Privacy risks with Facebook’s PII-based targeting: auditing a data broker’s advertising interface Venkatadri et al., IEEE Security and Privacy 2018
This is one of those jaw-hits-the-floor, can’t quite believe what I’m reading papers. The authors describe an attack exploiting Facebook’s custom audience feature, that can leak your PII.
Specifically, we show how the adversary can infer user’s full phone numbers knowing just their email address, determine whether a particular user visited a website, and de-anonymize all the visitors to a website by inferring their phone numbers en masse. These attacks can be conducted without any interaction with the victim(s), cannot be detected by the victim(s), and do not require the adversary to spend money or actually place an ad.
Following responsible disclosure of the attack vectors to Facebook, Facebook acknowledged the vulnerability and have put in place a fix (not giving audience size estimates under certain scenarios). The experiments conducted by the authors were performed between January and March 2017, and presumably the disclosure happened around that time or shortly afterwards. That probably means your PII on Facebook was vulnerable from when the custom audiences feature was first introduced, until early 2017. Someone with more time could probably put an exact date on it by looking to see when the change was rolled out, presuming it was announced in some manner.
Custom audiences
We explored custom audiences a little earlier this year when we looked at Facebook’s transparency mechanism. In short: whereas old-school targeted advertising let you build an audience by specifying desired attributes, custom audiences allow you to upload personally identifying information (PII) about specific users, and the platform searches for matches and builds an audience out of those.
The custom audience feature has proven popular with advertisers: it allows them to directly select the users to whom their ad is shown, as opposed to only selecting the attributes of the users.
An advertiser including a Facebook code (traditionally referred to as a tracking pixel) on their site can also build a tracking pixel audience based on Facebook users that visit the site.
Custom audience creation at Facebook is done using a web interface where you can upload up to 15 different types of user information for matching. Any one of email address, phone number, mobile advertiser ID, Facebook app user ID, and Facebook page user ID can be used on its own to create a custom audience. Other attributes may be used in combination with one of these. A few hours after uploading the PII, your audience will be available. Facebook requires at least 20 users in a custom audience, other platforms offering similar functionality (see table below) often require hundreds of users or more.

Information available for custom audiences at Facebook
Once the audience has been created, Facebook will give you an approximate indication of the audience size (the number of matched records). Also of interest is the potential reach: this is a measure of the number of active users in the audience (as opposed to dormant Facebook accounts). Active users within the audience are called targetable users in this paper.
Things get more interesting with the ability to combine audiences using include (union) and exclude (set minus) operators. The result is called a combined audience. You can include or exclude audiences that have fewer than 20 users.
On the audience comparison page advertisers can measure the overlap (audience intersection size) between different PII-based audiences they have created. This feature requires audience sizes of at least 1,000, and shows the audience size intersection (not the potential reach) intersection.
None of the sizes above are given as exact numbers (that would make for trivial attacks), instead they are all given as approximate values. Through a series of controlled experiments the authors deduce the following:
- Potential reach values have a minimum size of 20, and are always multiples of 10. Up to 1,000 the values are always a multiple of 10. Between 1,000 and 10,000 they are multiples of 100. Between 10,000 and 100,000 they are multiples of 1000, and above 100,000 they are multiples of 10,000. Potential reach values are stable in the face of repeated queries in the short term, and largely consistent over longer timescales. Furthermore, potential reach numbers always increase monotonically when adding more users to the uploaded list.
- Audience sizes are multiples of 10 up to 100, and multiples of 100 thereafter. Audience size numbers are stable and have similar monotonicity to potential reach.
- Audience size intersection is also stable and monotonic, but the rounding works differently: the intersection size is rounded in steps of 5% of the smaller audience size. E.g. if we intersect an audience of size 1000 and an audience of size 4,500, we get an answer that is a multiple of 50.
Facebook also applies de-duplication when giving counts.
We found that when Facebook has an audience – or combination of audiences – that was created with different PII that both refer to the same user, Facebook only “counts” that user once when reporting the potential reach, audience size, or audience intersection size.
This de-duplication happens both within a single audience and across combinations or intersections of audiences.
Threshold audiences
Suppose for a moment Facebook gave you exact counts. You could learn whether an individual was in a given audience or not (and recall that with includes and excludes you can create audiences down to a single user) by finding the size of an audience, then adding the user in question and getting the size again. If it goes up by one, the user was not in the audience, and vice-versa. Using this same idea, we can also explore audience sizes that lie on rounding boundaries…
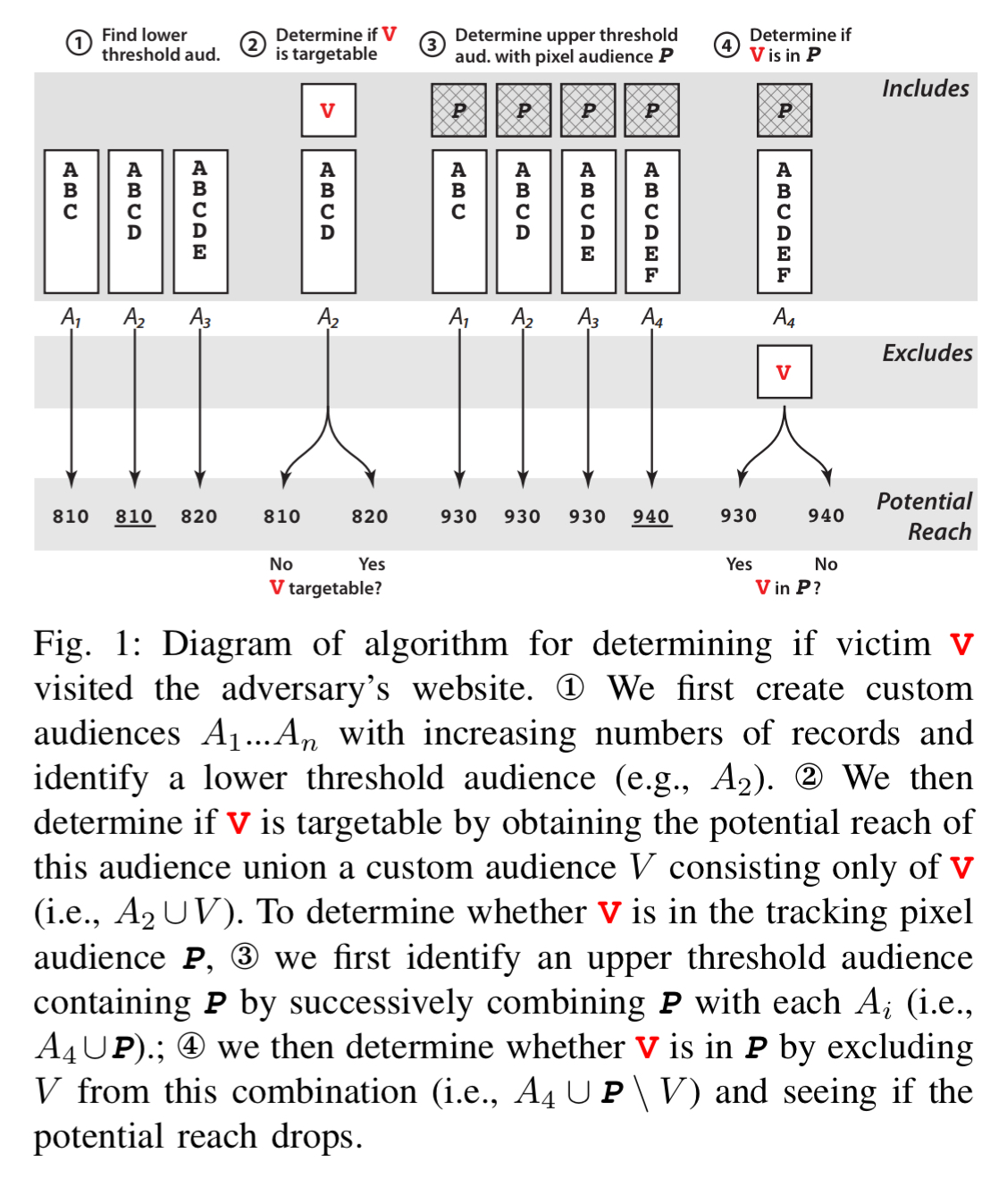
The insight behind the method is to create a threshold audience: an audience or combination of audiences where the size statistic of interest – potential reach, audience size, or audience intersection size – lies right before or right after Facebook’s rounding threshold. We call an audience with a size right before the threshold a lower threshold audience, and an audience with a size right after the rounding threshold an upper threshold audience.
E.g., if Facebook is rounding to the nearest 10, then 84 is a lower threshold audience and adding one makes the reported size jump from 80 to 90. In other words, we’re back in the situation where an individual users results can be discerned in the outputs.
How do you find a lower threshold audience? Upload a sequence of lists, each with one more record than the previous one. At the point where the reported size jumps up from that of the list with one less member (e.g., from 810 to 820), you have yourself a lower threshold audience.
Have you visited my site?
The warm-up example shows how to de-anonymise website visitors. Let’s make things a bit more entertaining and say you run an adult-oriented site, and want to know if a certain celebrity frequents it.
Start with your lower threshold audience, combine it with an audience containing just your target victim, and if the potential reach changes, that person has an active Facebook account. Assume that you use a tracking pixel on your website so that you have a tracking pixel audience available to you. Find an upper threshold audience (using the same ‘lists that differ by one technique’ by trying difference combinations of tracking pixel audience + a list you control). Now ask for the audience size using your upper threshold audience combined with an exclusion list with just the victim in it. If the audience size drops, that victim was in your tracking pixel audience. You just discovered whether a certain celebrity has frequented your adult site.
What’s your phone number?
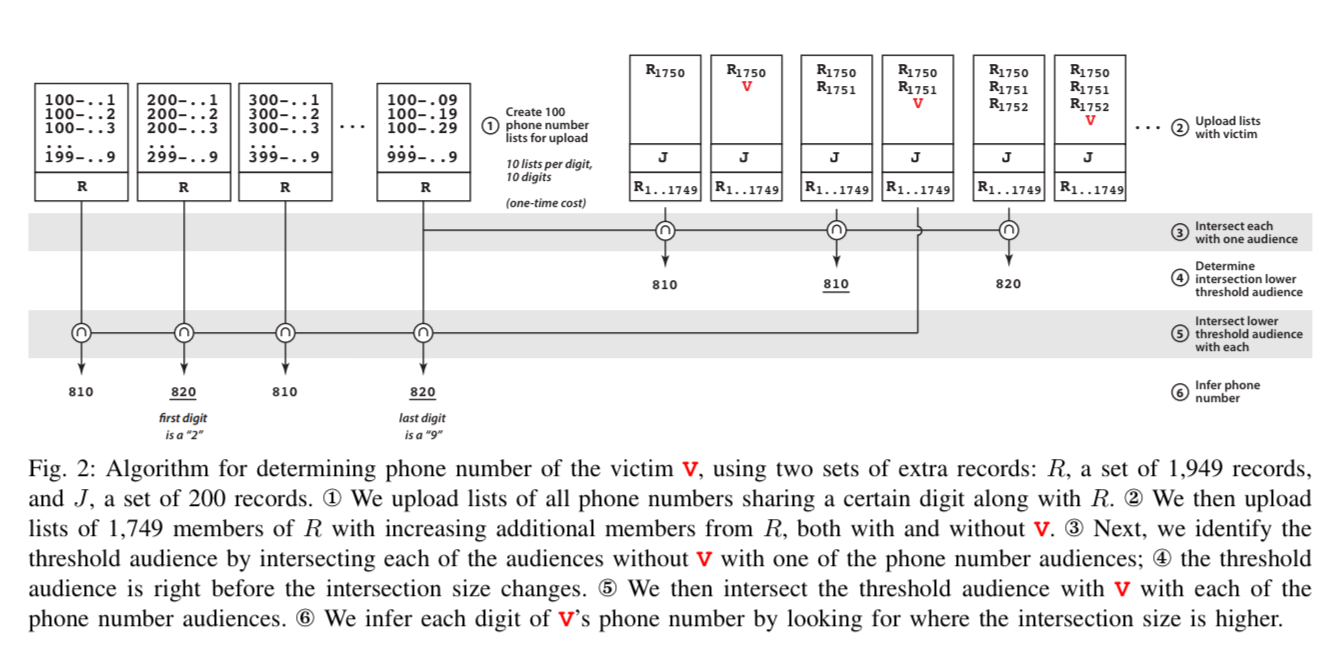
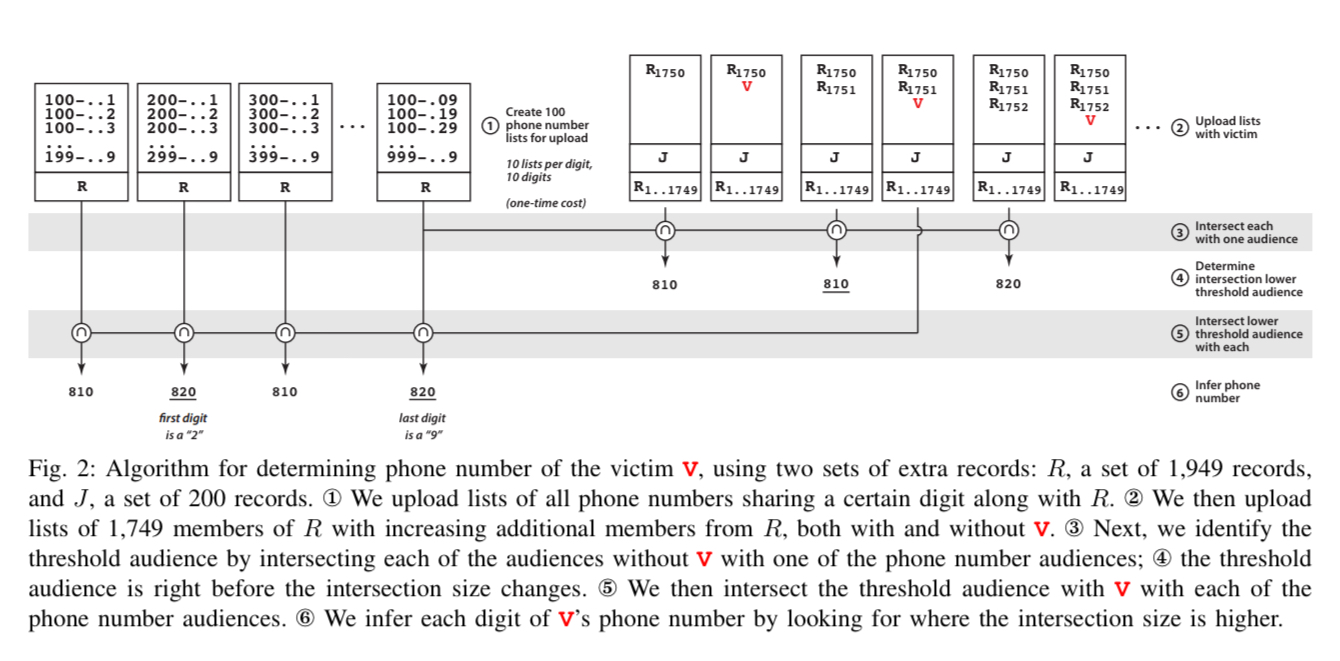
Things are progressing nicely. Maybe we want to blackmail our celebrity, and to do that it would be jolly handy if we could phone them up and tell them what we know. How can we get their phone number though? The details of how to do this are in section V.B of the paper. At the core it relies on the same threshold audience ideas, combined with the audience size intersection capability. With a minimum set size of 1,000 for intersection, and granularity based on 5% of the smaller set, we have to contend with jumps of 50 users.
Take 1,999 users with known PII, and divide them into two sets R and L, where R has 1,949 members, and L has the other 50. Upload two custom audiences: C1 is the union of R and L, and C2 is the union of R, L, and the victims PII. (There’s a twist on this basic idea that accounts for the fact we don’t necessarily know that all 1,999 initial users have active Facebook accounts, it uses similar probing in sequences approach to find a lower threshold intersection).
How does that help us get a phone number?? A phone number is one of the types of PII we can match on. So we create subsets lists 
(Enlarge)
Using this technique it took 140 lists to cover all of Boston, and 82 lists to detect French mobile numbers. It took about 20 minutes to successfully recover the phone numbers of study participants from France (8/8) and Boston (11/14). For the three cases that failed in Boston, one had never provided their phone number to Facebook, and the other two had provided multiple phone numbers which confused the matching. The appendix shows how to handle this case.
Just tell me everyone’s phone numbers!
The final flourish is to recover the phone numbers of every visitor to a website (i.e., in a tracking pixel audience). It combines the upper threshold trick we saw before to de-anonymise website visitors, with the multiple phone-list audiences approach. Full details are in section V.C of the paper.
An experiment successfully determined the phone numbers of nine study participant volunteer visitors to a website.
Our method took around one hour to do the entire search and output the phone numbers by sending queries to Facebook in a serial fashion; this time could be cut down significantly by parallelizing the queries sent to Facebook.
You can use your imagine to figure out how to build custom audience lists to discover other kinds of PII about your victims. The potential also exists for similar attacks on other platforms (e.g. Instagram, Google, Twitter, Pinterest, LinkedIn), “but due to space constraints we leave exploring them to future work.”
Closing the loophole
The authors propose a change to the way Facebook deals with audience de-duplication when reporting audience information, which balances advertiser utility (wanting to know about sizes) with privacy preservation. Facebook actually went with something simpler:
Facebook has acknowledged the vulnerabilities reported in this paper and has confirmed to us that it has deployed a stricter version of our defense: no size statistics will be provided for audiences created using multiple PII attributes. Additionally, no size estimates will be provided when combining audiences that were created using different PII attributes.
So it’s good that this is now fixed, but it’s bad that such a vulnerability existed in the wild for quite some time. We’ll probably never know how much it was exploited if at all. Platforms whose business is all about the collection and monetisation of PII have a duty to protect that information. Their privacy teams really should know that an interface that produces different results based on the presence or absence of a single record is a bad idea for privacy.
While we have proposed a solution to the attacks we uncovered, our work shows that platforms need to carefully audit their interfaces when introducing PII-based targeting.

{kind=link}
Reblogged this on On.the.move.