HHVM JIT: A profile-guided, region-based compiler for PHP and Hack Ottoni, PLDI’18
HHVM is a virtual machine for PHP and Hack (a PHP extension) which is used to power Facebook’s website among others. Today’s paper choice describes the second generation HHVM implementation, which delivered a 21.7% performance boost when running the Facebook website compared to the previous HHVM implementation.
…the PHP code base that runs the Facebook website includes tens of millions of lines of source code, which are translated to hundreds of megabytes of machine code during execution.
I’m clearly suffering from an over-simplified understanding of what the Facebook web application actually does, but at the same time if I asked you to write a Facebook clone for just the website (not the backing services, not the mobile apps, etc.), would your initial estimate be on the order of tens of millions of lines of code???!
HHVM high-level overview
The starting point for HHVM is source code in PHP or Hack. Hack is a PHP dialect used by Facebook and includes support for a richer set of type hints. From the perspective of HHVM though the two languages are fundamentally equivalent. In particular, Hack’s type hints are only used by a static type checker and are discarded by the HHVM runtime.
The reason for discarding these richer type hints at runtime is that Hack’s gradual type system is unsound. The static type checker is optimistic and it ignores many dynamic features of the language. Therefore, even if a program type checks, different types can be observed at runtime…
Source code is parsed by the HipHop compiler (hphpc) to produce an abstract syntax tree (AST). HHVM v2 adds a new HipHop Bytecode-to-Bytecode compiler (hhbbc) which translates the AST into HHBC, the bytecode of HHVM. A number of analyses and optimisations are performed during the translation into HHBC, all of which are done ‘ahead-of-time,’ i.e., before the program actually executes.
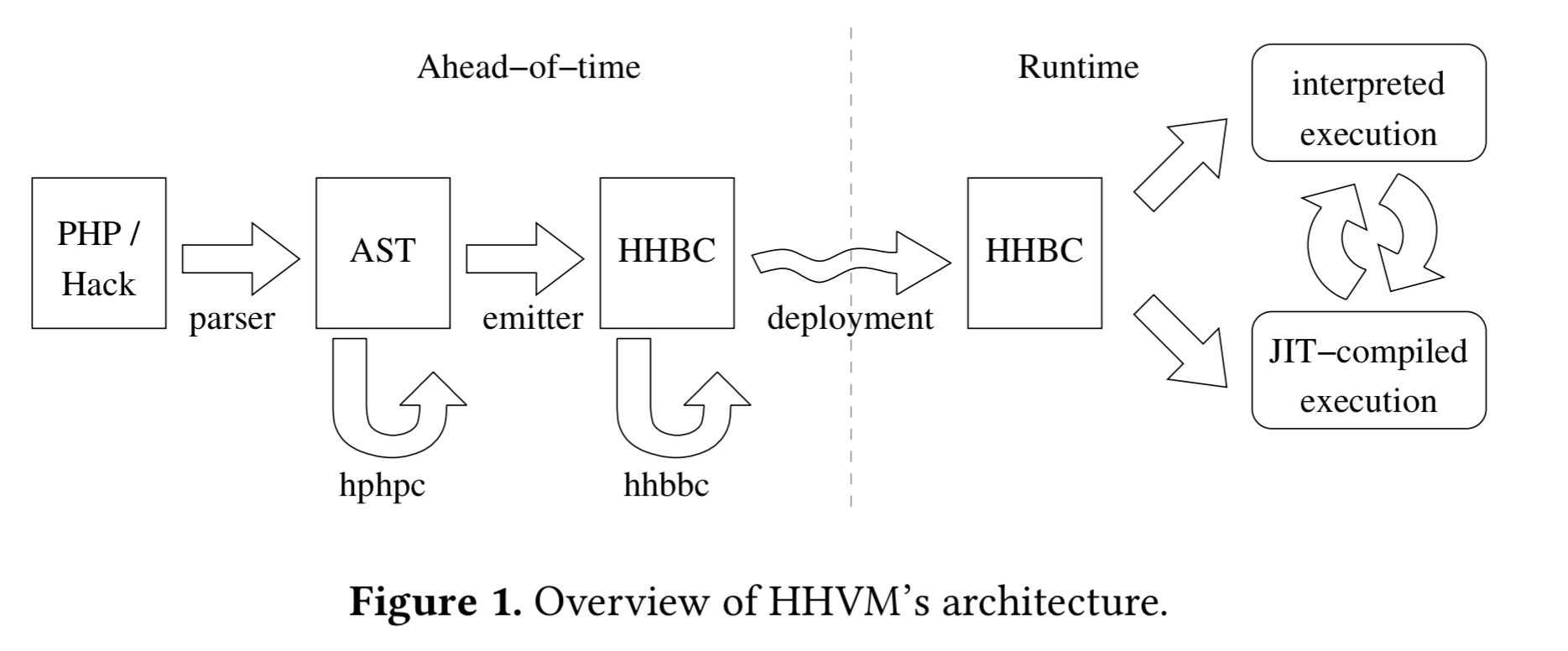
HHBC is a stack-based bytecode, meaning that the majority of the bytecode instructions either consume inputs from or push results onto the evaluation stack, or both.
At runtime, HHVM combines a traditional threaded interpreter and a JIT compiler. An important feature of the JIT design is its use of side-exits which use on-stack replacement (OSR) so that compiled code execution can always stop at any (bytecode-level) program point and transfer control back to the interpreter, the runtime system, or to another compiled code region.
This ability to always fallback to the interpreter means that the JIT is free to focus on the mainline use cases and avoid all of weird corner cases that can occur in a dynamic language (e.g., multiplying a string by an array!). For large-scale applications, it also helps to manage CPU and memory overheads incurred by JIT compilation since not everything needs to be JIT-compiled.
The core of the paper describes the design and implementation of the new HHVM JIT.
The new HHVM JIT
The HHVM JIT is designed around four main principles:
- Type specialisation
- Profile-guided optimisations
- Side exits
- Region-based compilation
Although each of these principles has been used by a number of previous systems, the combination of these four principles in a dynamic-language JIT compiler is novel to the best of our knowledge.
Type specialisation uses type information —which can be obtained either statically or dynamically— to generate type specific code. For example, code specialised to integers (which are not reference counted) can be more efficient. There’s a trade-off to be made here between the performance boost of specialised code, and the overheads of generating lots of type-specific routines (over-specialisation).
One of the key sources of dynamic type information that the HHVM JIT uses is profiling.
Profile-guided optimizations (PGO), also called feeback-driven optimizations (FDO), are a class of optimizations that can be either enabled or enhanced by the use of runtime information.
Beyond informing type specialisation, the profile information is also used for code layout and method dispatch.
Side-exits (aka uncommon traps) allow the JIT to specialize the code for common types without supporting the uncommon types that may not even be possible at runtime.
Code generation in HHVM is based on regions (region-based compilation), where regions are not restricted to entire methods, single basic blocks or straightline traces. Region-based compilation works well with type specialisation, profile-guide optimisations, and side-exits: profiling highlights regions that are then used to compile generated code for common types, with side-exits to fall back to interpreted execution in less common cases.
The data structure used to represent regions at the bytecode level is a region descriptor. Region descriptors contain a control-flow graph (CFG), in which each node is a basic-block region used for profiling. For every block, a region descriptor contains:
- the sequence of bytecode instructions
- preconditions (type guards)
- post-conditions (known types at the end of the translation)
- type constraints (encoding information about how much knowledge is required for each input type in order to generate efficient code).
Region descriptors are lowered into a HipHop Intermediate Representation (HHIR), a typed representation using static single assignment (SSA) form. The type information comes from the hhbbc compiler and from profiling data. The HHIR level is where most of the code optimisations happen.

At a level below HHIR is a Virtual Assembly (Vasm) representation. It’s instruction set is very close to machine code, but supports an infinite number of virtual registers.
There are three different compilation modes within the HHVM JIT: live translations (the only kind supported in the first generation implementation), profiling translations (basic optimisations plus the insertion of block profiling), and fully optimised translations.
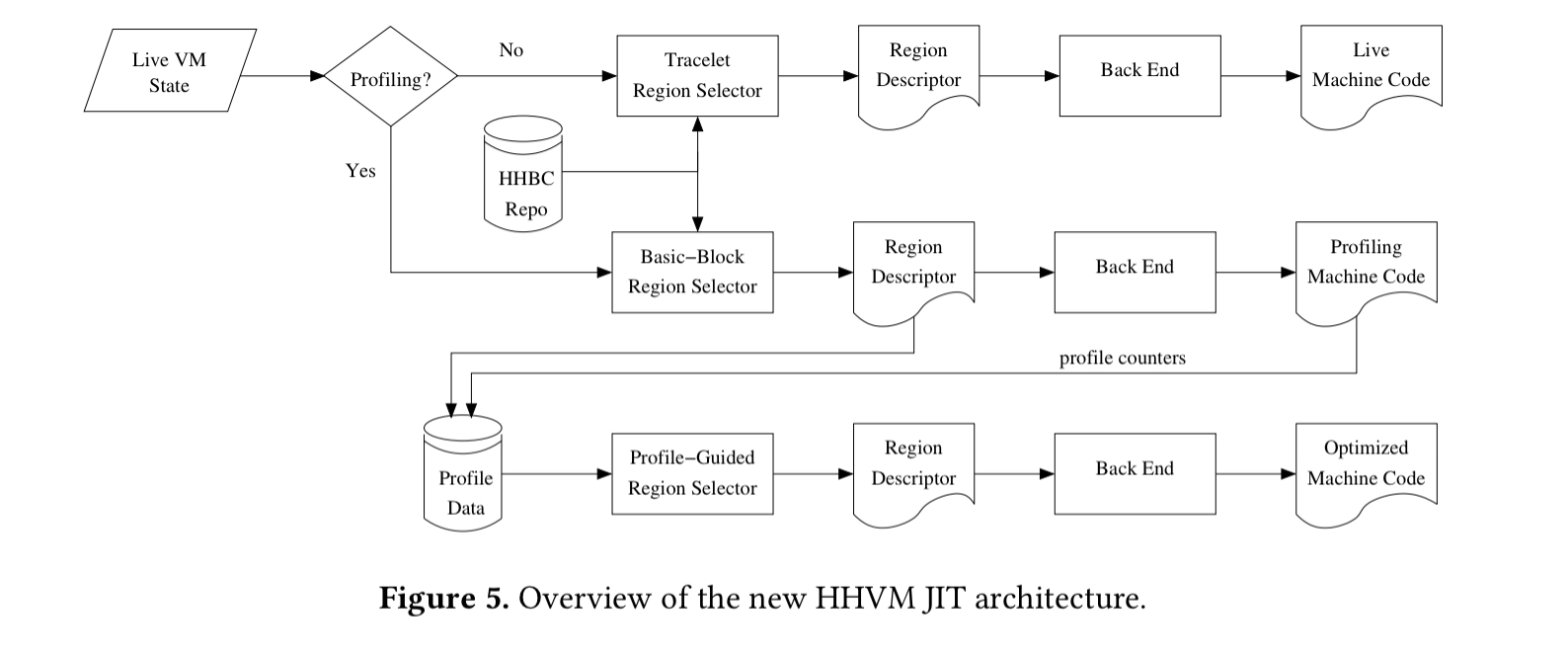
Important optimisations
The full optimisation pipeline applies optimisations at each level of abstraction, as summarised in the figure below.
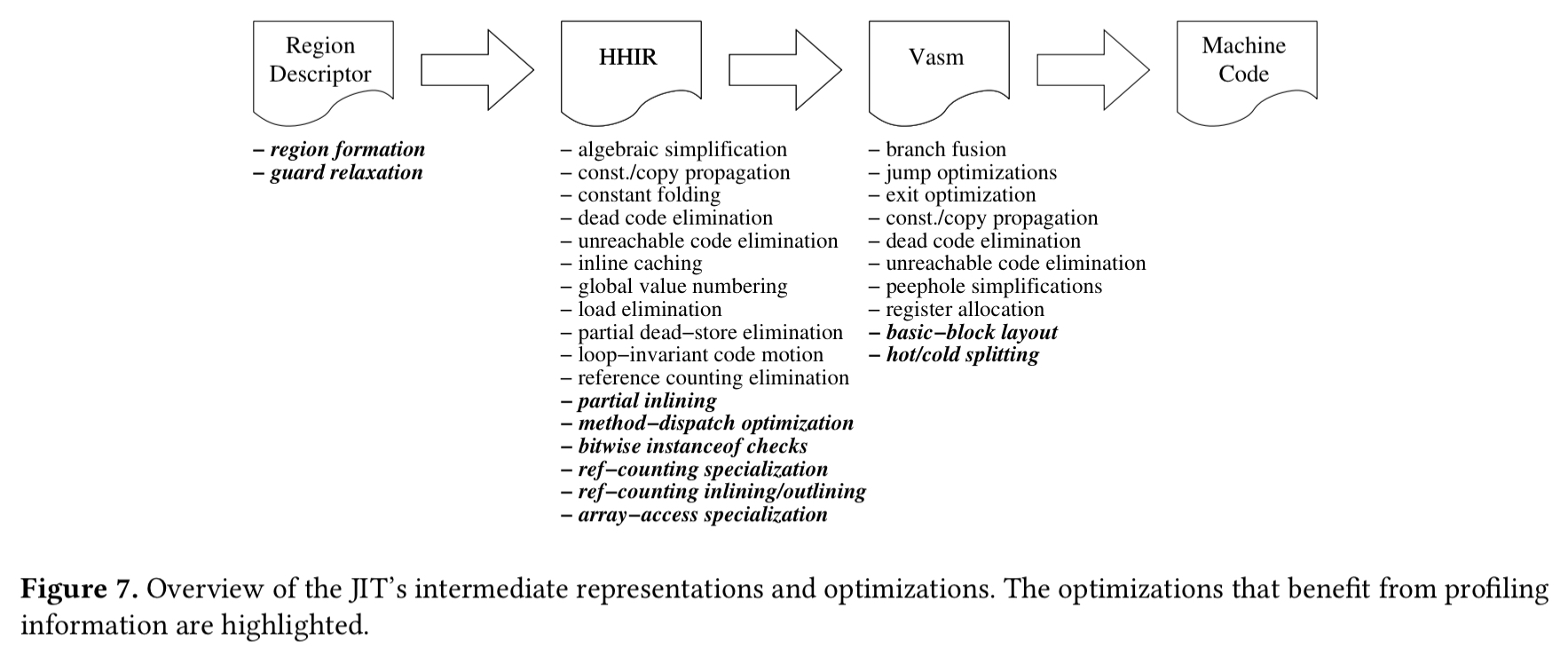
Prior to the region-based optimisations, there are also a couple of important whole-program optimisations.
Whole-program
- Function sorting places functions that commonly call each other close by in memory. A weighted directed call graph is built for the program, using basic block profile counters to inform the weights. Then the functions are clustered and sorted. The algorithm is fast enough to handle the large amount of code generated to support the Facebook website in under one second.
- Huge pages: once the hot code is clustered in the code cache, this in then mapped onto huge pages.
Region-level
- For live and profiling translations, regions are formed by inspecting the VM state and flowing live types. For optimised translations the collected profile information is used. A single function may be broken into multiple regions, and conversely a region may contain portions of multiple functions (through partial inlining). Each function is associated with a weighted CFG for all the blocks within it, which are grouped into regions using a depth-first search with blocks and arcs optionally skipped based on their weights.
- Guard relaxation helps to avoid over-specialisation, where the compiler specialises code excessively, leading to code bloat. As the name suggests, guard relaxation weakens type guard pre-conditions in some circumstances to allow more types to go through. Of course, the corresponding generated code will be slightly less efficient as it must now cope with more types – but it can still be much better than fully general code. As an example, an integer-only guard may be relaxed to allow integers and doubles.
HHIR-level
- Partial inlining is used to inline common simple methods such as getters and setters (it’s partial because full inlining can lead to code bloat).
- PHP uses reference counting to manage memory for common types such as strings, objects, and arrays. Naive reference counting solutions can lead to significant overheads. The HHVM JIT uses reference counting elimination to avoid reference counting where possible. The essence of the idea is to sink increment instructions in the call graph where it is provable safe. If an increment instructions sinks such that it is now next to a decrement instructions, then the pair can be eliminated.
- Method dispatching is optimised using information from the profiler. Specialised HHIR is emitted to (a) devirtualize momomorphic calls, (b) optimise calls from a common base class, and (c) optimise calls where the methods implement the same interface.
Vasm-level
- Register allocation is implemented using the Wimmer and Franz linear scan register-allocation algorithm.
- Code layout is optimised (block layout and hot/cold splitting). “The algorithms used for these purposes are the traditional techniques proposed by Pettis and Hansen.“
Evaluation
The evaluation is based on measurements taken from the Facebook website running on HHVM. The top line results can be seen in the following figure, which takes a bit of interpreting:
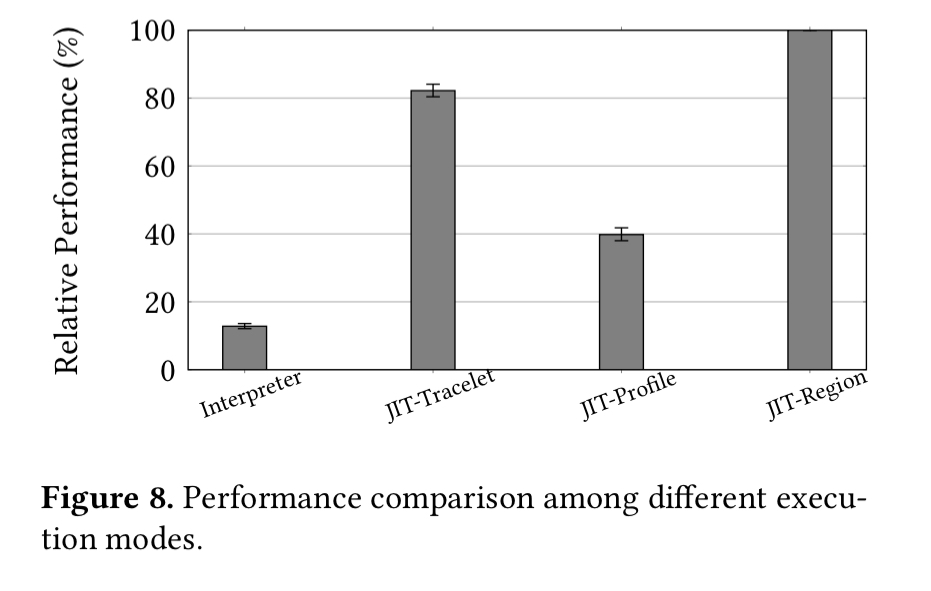
The ‘JIT-region’ bar shows the performance of the full optimisation path, normalised to 100%. The previous generation of the HHVM JIT only support live translation, and it’s performance is represented by the ‘JIT-Tracelet’ bar. The live translation path achieves 82.2% of the full optimisation performance, or put another way, the region JIT in HHVM v2 provides about a 21.7% speedup. The performance achieved by the profile translations only is show in the ‘JIT-profile’ bar (about 39.8% of the full optimisation performance). Even the profile translation on its own generates code that is 3.1x faster than interpreted code.
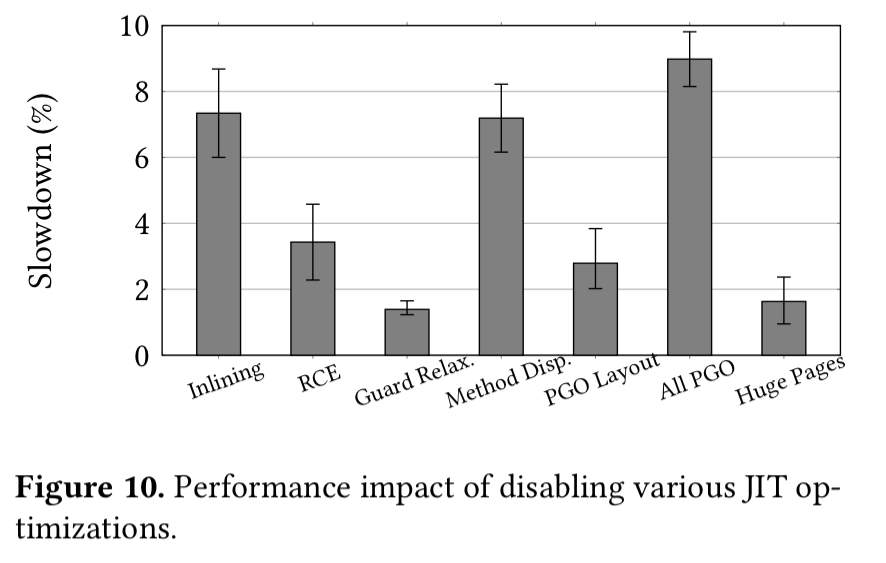
The contribution of the various optimisations can be seen in the following chart, which explores the relative slowdown with selectively disabling individual optimisations.

To be fair, I don’t think the comment about tens of millions of lines of code refers specifically to the website, I would guess that it refers to the entire server-side PHP code base, of which the website itself may be just a relatively small part.
Thanks, interesting paper even if the performance evaluation (or is that inverse relative slowdown investigation?) appears to be annoyingly obfuscated in the original.
Most if not all of the techniques do seem familiar from various papers, but it’s quite useful to see them operating together, and producing speedup, on a huge app. Native code compilers often have problems with those.