Medea: scheduling of long running applications in shared production clusters Garefalakis et al., EuroSys’18
(If you don’t have ACM Digital Library access, the paper can be accessed either by following the link above directly from The Morning Paper blog site).
We’re sticking with schedulers today, and a really interesting system called Medea which is designed to support the common real world use case of mixed long running applications (LRAs) and shorter duration tasks within the same cluster. The work is grounded in production cluster workloads at Microsoft and is now part of the Apache Hadoop 3.1 release. In the evaluation, when compared to the Kubernetes’ scheduling algorithm Medea reduces median runtimes by up to 32%, and by 2.1x compared to the previous generation YARN scheduler.
…a substantial portion of production clusters today is dedicated to LRAs…. placing LRAs, along with batch jobs, in shared clusters is appealing to reduce cluster operational costs, avoid unnecessary data movement, and enable pipelines involving both classes of applications. Despite these observations, support for LRAs in existing schedulers is rudimentary.
The challenges of scheduling long-running applications
Example uses of long running application containers include streaming systems, interactive data-intensive applications (maintaining significant state in-memory), latency sensitive applications, and machine learning frameworks. Such applications often have placement constraints or preferences. For example, the familiar affinity (put these things together) and anti-affinity (make sure these things are separated) rules.
A 275 node Storm cluster deployed using YARN demonstrates the benefits of affinity rules, both within and between applications. Putting all Storm containers on the same node reduces average end-to-end latency by 31%. If we also co-locate memcached, we get a further 5x reduction in average latency.
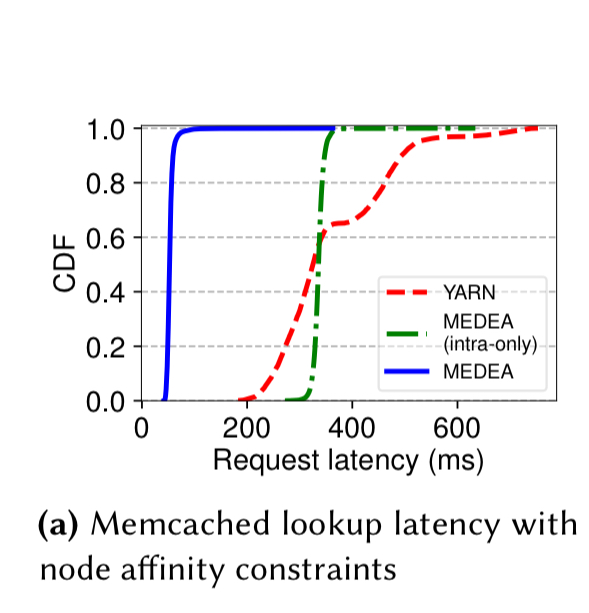
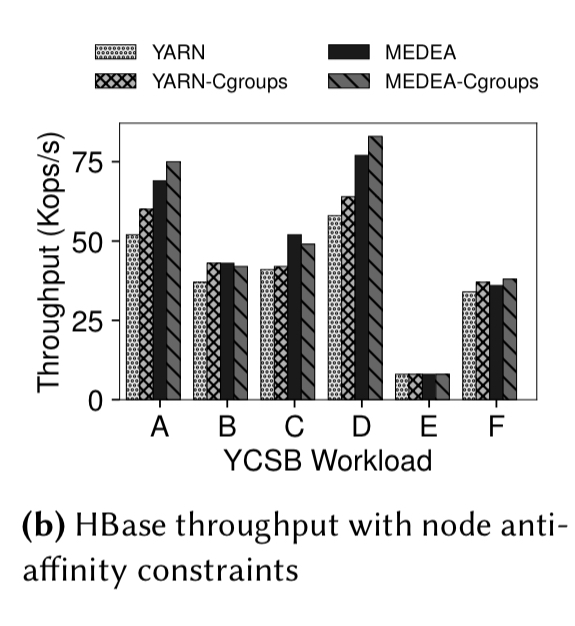
An 40 instance HBase deployment shows the advantages of anti-affinity rules. Ensuring region servers don’t end up on the same node, competing for resources, improves overall throughput and reduces tail latency by up to 3.9x.
Affinity and anti-affinity rules have been around for as long as I can remember. What’s interesting here is that, as the authors point out, you can actually view them as just two extremes of a collocation spectrum. And as we saw yesterday with Optimus, there can be happy places in between those two extremes as well. The following charts show what happens with varying numbers of HBase region servers per node (workers per node) in an HBase and TensorFlow application respectively.
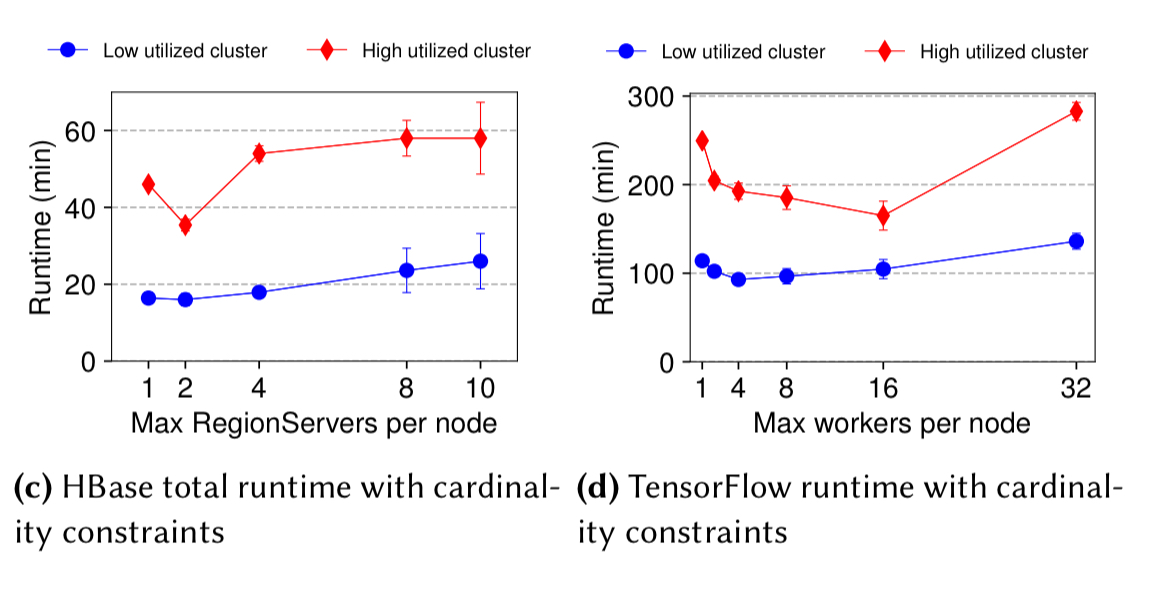
Based on these results, we make the crucial observation that affinity and anti-affinity constrains, albeit beneficial, are not sufficient, and tighter placement control using cardinality constraints is required.
Note that the optimum cardinality can also depend on the current cluster load.
Beyond performance, another common use of anti-affinity constraints is to ensure instances are deployed in separate fault and upgrade zones. We’d like to able to express this desire without needing to know the precise details of the domains within a cluster.
Beyond the needs of the applications themselves, we also have overall cluster objectives – for example, minimising the number of application constraint violations across the cluster, minimising resource fragmentation, balance node lode, and minimising the number of machines required. Different operators may want to trade-off among these concerns differently.
This all boils down to four high level requirements for scheduling long-running applications:
- R1: Expressive placement constraints – support both intra- and inter- application (anti-) affinity and cardinality to express placement dependencies between containers.
- R2: High level constraints – constraints must be agnostic of cluster organisation, and capable of referring to both current and future LRA containers.
- R3: Global objectives – we must meet global optimisation objectives imposed by the cluster operator
- R4: Scheduling latency – supporting LRAs, which can tolerate higher scheduling latencies, must not affect the scheduling latency for containers of task-based applications.
The following table summarise how these requirements are supported across a variety of schedulers today.

(Enlarge)
Introducing Medea
Medea uses two schedulers for placing containers. Following “if it ain’t broke, don’t fix it,” existing production hardened task schedulers can be used to schedule short running tasks. Medea then introduces an additional scheduler that handles long-running applications.
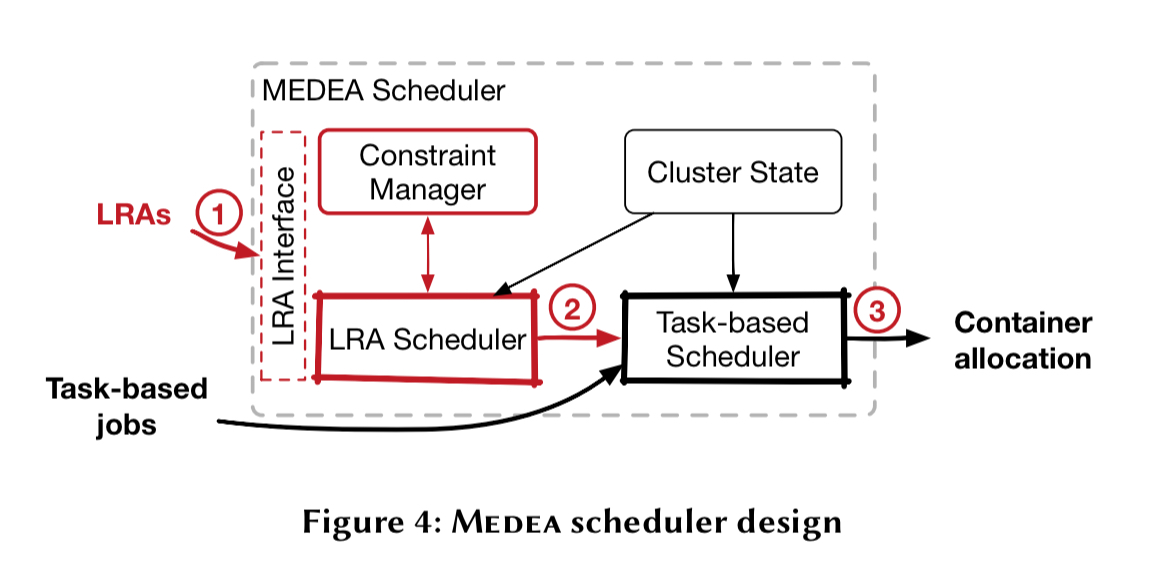
Task-based jobs go straight to the task scheduler. For LRA jobs the LRA scheduler makes placement decisions, which it then passes to the task-based scheduler which performs the actual resource allocation.
This approach avoids the challenge of conflicting placements, faced by existing multi-level and distributed schedulers: in these designs, different schedulers, operating on the same cluster state, may arrive at conflicting decisions, whereas in Medea the actual allocations are performed by a single scheduler.
Now it’s possible that the cluster state has changed while the LRA scheduler has been doing its work (due to the submission and placement of task-based jobs in the meantime). If this results in a conflict, the pragmatic solution is to resubmit the LRA.
To meet requirements R1 through R3 we need to be able to specify constraints. Medea allows tags (labels) to be attached to containers and nodes. It also supports the definition of node groups, logical possibly overlapping sets of nodes. The ‘node’ and ‘rack’ node group types are predefined, other examples include fault and upgrade domains. The purpose of node groups is to allow constraints to be expressed independently of the cluster’s underlying organisation.
Placement constraints are tuples of the form (subject tags, cardinality, node group). The subject tags identify the containers subject to the constraint. Each of these containers should be placed on a node belonging to the specified node group The cardinality specification is of the form (tag constraint, min, max). It is interpreted as follows: every node on which one of the subject containers is placed must have, in aggregate, between min and max occurrences of the tags in the tag constraint set across all of its containers.
Note that we can express a wide range of constraints this way. For example, with min=1 and max=∞ we can express affinity. (storm, (hb AND mem, 1, ∞), node) says place each container with tag storm in the same node as at least one container with tags hb and mem. With min=0, max=0 we can express anti-affinity constraints. For example, (storm, (hb, 0, 0), upgrade_domain) requests each storm container be placed in a different upgrade domain to all hb containers. Other values of min and max let us specify the inbetween points. For example, (storm, (spark, 0, 5), rack) says put each storm container in a rack with no more than five spark containers deployed.
When determining the LRA container placement, our scheduling algorithm attempts to (i) place all containers of an LRA; (ii) satisfy the placement constraints of the newly submitted LRAs, of the previously deployed ones, and of the cluster operator, (iii) respect the resource capacities of all nodes, and (iv) optimize for global cluster objectives.
All of these constraints are bundle up and passed to an integer linear programming (ILP) solver (CPLEX in the implementation). Of note here is that we’re solving the puzzle for new containers simultaneously, whereas e.g. Borg considers just one container request at at time.
How well does it work?
The evaluation combines a 400 node pre-production cluster grouped into 10 racks, supplemented by simulation. Medea is compared against a Java implementation of the Kubernetes scheduling algorithm (J-KUBE), the Kubernetes algorithm extended to support cardinality constraints (J-KUBE++), and the YARN scheduler.
Here you can see the application runtimes resulting from the scheduler placements. Medea outperforms J-KUBE across all percentiles by up to 32%, and outperforms J-KUBE++ by up to 28%. YARN is the loser here, with Medea beating it by 2x or more.
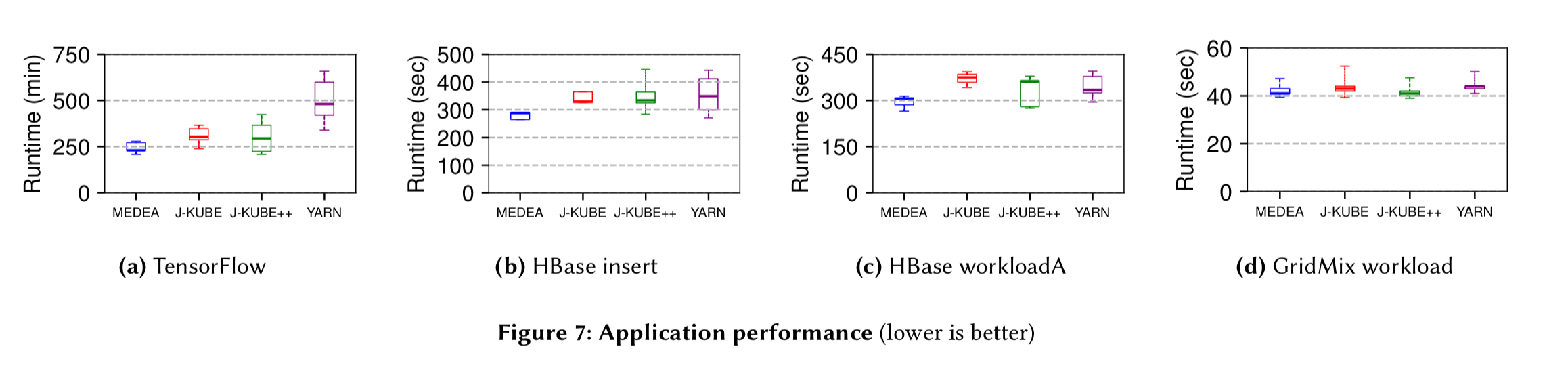
(Enlarge)
(Chart (d) above shows that Medea is not penalising task-based workloads).
Using unavailability data from one of the Microsoft production clusters, we can also see that the Medea placements lead to higher availability under failure:
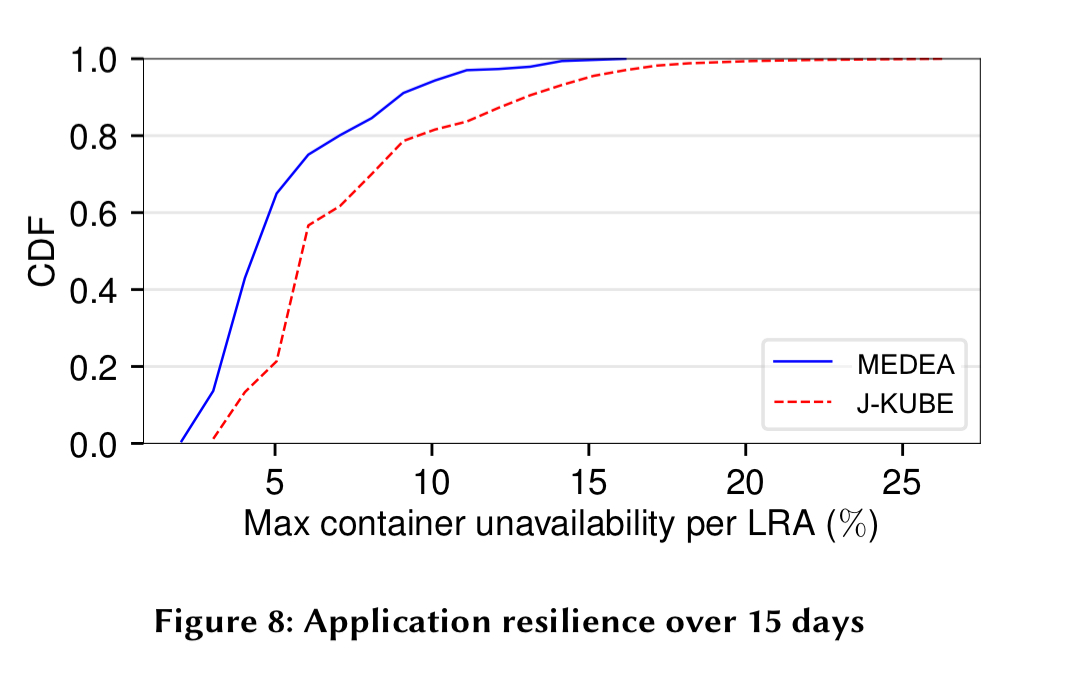
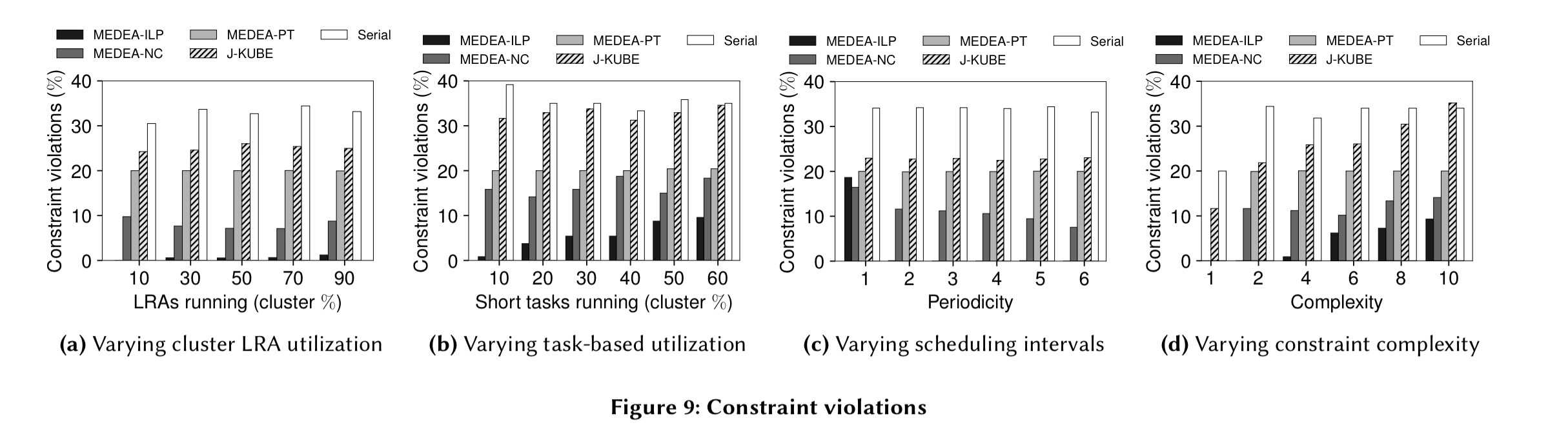
Given a set of global objectives from a cluster operator, Medea does significantly better than Kubernetes at minimising violations (focus on the Medea-ILP line in the charts below):
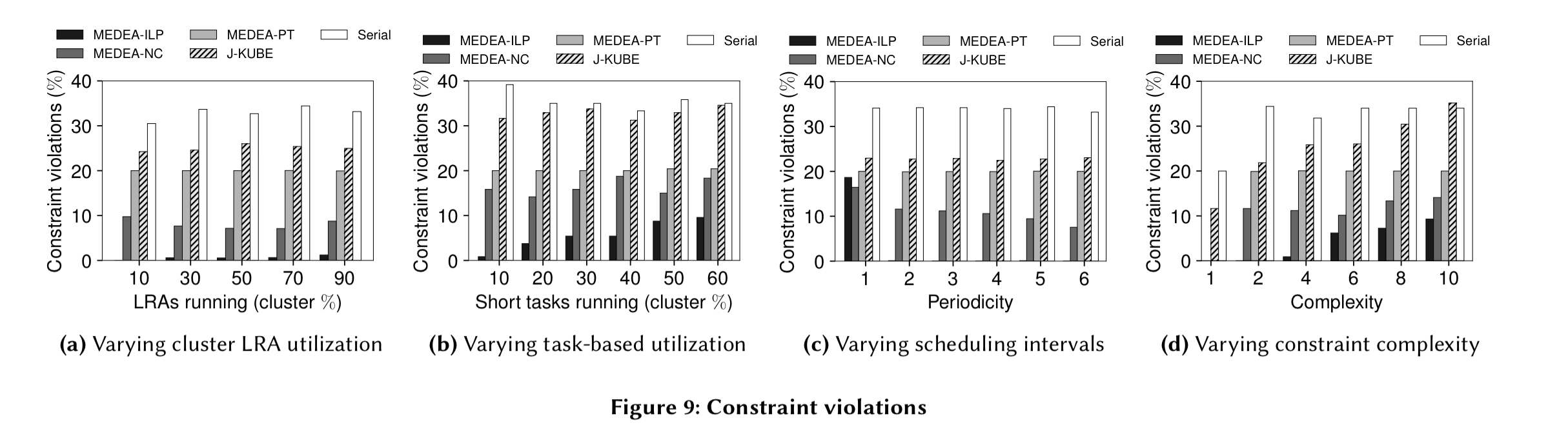
(Enlarge)
It also produces better load balancing across the cluster:
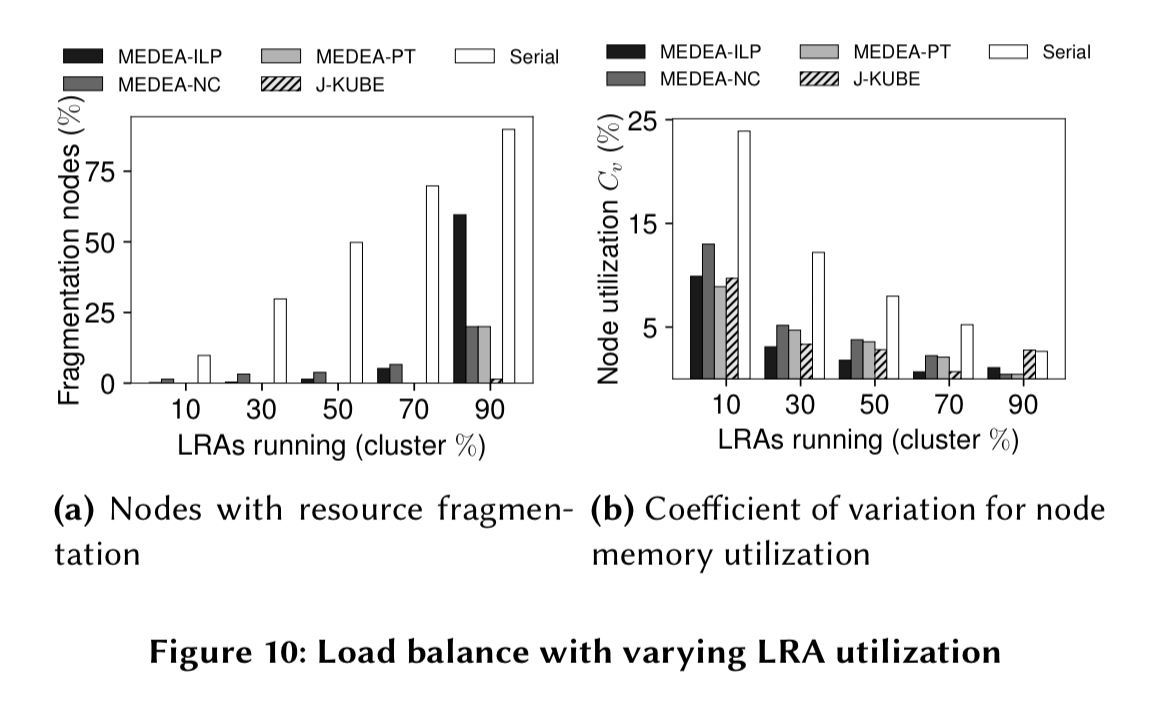
The last word
Medea is the first system to fully support complex high-level constraints both within and across LRAs, which are crucial for the performance and resilience of LRAs. It follows a two-scheduler design, using an optimization-based algorithm for high-quality placement of LRAs with constraints, and a traditional scheduler for placing task-based jobs with low scheduling latency. We evaluated our YARN-based implementation of Medea on a 400-node cluster and showed that it achieves significant benefits over existing schedulers for applications such as TensorFlow and HBase.

{kind=link}
{kind=link}
{kind=link}