Deep code search Gu et al., ICSE’18
The problem with searching for code is that the query, e.g. “read an object from xml,” doesn’t look very much like the source code snippets that are the intended results, e.g.:
 *
*
That’s why we have Stack Overflow! Stack Overflow can help with ‘how to’ style queries, but it can’t help with searches inside codebases you care about. For example, “where in this codebase are events queued on a thread?”
…an effective code search engine should be able to understand the semantic meanings of natural language queries and source code in order to improve the accuracy of code search.
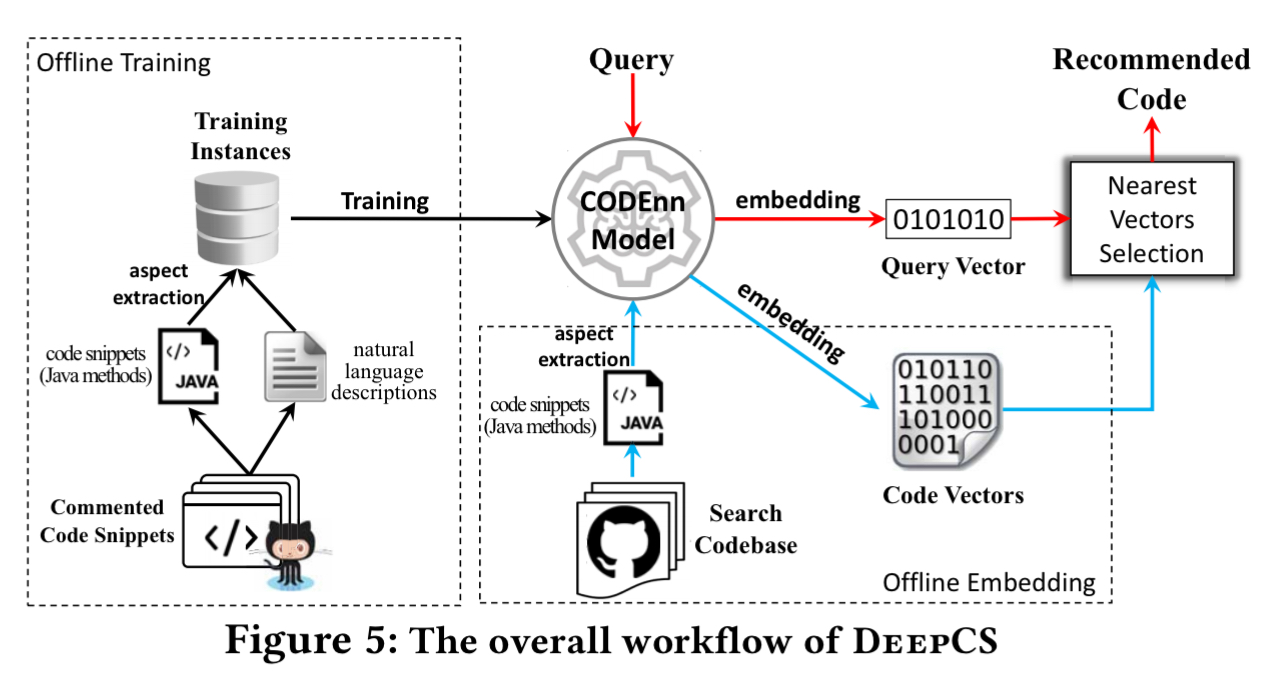
DeepCS is just such a search engine for code, based on the CODEnn (Code-Description Embedding Neural Network) network model. During training, it takes code snippets (methods) and corresponding natural language descriptions (from the method comments) and learns a joint-embedding. I.e., it learns embeddings such that a method description and its corresponding code snippet are both mapped to a similar point in the same shared embedding space. Then given a natural language query, it can embed the query in vector space and look for nearby code snippets. Compared to Lucene powered code search tools, and the recently proposed state-of-the-art CodeHow search tool, CODEnn gives excellent results.
Embeddings
One of the most popular posts over time on this blog has been ‘The amazing power of word vectors,’ which describes the process of turning words into vectors. To turn a sequence of words into a vector, one common approach is to use an RNN (e.g., LSTM). For example, given a sentence such as ‘parse xml file,’ the RNN reads the first word, ‘parse,’ maps it into a vector 




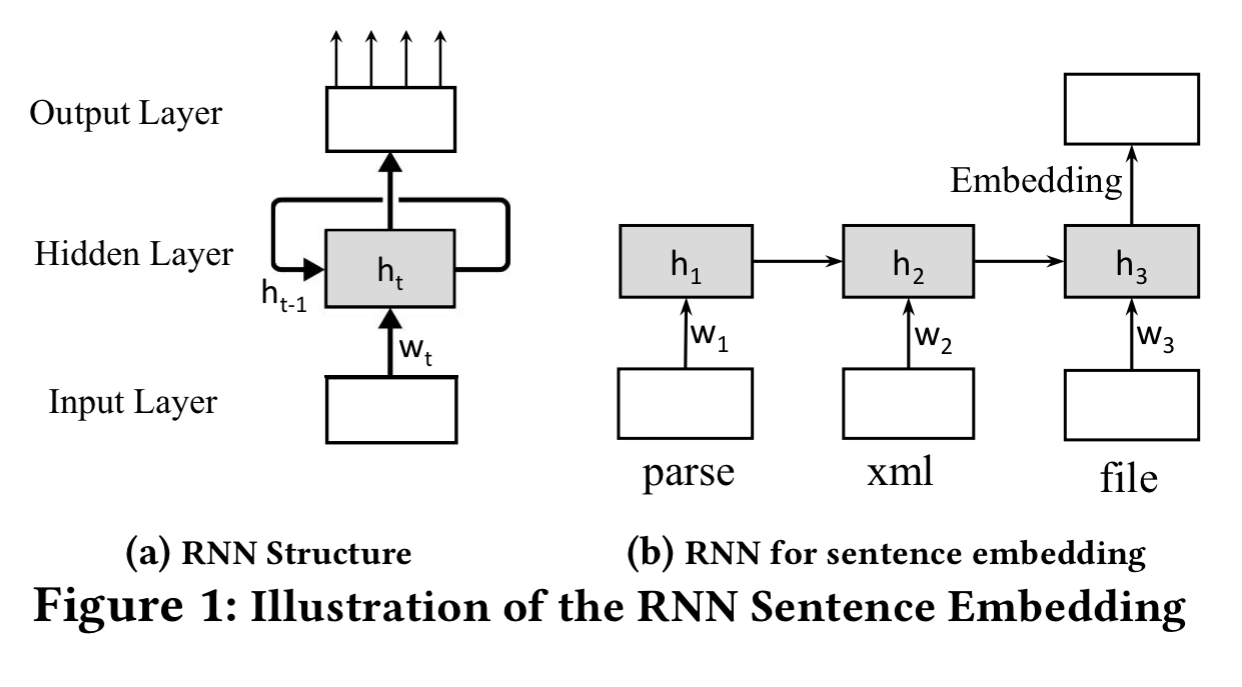
We don’t want just any old embedding though. We want to learn embeddings such that code snippets (think of them like ‘code sentences’ for now, we’ll get to the details shortly) and their corresponding descriptions have nearby embeddings.
Joint Embedding, also known as multi-model embedding, is a technique to jointly embed/correlate heterogeneous data into a unified vector space so that semantically similar concepts across the two modalities occupy nearby regions of the space.
When we’re training, we use a similarity measure (e.g. cosine) in the loss function to encourage the joint mapping.
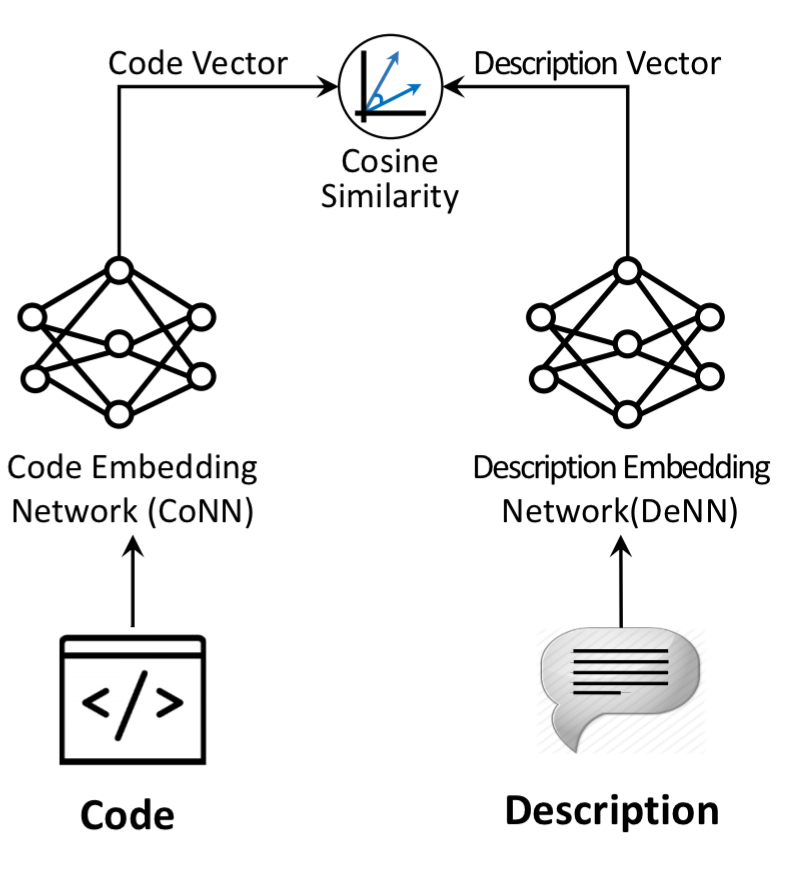
CODEnn high level architecture
CODEnn has three main components: a code embedding network to embed source code snippets in vectors; a description embedding network to embed natural language descriptions into vectors; and a similarity module (cosine) to measure the degree of similarity between code and descriptions. At a high level it looks like this:
If we zoom in one level, we can start to see the details of the network constructions:
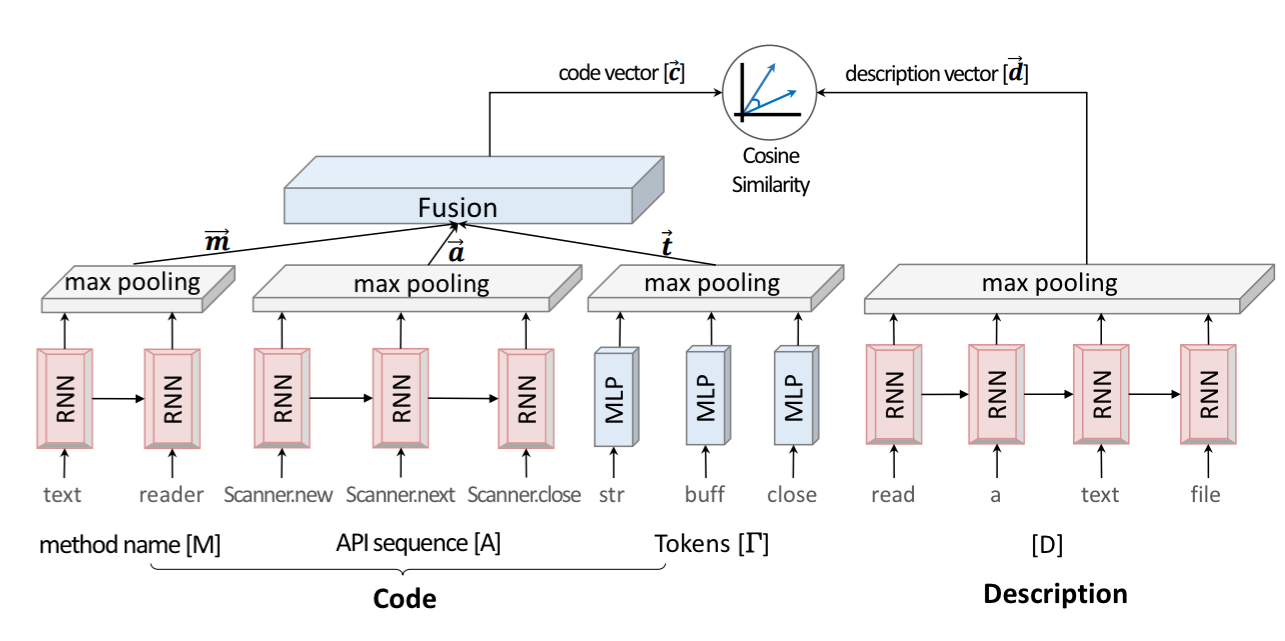
The code embedding network
A code snippet (a method) is turned into a tuple (M,A,T) where M is a sequence of camelCase split tokens in the method name, A is an API sequence (the method invocations made by the method body), and T is the set of tokens in the snippet.
The method name and API invocation sequences are both embedded (separately) into vectors using RNNs with maxpooling. The tokens have no strict order, so they are embedded using a conventional multilayer perceptron. The three resulting vectors are then fused into one vector through a fully connected layer.
The description embedding network
The description embedding network uses an RNN with maxpooling to encode the natural language description from the (first sentence of) the method comment.
Training
During training, training instances are given as triples (C, D+, D-), where C is a code snipped, D+ is the correct (actual) description of C, and D- is an incorrect description, chosen randomly from the pool of all descriptions. The loss function seeks to maximise the cosine similarity between C and D+, and make the distance between C and D- as large as possible.
The training corpus is based on open-source Java projects on GitHub, resulting in a body of just over 18M commented Java methods.
For each Java method, we use the method declaration as the code element and the first sentence of its documentation comment as its natural language description. According to the Javadoc guidance, the first sentence is usually a summary of a method.
The method bodies are parsed using the Eclipse JDT compiler. (Note, some of the tools from Source{d} may also be useful here).
All the RNNs are embodied as LSTMs with 200 hidden units in each direction, and word embeddings have 100 dimensions.
Indexing and querying
To index a codebase, DeepCS embeds all code snippets in the codebase into vectors using offline processing. Then during online searching DeepCS embeds the natural language user query, and estimates the cosine similarities between the query embedding and pre-computed code snippet embeddings. The top K closest code snippets are returned as the query results.
Evaluation
Evaluation is done using a search codebase constructed from ~10 thousand Java projects on GitHub (different to the training set), with at least 20 stars each. All code is indexed (including methods without any comments), resulting in just over 16M indexed methods.
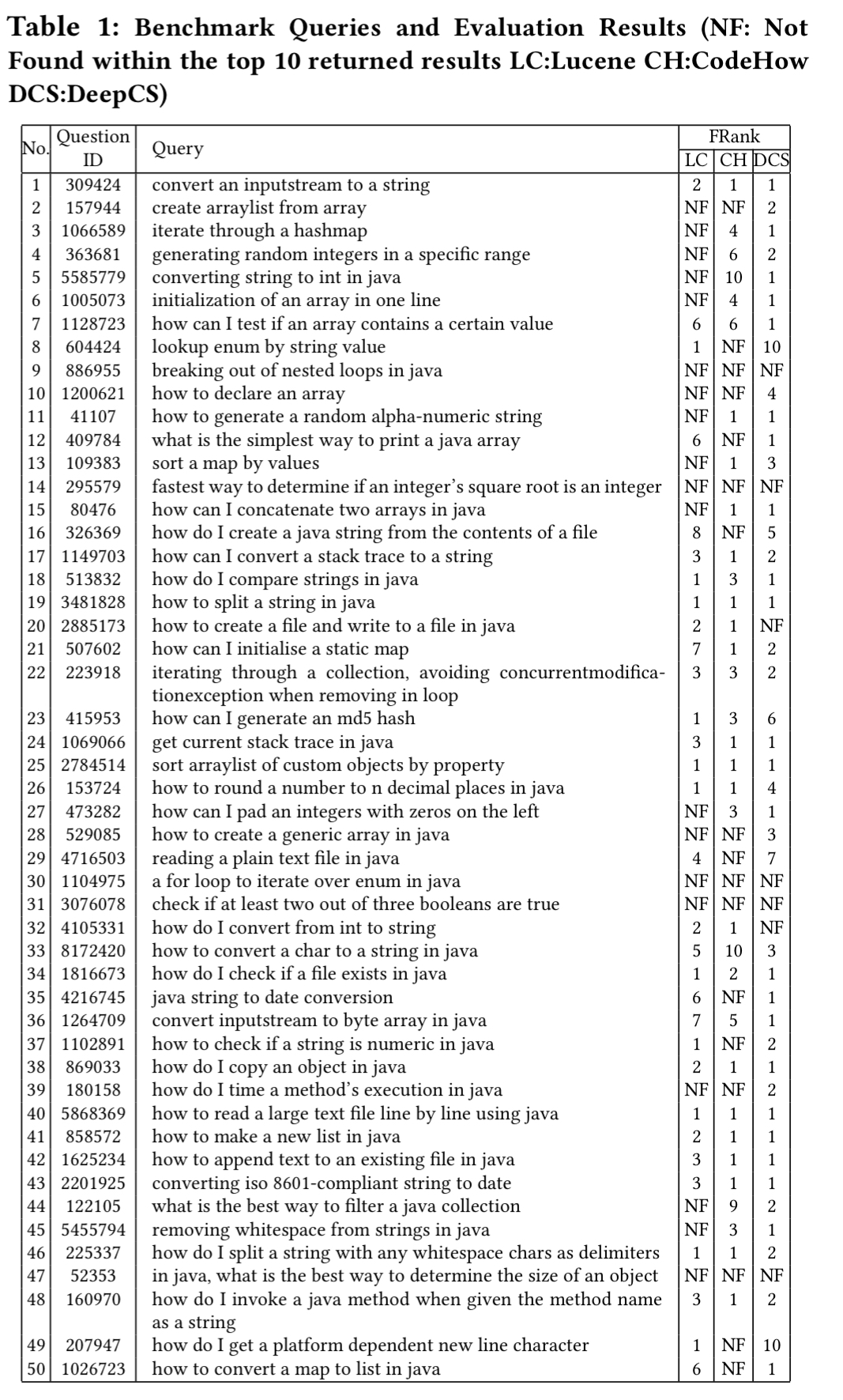
We build a benchmark of queries from the top 50 voted Java programming questions in Stack Overflow. To achieve so, we browse the list of Java-tagged questions in Stack Overflow and sort them according to the votes that each one receives.
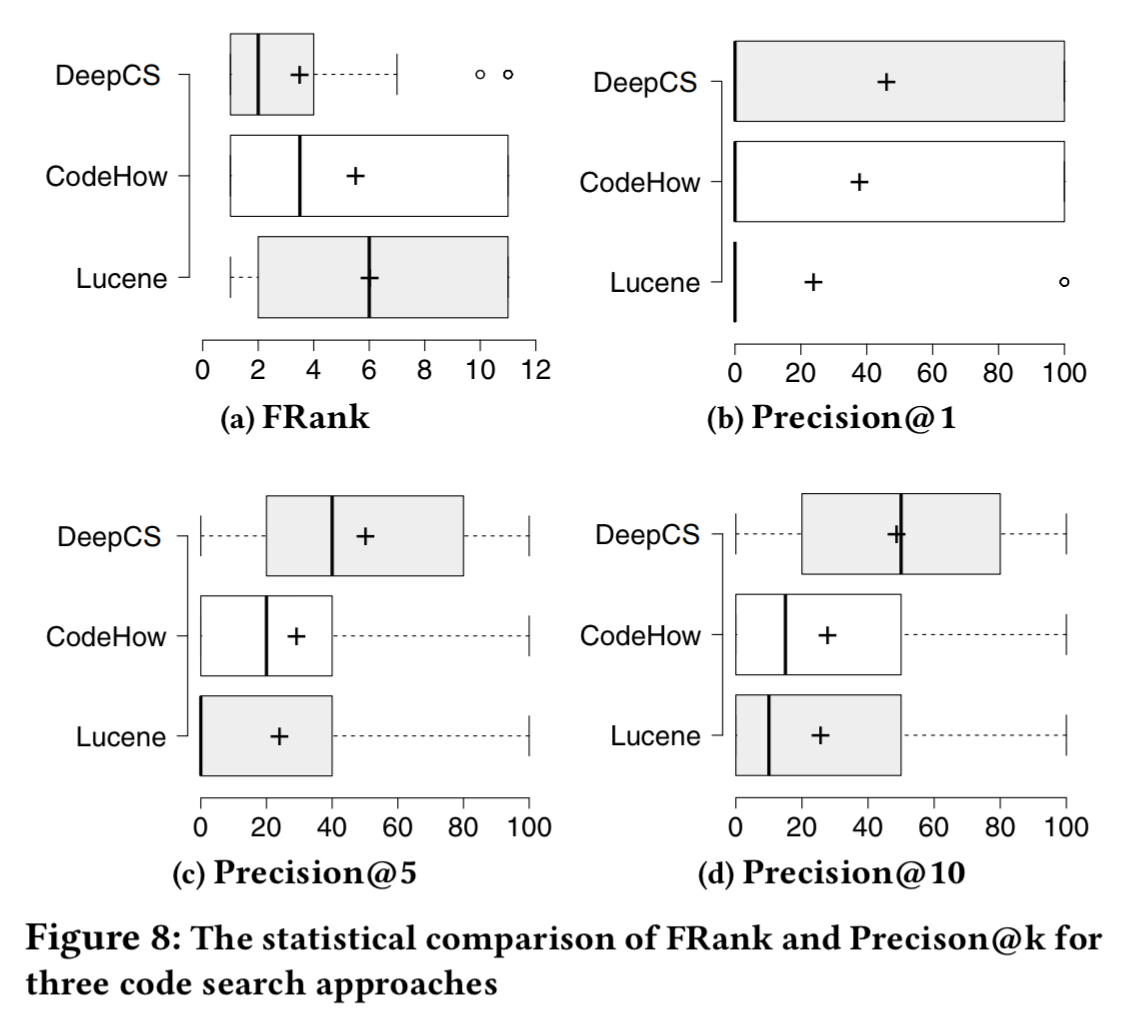
To qualify, the questions must be about a concrete Java programming task and include a code snippet in the accepted answer. The 50 such resulting questions are shown in the following table. In the right-hand column we can see the FRank (rank of the first hit result in the result list) for DeepCS, CodeHow, and a conventional Lucene-based search tool.
Here are some representative query results.
- “queue an event to be run on the thread” vs “run an event on a thread queue” (both have similar words in the query, but are quite different).

- “get the content of an input stream as a string using a specified character encoding”

- “read an object from an xml file” (note that the words xml, object, and read don’t appear in the result, but DeepCS still finds it)

- “play a song” (another example of associative search, where DeepCS can recommend results with semantically related words such as audio).

DeepCS isn’t perfect of course, and sometimes ranks partially relevant results higher than exact matching ones.
This is because DeepCS ranks results by just considering their semantic vectors. In future work, more code features (such as programming context) could be considered in our model to further adjust the results.

Highly useful
Ks choudhury
Thanks for sharing
The best code search engine I know is ‘ordinary’ Google, which the authors don’t compare against.
The authors appear to have cheery-picked their benchmark, and why are they quoting obscure performance metrics? What is wrong with precision and recall?
Google’s code search, when it was available (source was released), did a fantastic job of regular expression matching for code: described here: https://swtch.com/~rsc/regexp/regexp4.html
THE Thing!!
Hello there! We wrote a very similar article at Github regarding code search: https://towardsdatascience.com/semantic-code-search-3cd6d244a39c
It would be great to meet you some time! Please get in touch (links on how to do so are in that article)
Wow! That’s a really terrific post, thanks for sharing. Love the accompanying notebook idea.
Reblogged this on josephdung.
I work with code search, and I would be really interested to see how this approach performs compared to Google. Google is really smart! Although, according to my experience, comparing with Google is challenging given several uncontrolled variables, but this curiosity will dominate every reader’s mind of this article :)