Bounding data races in space and time Dolan et al., PLDI’18
Are you happy with your programming language’s memory model? In this beautifully written paper, Dolan et al. point out some of the unexpected behaviours that can arise in mainstream memory models (C++, Java) and why we might want to strive for something better. Then they show a comprehensible (!) memory model that offers good performance and supports local reasoning. The work is being done to provide a foundation for the multicore implementation of OCaml, but should be of interest much more broadly. There’s so much here that it’s worth taking our time over it, so I’m going to spread my write-up over a number of posts.
Today we’ll be looking at the concept of local data-race-freedom (local DRF) and why we might want this property in a programming language.
Mainstream memory models don’t support local reasoning
Modern processors and compilers have all sorts of trickery they can deploy to make your program run faster. The optimisations don’t always play well with parallel execution though.
To benefit from these optimisations, mainstream languages such as C++ and Java have adopted complicated memory models which specify which of these relaxed behaviours programs may observe. However, these models are difficult to program against directly.
The data-race-freedom theorems enable programmers to reason about program behaviour globally. If all variables used for synchronisation between threads are atomic, and there are no concurrent accesses to non-atomic variables, then the DRF theorems guarantee no relaxed behaviours will be observed. Break the rules though, and all bets are off. What Dolan et al. highlight (we’ll see some examples in just a moment), is that there are many surprising cases where you think a piece of local code cannot possibly have a race, but in fact it does. You can’t easily apply modular or local reasoning.
This lack of local reasoning is a big issue, especially in safe languages (such as OCaml) that have compositional semantics: you should be able to understand parts of the program in isolation and reason about what happens when you put them together.
Let’s look at three C++/Java examples from section 2 of the paper which highlight the issue.
Data races in space
To support local reasoning, we’d like data races to be bound in space. This is true for Java, but not for C++. Consider the statement b = a + 10, executing in an environment in which there are no other accesses to a or b. Surely we can rely on b equaling a + 10 once this statement has executed?? It turns out this isn’t true!
Meet c. c is a nonatomic global variable that happens to be written to by two different threads:

If the elided computation in the first thread is pure (writes no memory, has no side-effects), then the compiler might optimise this code by introducing a new temporary variable t, like so:

If the elided computation also causes register pressure, we might need to save t somewhere. One option is to rematerialise t from c, since it’s value is already stored there…

Now we’ve introduced a data race on c that impacts our single line of code, and b = a + 10 can result in b being 1, regardless of the value of a!!
The particular optimisation used in step 3 here is just illustrative, and in fact is not generally implemented although it has been proposed for addition to LLVM. There are plenty of other similar races to worry about though.
Data races in time
To support local reasoning, we’d also like data races to be bound in time. This is not the case in both C++ and Java. Data races, it turns out, can time-travel! You might reasonably expect a data-race in the past to affect present behaviour, but so can data races in the future!!
As a first example, consider the program b = a; c = a; with no accesses to a, b, or c happening concurrently with the execution of those statements. We’d expect as a post-condition that b == c. However, this is not guaranteed to be true. Let flag be an atomic (volatile in Java) boolean, initially false. Now we’ll have two threads of execution using flag, like this:
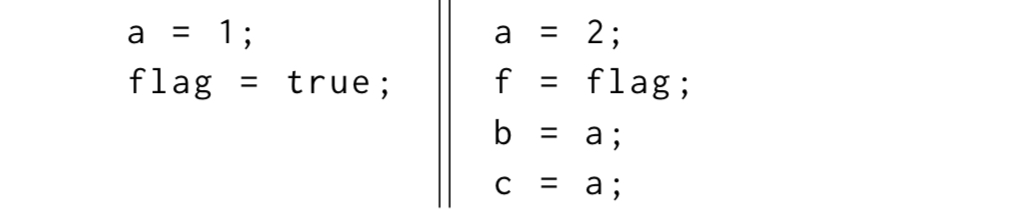
After execution, we see that f is true. Therefore we know that both of the writes to a happen-before both of the reads (the read and write of flag synchronise). But due to aliasing effects, it’s still possible in Java to end up with b == 1 and c == 2. A compiler may optimise b = a to b = 2 without applying the same optimisation to c = a. Now if the first thread wins the race to set a before the flag, we have b not equal to c!
So, the effect of data races in Java is not bounded in time, because the memory model permits reads to return inconsistent values because of a data race that happened in the past. Surprisingly, non-sequential behaviour can also occur because of data races in the future…
Take a class class C { int x; }, and the following program sequence: C c = new C(); c.x = 42; a = c.x;. By creating a brand new instance of C, we eliminate the possibility of any historic data races. Surely we can rely on a being 42 after this sequence executes? In C++ and in Java, we can’t!
Given the two threads of execution below, then in the first thread the read of c.x and the write of g operate on separate locations. This means the Java memory model permits them to be reordered. If that happens we can now be exposed to a race whereby c.x can end up with the value 7.
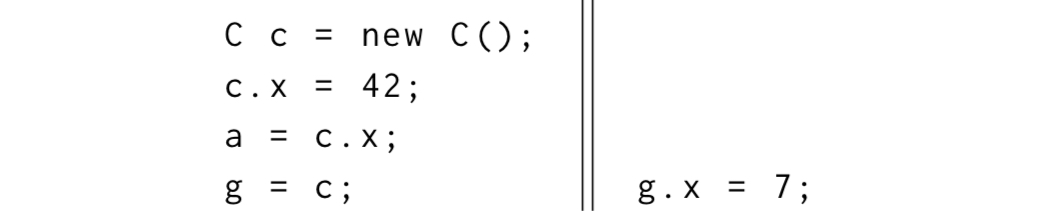
From global DRF to local DRF
The kind of examples we’ve just been looking at illustrate how hard it can be to figure out all of the potential behaviours in a parallel program. It’s a wonder things work in practice as well as they do! In all of the examples above, with the conditions specified that there are no other accesses to the variables in question, our (or is it just me?) intuition is that all of these fragments should be data race free. But that intuition is wrong. Instead of trying to balance all of the possibilities introduced by optimisations in our heads when looking at a fragment of code, could there instead be a model that makes our intuitions correct?
We propose a local DRF property which states that data races are bounded in space and time: accesses to variables are not affected by data races on other variables, data races in the past, or data races in the future. In particular, the following intuitive property holds:
If a location
ais read twice by the same thread, and there are no concurrent writes toa, then both reads return the same value.
With such a local DRF property, all of the examples above have the expected behaviour. With only the standard global DRF property however, we would also need to show that there are no data races on any variables at any time during the program’s execution.
Where we’re heading is to be able to take a fragment of code such as the examples above, and extract L, the set of all locations accessed by the fragment. Then we must show that the machine state before executing the fragments is L-Stable (doesn’t have any data races in progress on locations in L). In this case L-Stability follows from the assumptions given for each example.
Local DRF then states that the fragments will have sequential behaviour at least until the next data race on L. Since the fragments themselves contain no data races on L, this implies that they have the expected behaviour.
I.e., I can reason about their behaviour locally. That sounds like a property I’d like my programming language to have!
In part II tomorrow, we’ll look at how local DRF can be achieved in practice.

I would say that “data race in the future” is a bit of stretch: we are talking about position in code, not time. A race itself still happens _before_ the reading from the memory that confuses us.
Note that in C++ data races are “undefined behavior” so you can’t have any expectations about observed value, even if it occurs earlier in the code. I think that reasoning about races is still productive! Waiting for part 2!
I would say that “data race in the future” is a bit of stretch: we are talking about position in code, not time. A race itself still happens _before_ the reading from the memory that confuses us.
Note that in C++ data races are “undefined behavior” so you can’t have any expectations about observed value, even if it occurs earlier in the code. I think that reasoning about races is still productive! Waiting for part 2!
Whoa…. the first example, with a being equal to 1, is **WRONG**. If variable “c” is a global tha is visible/modifiable by an external source (e.g. from an interrupt, another thread, whatever) – then the compiler cannot assume that it’s safe to rematerialize from it. What you describe as an “optimization” would actually be a compiler bug (I worked on an optimizing C++ compiler; we would _definitely_ treat it as a bug).
Whoa…. the first example, with a being equal to 1, is **WRONG**. If variable “c” is a global tha is visible/modifiable by an external source (e.g. from an interrupt, another thread, whatever) – then the compiler cannot assume that it’s safe to rematerialize from it. What you describe as an “optimization” would actually be a compiler bug (I worked on an optimizing C++ compiler; we would _definitely_ treat it as a bug).
And for the second example (data races in time)… I can’t find direct requirements in the standard, but our compiler treated “volatile” accesses as boundaries for optimisation – i.e. in your example, I think it would not propagate constants across the read of “flag”, and it certainly wouldn’t move the code around. I do remember though that we felt we were stricter than what the standard required, it was just that a lot of surprising (and often, wrong) behavior would happen if we tried to optimize around volatiles.
So, what I’m saying is that, I’m not sure that the optimisation you propose is be legal under the abstract C execution model – though, I admit that it might be; but even if it is, things are muddled enough that I believe most compilers won’t behave like that/ won’t apply that sort of optimisation.