Investigating ad transparency mechanisms in social media: a case study of Facebook’s explanations Andreou et al., NDSS’18
Let me start out by saying that I think it’s good Facebook are making an effort to provide more transparency to advertising. It’s good that Twitter announced they will do something similar too. It’s a shame though that in Twitter’s case they don’t seem to have followed through by actually releasing anything (it’s possible I’m wrong on this and missed the release – let me know if so!). And as today’s paper choice reveals, it’s a shame that in Facebook’s implementation they seem to be making some choices that considerably mask the truth, making the explanations provided significantly less useful than they otherwise could be.
I particularly like the experiment setup in the paper. If you’re going to assess advertisement explanations, then ideally you need to compare the explanation given to the ground truth (i.e., the targeting attributes that were actually used). Unfortunately the ground truth is an unknown of course… unless you also happen to be the advertiser!
For our experiments, we develop a browser extension that collects the ads users receive every time they browse Facebook, their respective explanations, and the attributes listed on the Ad Preferences Page; we then use controlled experiments where we create our own ad campaigns and target the users that installed our extension.
26,173 unique ads and explanations are collected from 35 users spread across three countries in Europe as well as the U.S.. Then the team ran 135 different ad campaigns gathering 254 explanations for their own ads. Compared to Facebook’s scale of course, that’s tiny. However, as the authors point out: “while proving that explanations always satisfy certain properties is likely impossible even with a much larger user base, proving that explanations fail to satisfy certain properties only requires one example.”. (Strictly, the authors should add the word “sometimes” to that last clause, as in ‘explanations sometimes fail…’).
When examining ad explanations provided by Facebook, the key finding is that explanations are often incomplete, and sometimes misleading. Suppose that an advertiser uses several attributes for targeting, the explanations will include at most one of those attributes. If you were going to pick just one attribute of course, then the one with the most explanatory power would probably be the one with the smallest population (i.e., fewer Facebook users with that attribute). But Facebook’s explanations appear to show only the most prevalent attribute (e.g., ‘people in the millennials audience’). This makes the explanations incomplete in a very unhelpful way.
The way Facebook’s ad explanations appear to be built — showing only the most prevalent attribute — may allow malicious advertisers to easily obfuscate ad explanations from ad campaigns that are discriminatory or that target privacy-sensitive attributes.
Explanations can be misleading in the sense that they sometimes suggest attributes never specified by the advertiser “may” have been selected. This part of the explanation always contains age, location, and gender information regardless of what the advertiser actually specified.
Of course there’s a trade-off here since advertisers don’t necessarily want their competitors to know what mechanisms they’re using for targeting, so some obfuscation is to be expected. Just perhaps not this much.
Let’s take a quick look at the advertising mechanisms in play on Facebook before diving into the results in a little more detail.
Advertising on Facebook
There are three components involved in determining whether or not you see a given ad on Facebook:
- The data (profile) that Facebook has assembled on you. This combines information collected about you online with information bought offline from data brokers. The result is a set of targeting attributes that advertisers can use to target you.
- The audience selection process by which an advertiser expresses who should receive their ads. A set of targeting attributes collectively specify an audience. When creating a campaign, advertisers also specify whether they want to optimise for ‘reach’ or for ‘conversions’. Put more crudely, do you want to maximise impressions, or clicks?
- The run-time ad matching process that takes place whenever someone is eligible to see an ad. It compares all the relevant ad campaigns and their bids and runs an auction to determine what ads are selected.
This paper focuses on parts (1) and (2) – what data Facebook has about you, and what attributes advertisers are using to build audiences. One special kind of audience is the custom audience.
In brief, custom audiences allow advertisers to upload a list of PII — including email addresses, or phone numbers, or names along with ZIP codes — of users they wish to reach on Facebook. Facebook then creates an audience containing only the users who match the uploaded PII.
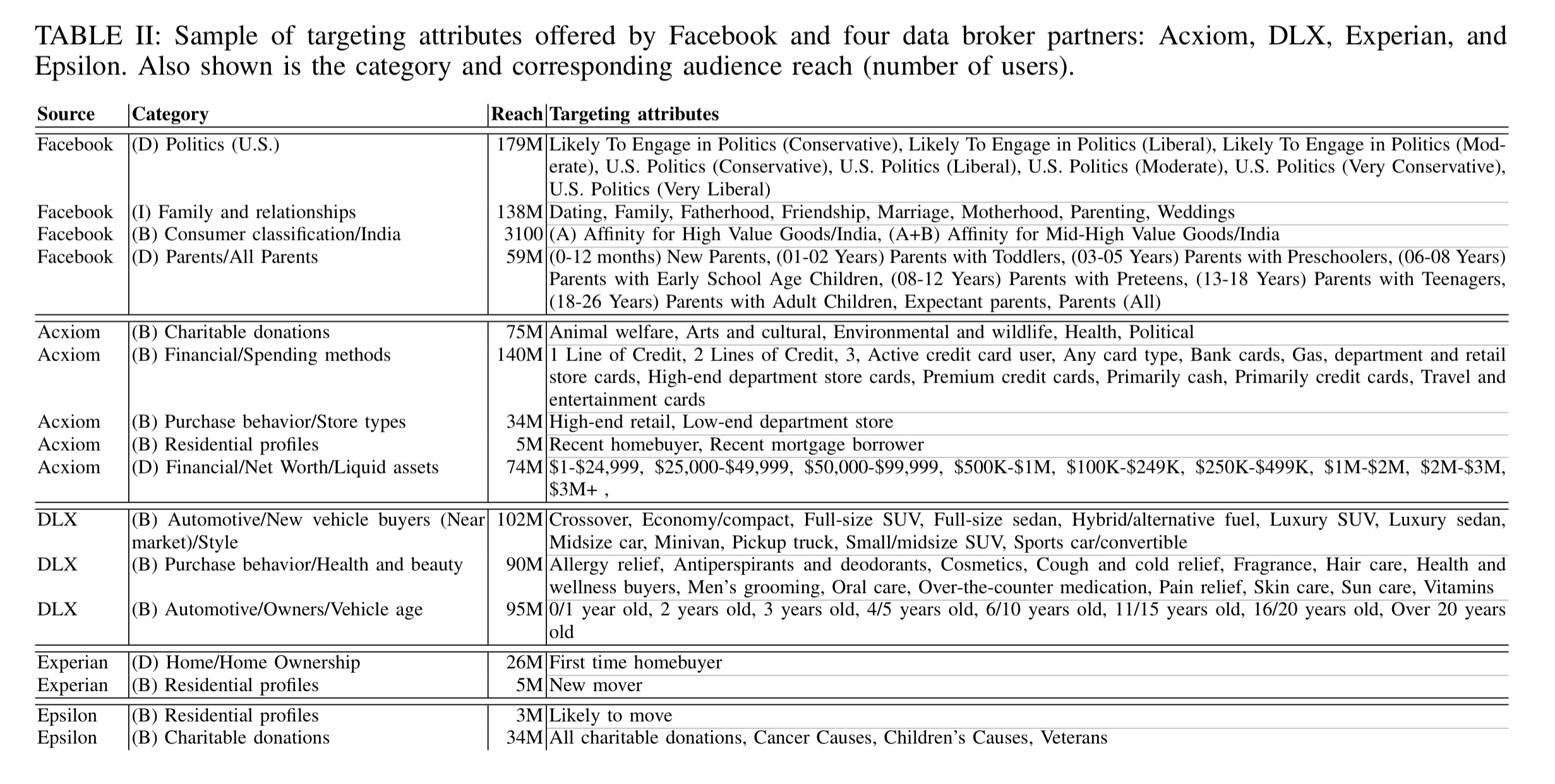
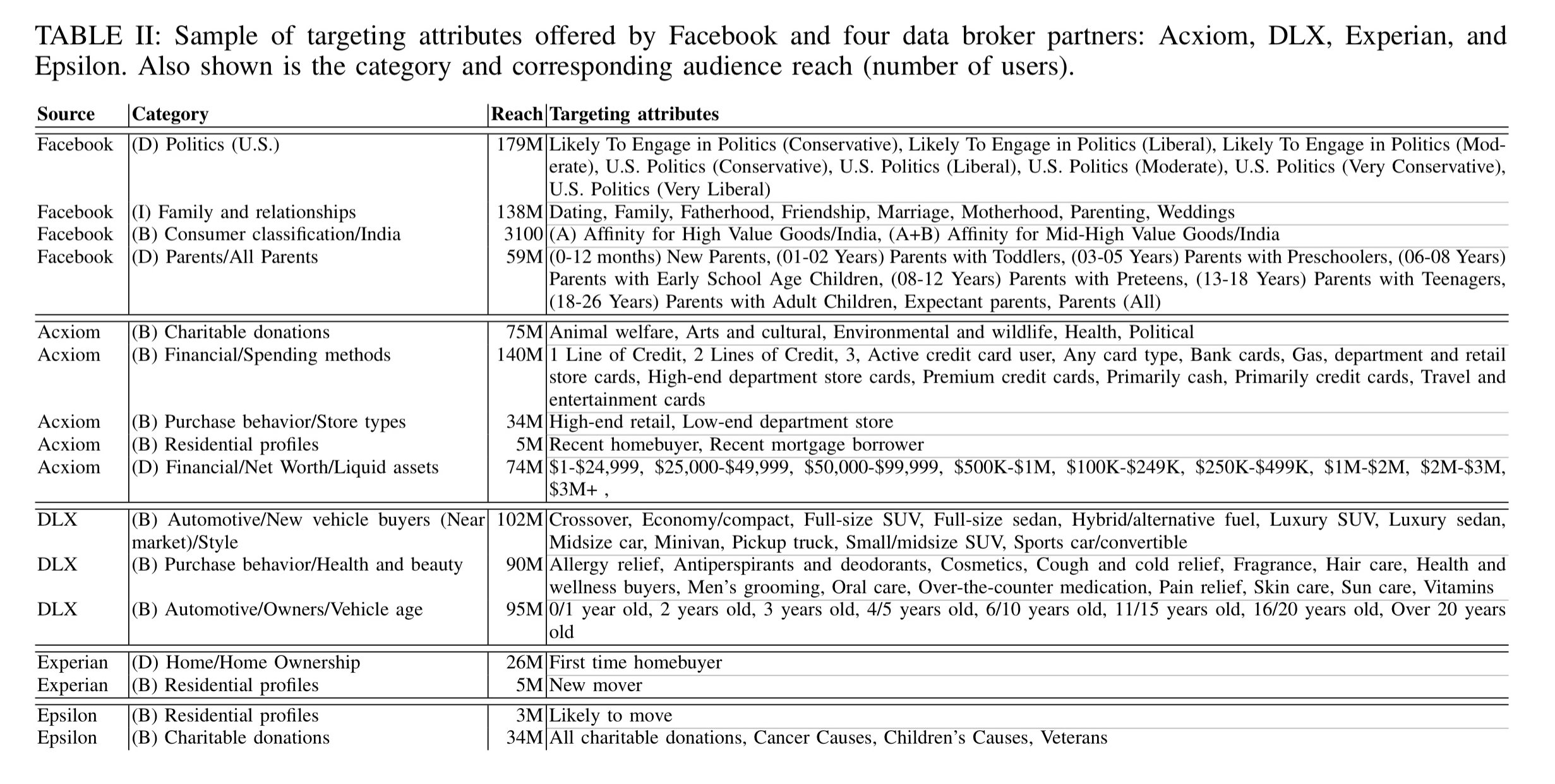
As of the time of this research, Facebook were offering 1,420 unique targeting attributes across the 10 different countries studied (U.S., U.K., France, Germany, Australia, South Korea, Japan, Canada, and India). By careful construction of audiences, they also obtained the corresponding audience reach estimate (i.e., number of matching users) for each attribute.
In the U.S., Facebook currently works with four data brokers: Epsilon, DLX, Experian, and Acxiom. Almost all the data brokers have data about the majority of Facebook users.
(Enlarge)
Ad explanations
A Facebook ad explanation has two parts. The first part starts with “One reason you’re seeing this ad …” or “You’re seeing this ad because … “ and the second part starts with “There may be other reasons you’re seeing this ad …”.
The first part of the ad explanations varies greatly across all of the ad explanations we observed… we can group (the first part of) explanation based on their underlying pattern and attribute type. Table II shows the different explanation types we identified together with typical examples for each type; overall we observed 10 different structures for the first part of the explanations.

(Enlarge)
Comparing the explanations to the targeting of the ads placed by the researchers reveals the following:
- Ad explanations are personalised to the Facebook user (two different users seeing the same ad may see different explanations)
- Ad explanations are incomplete – only one of the targeting attributes was ever shown in an explanation, even when users had all of the targeting attributes used.
- The ordering of attributes chosen by the advertiser does not affect the explanations
- When choosing which attribute to use in the explanation, the most common one always appears to be used.
- Moreover, when targeting attributes belong to different categories, then the selection of the chosen attribute for the explanation follows the following order: Demographic, then Interest, then PII-based, and finally Behaviour based. I.e., you’ll only see a behaviour-based attribute in an explanation if there are no demographic, interest, or PII-based attributes in the targeting list.
… our results suggest that whenever the advertiser uses one demographic-based attribute in addition to other attributes in its targeting, the demographic-based attribute will be the one in the explanation. If this is in fact the case, this choice is potentially impactful to users as previous research shows that users often consider behavior attributes more sensitive than the demographic ones.
- In the second part of explanations, attributes are included that were potentially never specified in the targeting, e.g., location-based attributes.
- When advertisers use data-broker provided targeting attributes, the actual targeted attributed is not provided, instead the user is told they were part of an audience based on data provided by a specific data broker.
- When advertisers use custom audiences, the explanations are generic phrases such as “you’re on their customer list.”
Unfortunately, Facebook does not reveal to the user which PII the advertiser provided (e.g., their email address, phone number, etc.). Yet again, we find that the explanations provided by Facebook are incomplete; this issue is especially acute when the advertisers are targeting users directly with their PII.
Data explanations
Facebook shows you the advertising attributes it has inferred about you on your Ad Preferences Page.
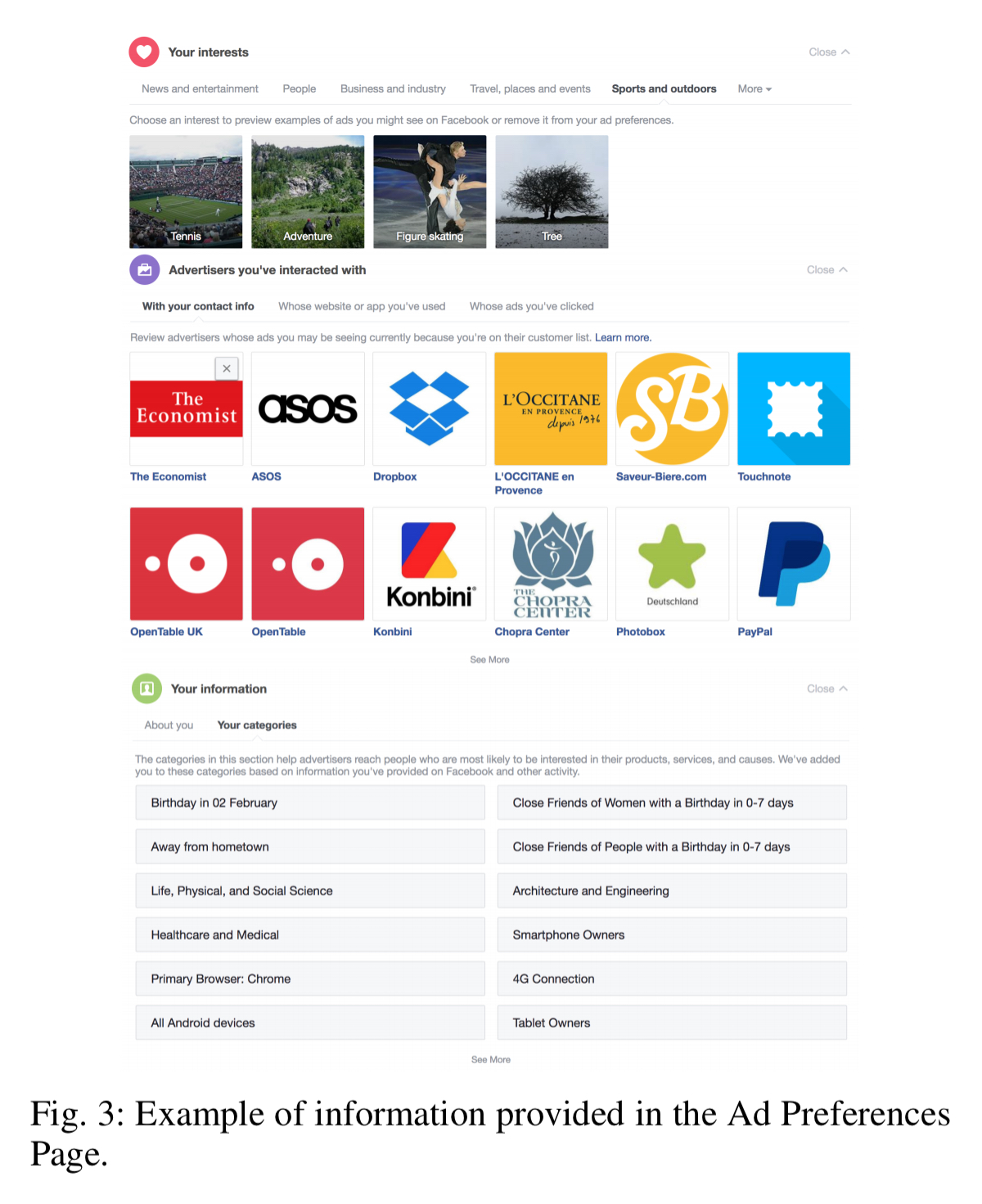
The team crawled the information on the Ad Preferences Page on a daily basis for each of 35 monitoring users, for a five month period.
We find that the number of reported attributes varies widely by user, ranging from 4 to 893 attributes, with an average of 247 and a median of 153. Across all users, we find that most reported attributes were interest-based (93%), followed by behavior-based (5%) and demographic-based (2%).
The inferred attributes do change over time – an average over 4.3% of a user’s attributes change per day.
There are five distinct patterns of explanations for inferred data attributes:

While the vast majority of interest explanations are due to liked pages and clicks (for example), Facebook does not specify which page or ad led to the interest attribute. No data broker attributes appear in the Ad Preferences Page (or any other place).
According to a statement by a Facebook representative, the absence of data broker attributes from the Ad Preferences Page is a deliberate choice, motivated by the fact that the data was not collected by Facebook.
With the forthcoming GDPR legislation, my interpretation is that you should be able to obtain this information on request. See for example the ICO explanations on the right to be informed and the right of access.
AdAnalyst
Facebook’s explanations only provide a partial view of its advertising mechanisms. To move towards greater transparency we built a tool, AdAnalyst, that works on top of Facebook and provides explanations with some of the missing properties. AdAnalyst keeps track of historical data about ads and explanations to provide users with a temporal view; and it provides a wider perspective by aggregating data across users. The tool can be downloaded and installed from http://adanalyst.mpi-sws.org. We hope that AdAnalyst will help increase the transparency of Facebook advertising and that it will allow users to detect malicious and deceptive advertising.

{kind=link}
{kind=link}
2 thoughts on “Investigating ad transparency mechanisms in social media: a case study of Facebook’s explanations”
Comments are closed.