacing in a new build, despite being first introduced in a much older build. For example bug 3 in the table appeared in a build that contained 160 commits, but the root cause was in the previous build with 41 commits.
- Builds may contain hundreds of commits, so manually attributing bugs can be a long task.
- There are thousands of probes in the system, and probe failures and detections are continuously logged.
Based on these insights Orca was designed as a custom search engine using the symptom as the query text. A build provenance graph is maintained so that Orca knows the candidate set of commits to work through, and a custom ranking function is used to help rank commits in the search results based on a prediction of risk in the commit. Finally, the information already gathered from the logged probe failures give a rich indication of likely symptom search terms, and these can be used to track the frequency of terms in query and use Inverse Query Frequency ICF (cf. Inverse Document Frequency, IDF) in search ranking.
In addition to being used by OCEs to search symptoms, multiple groups have also integrated Orca with their alerting system to get a list of suspect commits for an alert and include it in the alert itself.
How Orca works
The input query to Orca is a symptom of the bug… The idea is to search for this query through changes in code or configurations that could have caused this bug. Thus the “documents” that the tool searches are properties that changed with a commit, such as the names of files that were added, removed or modified, commit and review comments, modified code and modified configuration parameters. Orca’s output is a ranked list of commits, with the most likely buggy commit displayed first.
The first step is to tokenize the terms from the presenting symptoms, using heuristics specially built for code and log messages (e.g. splitting large strings according to Camel-casing). In addition to single tokens, some n-gram tokens are also created. After tokenization, stop words are filtered out, as well as commonly used or irrelevant terms found through analysing about 8 million alerts in Orion’s log store (e.g., the ‘Exception’ postfix on class names).
Now we need to find the set of commits to include in the search. Orca creates and maintains a build provenance graph. The graph captures dependencies between builds and across rings.
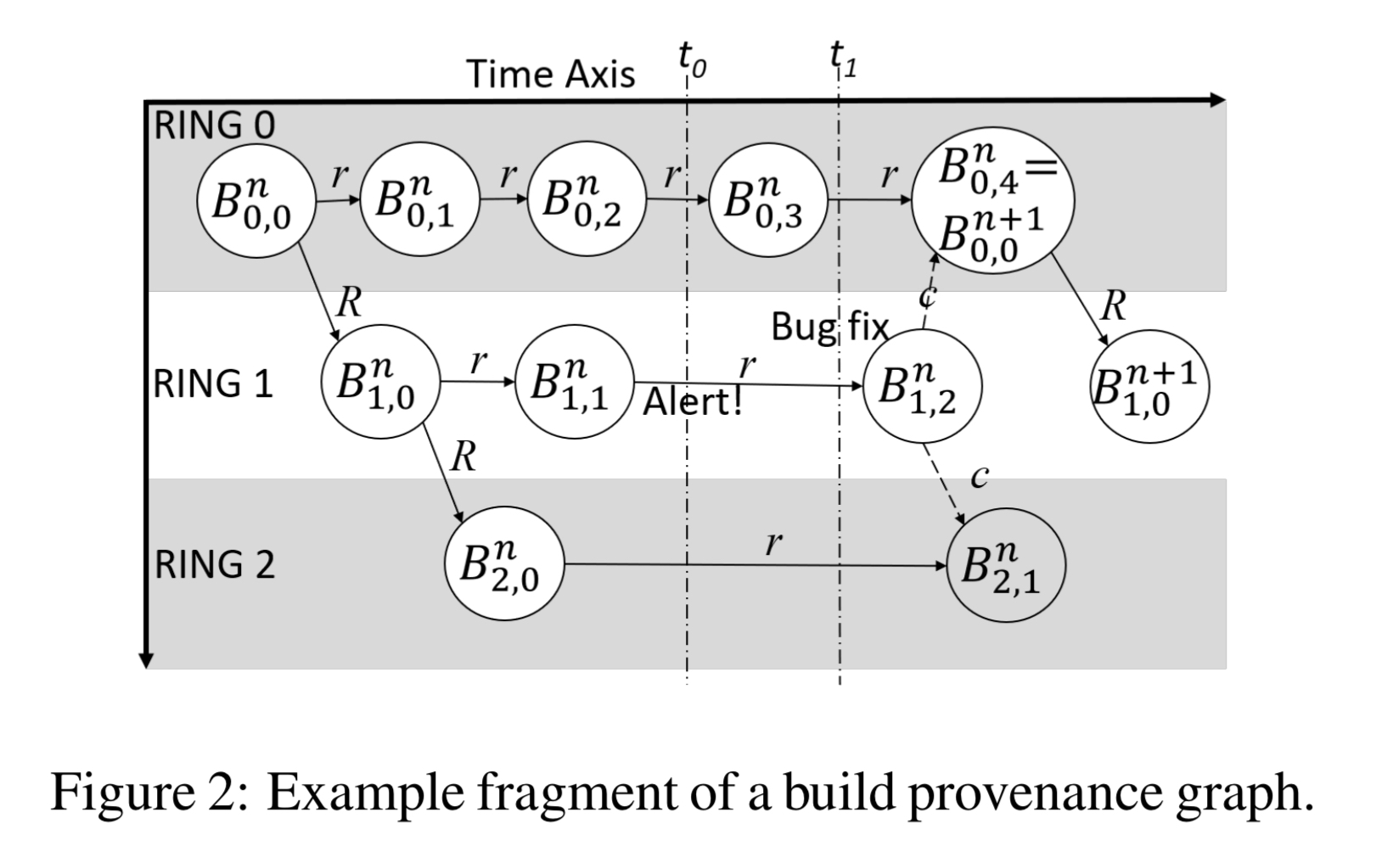
Builds that are considered stable in a given ring can be promoted to the next ring, which gives rise to an inter-ring edge. Interestingly not all fixes roll forward through this process though. A critical bug found in a build in a later ring can be fixed directly in that ring and then the fix is back-ported to earlier rings. Orca uses the graph to trace a path back from the the build in which the symptom is exhibiting, to the origin build in ring 0. The candidate list of commits to search includes all commits in the builds on this path, together with any back-ported commits.
Given the set of commits, Orca uses differential code analysis to prune the search space. ASTs of the old and new versions of the code are compared to discover relevant parts of the source that have been added, removed and modified in a commit. The analysis finds differences in classes, methods, references, conditions, and loops. For all of the changed entities, a heuristic determines what information to include in the delta. For example, if two lines in a function have been changed the diff will include the entire text of the two changed lines (old version and new version) as well as the name of the function. This approach catches higher-level structures that a straight lexical analysis of the diff would miss.
The output of the differential code analysis is search for tokens from the tokenised symptom description, using TF-IQF as a ‘relevance’ score. These scores are first computed on a per-file basis and then aggregated to give an overall score for the commit. In the evaluation, ‘max’ was found to work well as the evaluation function.
We can now return the ranked search results. However, the authors found that very often multiple commits had the same or very similar scores. To break ties between commits with the same scores, a commit risk prediction model is used.
Commit risk prediction
We have built a regression tree-based model that, given a commit, outputs a risk value for it which falls between 0 and 1. this is based on data we have collected for around 93,000 commits made over 2 years. Commits that caused bugs in deployed are labeled ‘risky’ while those that did not, we labeled ‘safe.’ We have put in considerable effort into engineering the features for this task…
This is a super-interesting area in its own right. The paper only includes a brief summary of the main features that inform this model:
- Developers who are new to the organisation and the code base tend to create more post-deployment bugs. So there are several experience-related features in the model.
- Files mostly changed by a single developer tend to have fewer bugs than files touched by several developers. So the model includes features capturing whether a commit includes files with many owners or few.
- Certain code-paths when touched tend to cause more post-deployment bugs than others, so the model includes features capturing this.
- Features such as file types changed, number of lines changed, and number of reviewer comments capture the complexity of the commit.
Evaluation
Since its deployment for ‘Orion’ in October 2017, Orca has been used to triage 4,400 issues. The authors collected detailed information for 48 of these to help assess the contribution that Orca makes to the process. Recall that an OCE is presented with a symptom and may have to search through hundreds of commits to find the culprit. The following table shows how often Orca highlights the correct commit in a top-n list of results (look at the top line, and the ‘ALL’ columns):
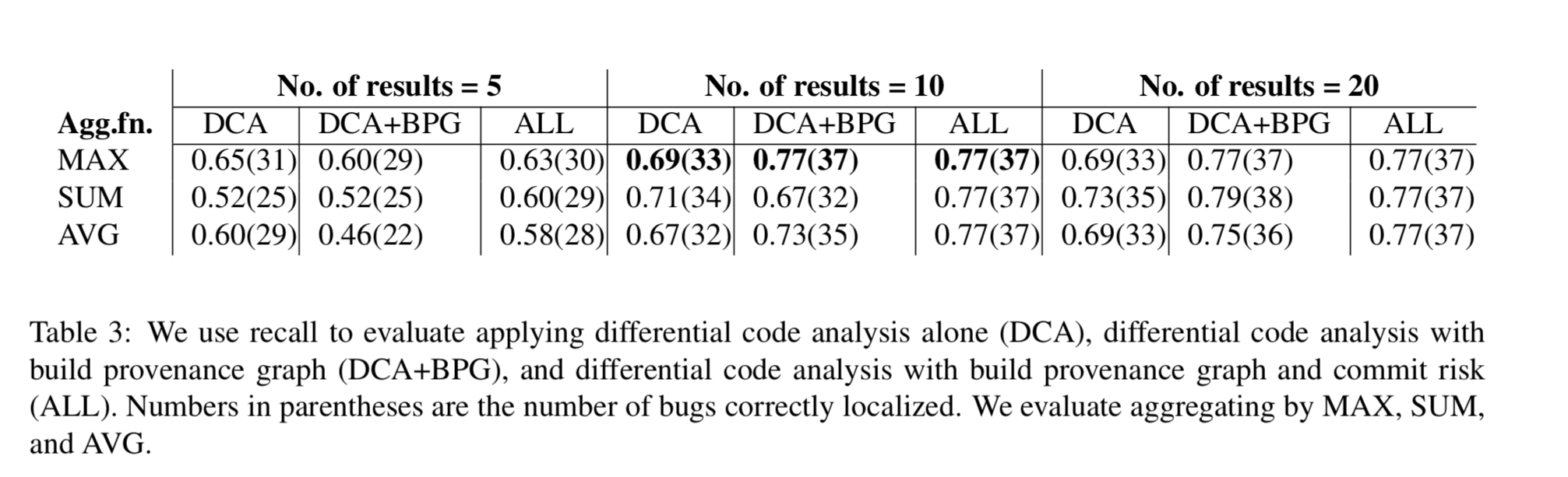
As deployed, Orca presents 10 search results. So the correct commit is automatically highlighted to the OCE as part of this list in 77% of cases. The build provenance graph contributes 8% to the recall accuracy, and the commit risk-based ranking contributes 11%.
The impact on overall OCE workload is significant. The following chart shows the number of expected commits an OCE investigates with and without Orca for the 48 issues in the study.
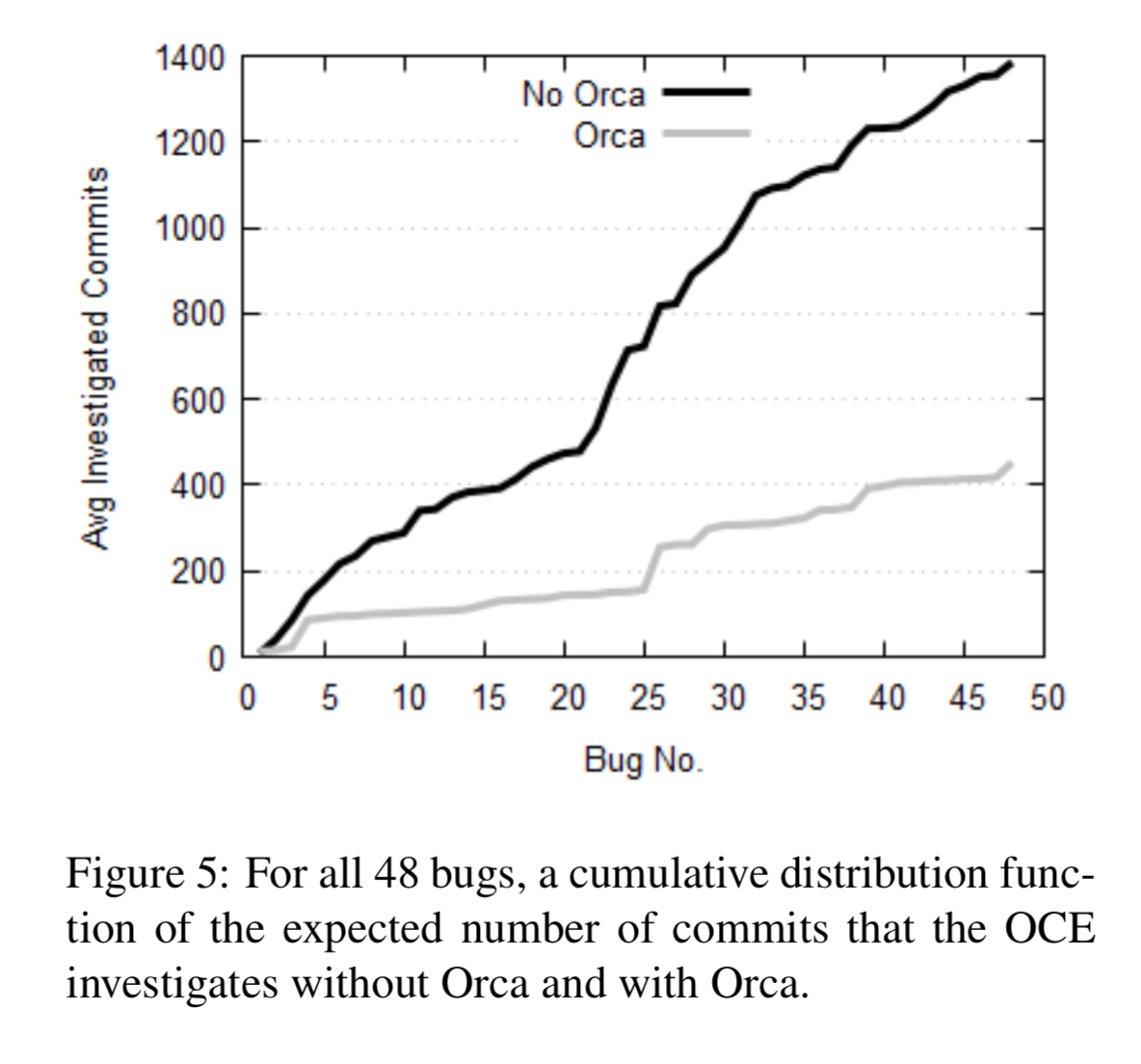
… using Orca causes a 6.5x reduction in median OCE workload and a 3x (67%) reduction in the OCE’s average workload… For the 4 bugs that were caught only because of the build provenance graph, the OCE had to investigate an average of 59.4 commits without Orca, and only 1.25 commits with it. This is a 47.5x improvement.
A closing thought:
Though we describe Orca in the context of a large service and post-deployment bugs, we believe the techniques we have used also apply generically to many Continuous Integration / Continuous Deployment pipelines. This is based on our experience with multiple services that Orca is operational on within our organization.

8 thoughts on “Orca: differential bug localization in large-scale services”
Comments are closed.