I know you’ll be back: interpretable new user clustering and churn prediction on a mobile social application Yang et al., KDD’18
Churn rates (how fast users abandon your app / service) are really important in modelling a business. If the churn rate is too high, it’s hard to maintain growth. Since acquiring new customers is also typically much more expensive than expanding in existing accounts, churn hits you twice over. So it’s really important to understand what causes users to churn in your business, and ideally to be able to predict users likely to churn so that you can intervene. This paper describes ClusChurn, the churn prediction system deployed at Snapchat.
It has been argued for decades that acquiring new users is often more expensive than keeping old ones. Surprisingly, however, user retention and its core component, churn prediction, have received much less attention from the research community… While this paper focuses on the Snapchat data as a comprehensive example, the techniques developed here can be readily leveraged for other online platforms, where users interact with the platform functions as well as other users.
The central idea in ClusChurn is to cluster users into clusters that are meaningful from a business perspective, and then use the assignment of a given user to a cluster to help predict churn. The challenge is that we want to tell quickly whether a new user is likely to churn or not, so we can’t hang around for loads of data to see what cluster they belong to first. Thus Snap jointly learn both the user type (cluster) and user churn likelihood. A prototype implementation of ClusChurn based on PyTorch is available on GitHub.
Understanding Snapchat users – automated discovery of user types
The journey begins with an analysis of new user behaviour on Snapchat to see if meaningful user types (clusters) exist in the data. This information will inform the churn prediction algorithm developed in the next step. The analysis is done on two weeks of anonymous user data from a selected country, chosen because it provides a relatively small and complete network. There are 0.5M new users in the dataset (adding 250K users a week therefore!), and about 40M users totals with approximately 700M links.
The clustering is based on two sets of features: user features associated with their daily activities (e.g. the number of chats they send and receive); and ego-network features describing the structure of the friend network centred on the user. The user features are summarised in the table below. There are two ego-network features, user degree (how many friends a user has), and friend density. The density is calculated as the number of actual links between a user’s friends divided by the number of possible links. The ten user features plus the two network features gives a total of 12 features per day. Each of these 12 features is captured every day for two weeks for each user, given a 12-dimensional time series of length 14.
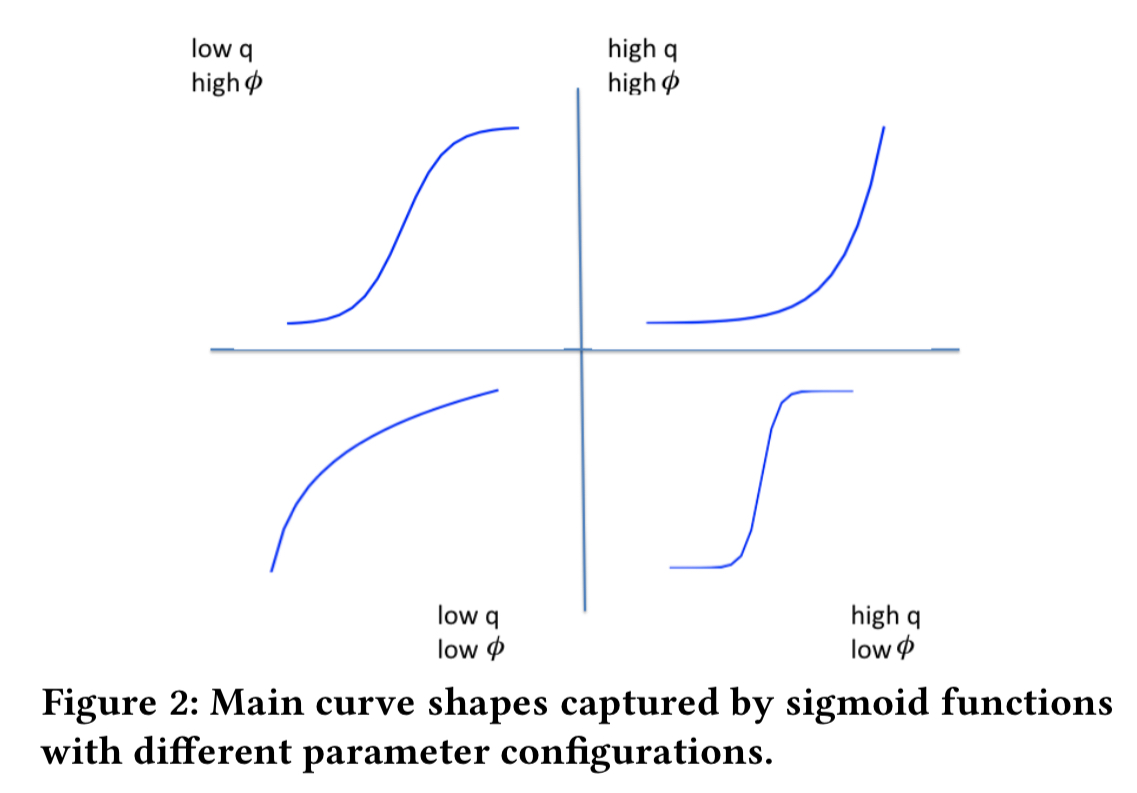
The daily activity metrics are all over the place (e.g, see below for a plot of ‘chat received’ counts). So to make things more manageable two parameters are derived: 
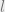
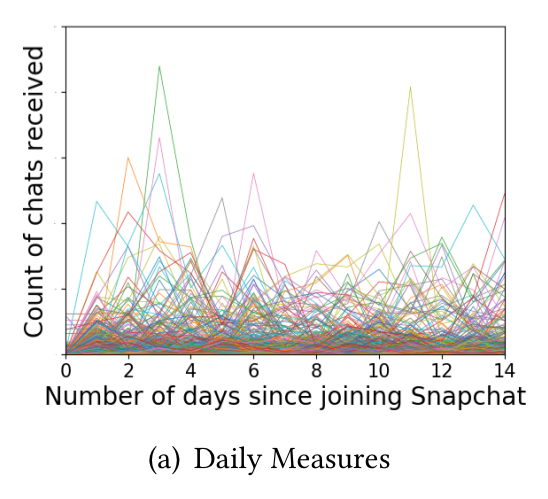
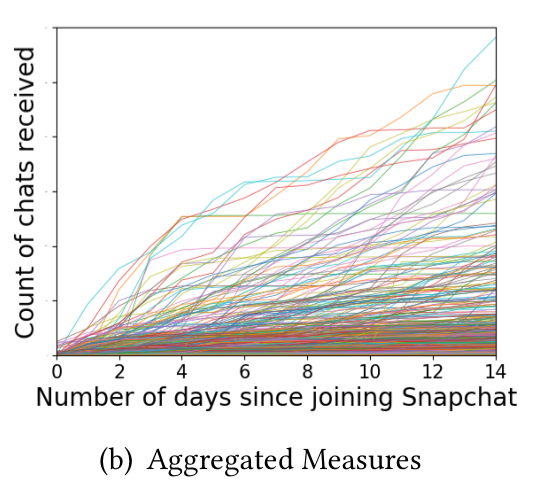
Looking at the aggregate measures (e.g. for chats received, below) we see curves with different steepness and inflection points.
These can be modelled by a sigmoid function with parameters 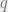
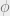
For each of the 12 attributes, we can therefore compute the four parameters 
Within the Snapchat network for the country, the authors discovered a smaller group of well-connected popular users, the core of the network. When new users make friends, many of their new friends are within the core. The hunch is that the ways new users connect to the core should be significant for user clustering and churn prediction.
With all this information in hand, we’re looking for a clustering framework that can provide insight into user types such that the type information can be readily turned into actionable items to facilitate downstream applications such as fast-response and targeted user retention.
Clustering is a three-step process:
- For each feature (e.g. chats received) k-means clustering with Silhouette analysis is used to create K clusters, where K is chosen by the algorithm. For each user we record which cluster they belong to for each feature. This process helps to find meaningful types of user with respect to each feature individually (e.g. users who constantly receive lots of chat messages).
- For each user, we derive a new feature combination vector where each element is the cluster centre of the cluster the user belongs to for that feature. (E.g. if the user is in cluster 1 for the first feature, with cluster centre
, and in cluster 3 for the second feature, with cluster centre
, then the first two elements of the feature combination vector will be
). The purpose of this step is to reduce the influence of noise and outliers.
- Now we apply k-means clustering with Silhouette analysis again, but this time on the feature combination vectors. “The multi-feature clustering results are the typical combinations of single-dimensional clusters, which are inherently interpretable.“
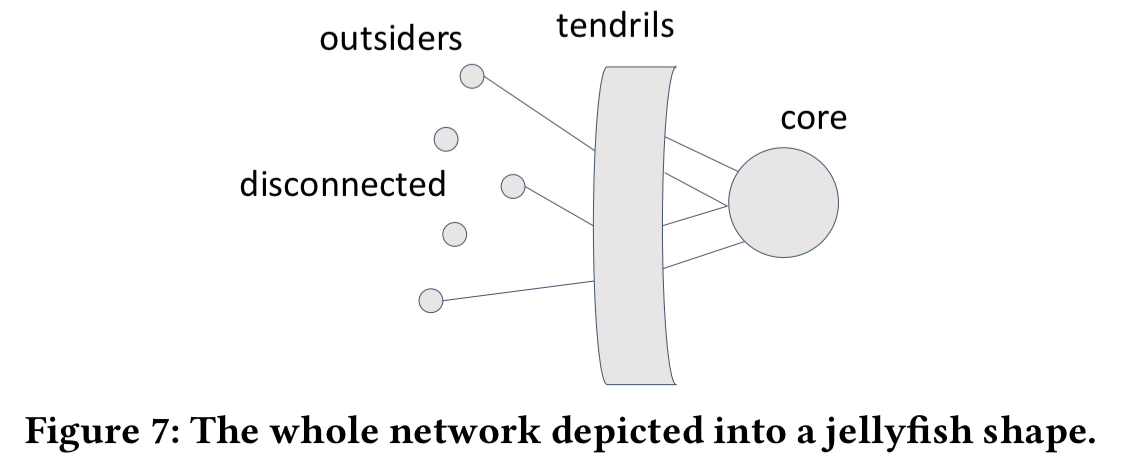
Looking at the ego-network features in particular, three types of users emerge: type 1 users have relatively large network sizes and high densities; type 2 users have relatively small network sizes and low densities; and type 2 users have minimal values on both measures:
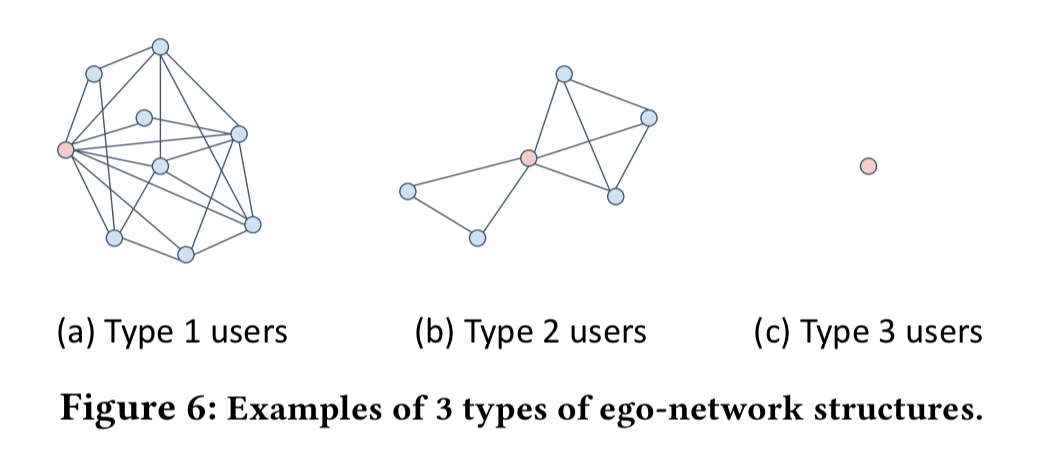
The type of network a user has is strongly correlated with their position in the whole social network. Type 1 users are mostly ‘tendrils’ with about 58% of direct friends in the core, type 2 users are primarily outsiders with about 20% of direct friends in the core, and type 3 users are mostly disconnected with almost no friends in the core.
Combining new users’ network properties with their daily activities, we finally come up with six cohorts of user types, which is also automatically discovered by our algorithm without any prior knowledge. Looking into the user clusters, we find their different combinations of features quite meaningful, regarding both users’ daily activities and ego-network structures. Subsequently, we are able to give the user types intuitive names, which are shown in Table 2.

If you look at the churn rates for different user types you can see that user type provides a lot of valuable insights. For example, the main difference between All-star users and Chatters is their activity on stories and lens; being active in these functions indicates a much lower churn rate.
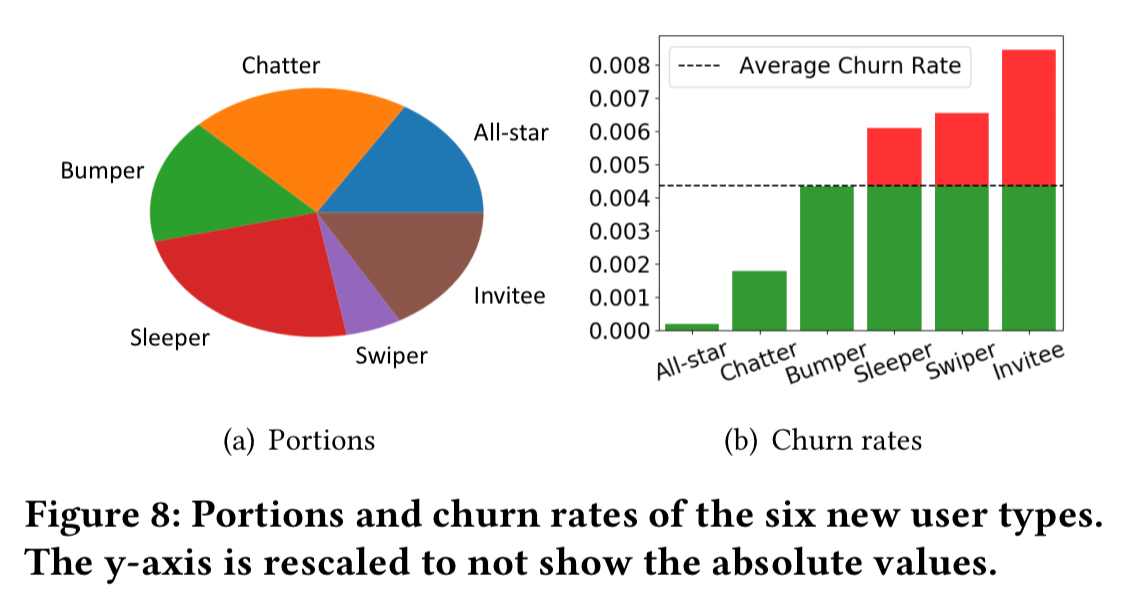
(Yes, I think we did just rediscover that users with higher engagement churn less! But, with one level deeper insight telling us what kinds of engagement matter most…).
Predicting churn in new users
We now know that the cluster (user type) of new users is highly indicative of their likely churn. Unfortunately, analysis of real data shows that new users are most likely to churn at the very beginning of their journey. I.e., before we’ve had a chance to accumulate lots of data to place them in a cluster.
The goal is to accurately predict the likelihood of churn by looking at users’ very initial behaviors, while also providing insight into possible reasons behind their churn… However, as we only get access to the initial several days instead of the whole two-week behaviors, user types are also unknown and should be jointly inferred with user churn.
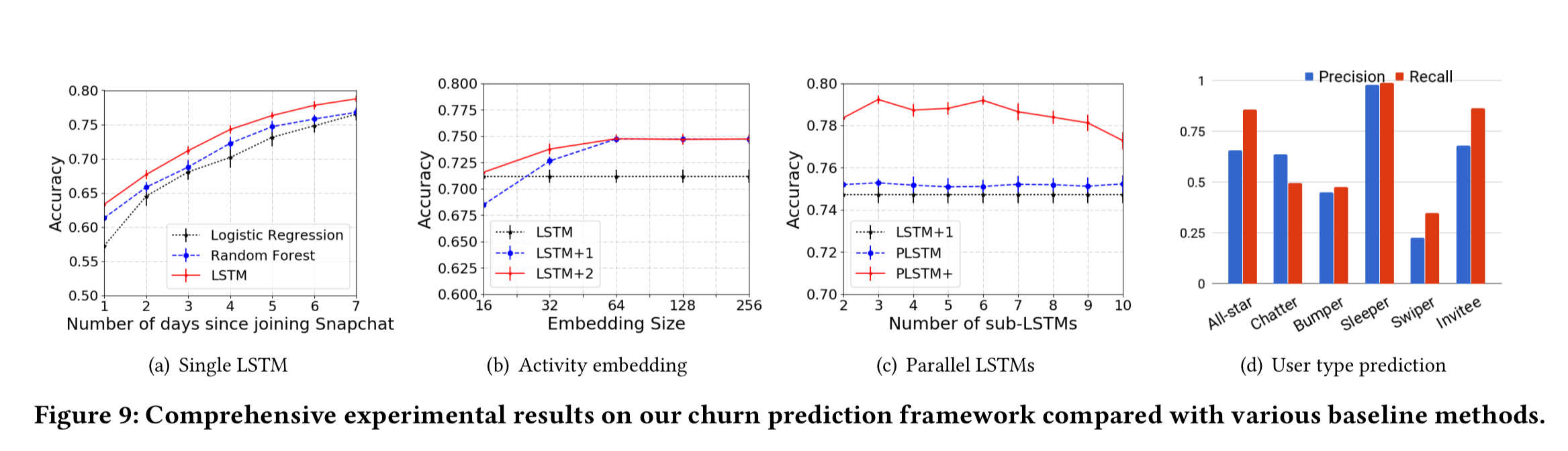
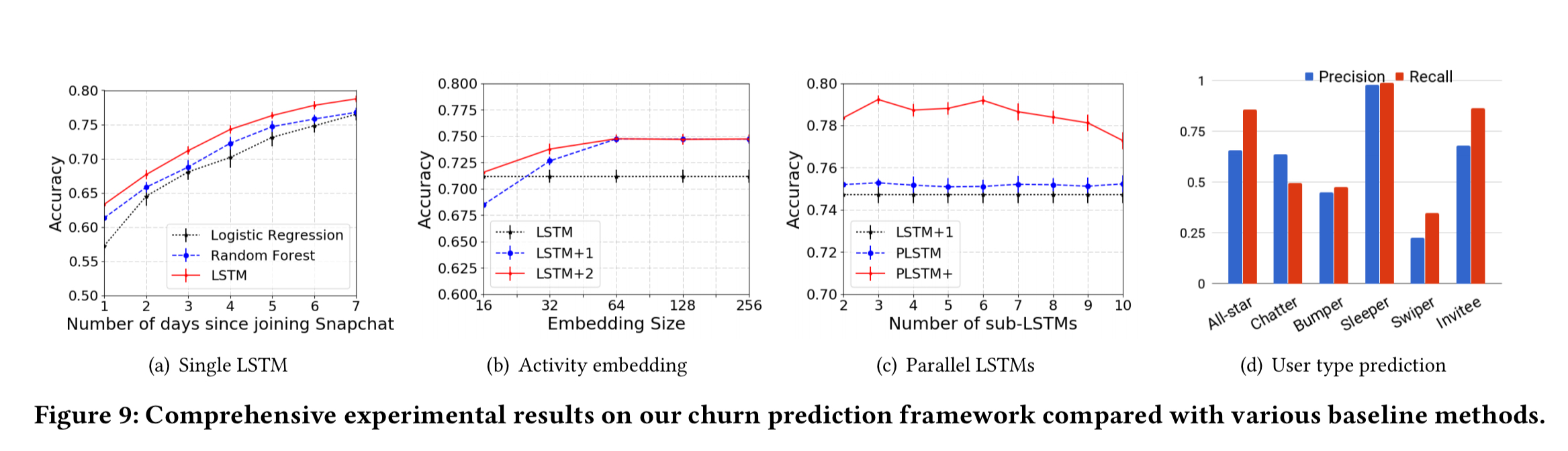
The churn and user-type inference model is developed via experiments done on an anonymous internal dataset with 37M users and 697M bi-directional links. Logistic regression and random forest churn prediction models are used as the baseline for comparisons. The resulting model is developed in three stages:
- The foundation is an LSTM sequence-to-sequence model applied to the multi-dimensional user and ego-network feature vectors. (The 12×14 vectors described at the top of this piece). A linear projection using the sigmoid function is connected to the output of the last LSTM layer to produce a user churn prediction.
- To deal with sparse, skewed, and correlated activity data, an activity embedding layer is added in front of the LSTM layers. Empirically, a single fully connected layer proved to be sufficient.
- During training, we do know the real user types as computed by the three-step clustering process. Given K user types, the next twist is to train K sub-LSTMs, one for each user type.
We parallelize the K sub-LSTMs and merge them through attention to jointly infer hidden user types and user churn.
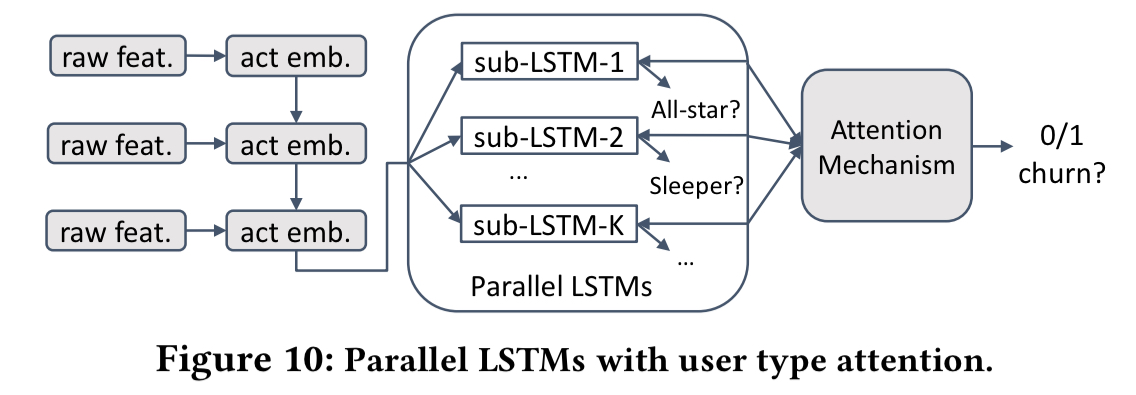
A positive attention weight is assigned to each user type to indicate the probability that the user is of a particular type. This weight is computed as a similarity of the corresponding typed output sequence (from the sub-LSTM) and a global unique typing vector jointly learned during the training process.
The following figure shows how the churn prediction accuracies improves (and compares to the baseline) as we add in these various features.
(Enlarge)
Deployment at Snap
ClusChurn is in production deployment at Snap Inc., where it delivers real-time analysis and prediction results to multiple systems including user modelling, growth, retention, and so on. In future work the authors hope to understand the connections between the different user types, as well as modelling user evolution patterns (how they change type over time) and how such evolution affects their activity and churn rate.

{kind=link}
2 thoughts on “I know you’ll be back: interpretable new user clustering and churn prediction on a mobile social application”
Comments are closed.