Pixie: a system for recommending 3+ billion items to 200+ million users in real-time Eksombatchai et al., WWW’18
(If you don’t have ACM Digital Library access, the paper can be accessed either by following the link above directly from The Morning Paper blog site, or from the WWW 2018 proceedings page).
Pinterest is a visual catalog with several billion pins, which are visual bookmarks containing a description, a link, and an image or a video. A major problem faced at Pinterest is to provide personalized, engaging, and timely recommendations from a pool of 3+ billion items to 200+ million monthly active users.
Stating the obvious, 3 billion or so items is a lot to draw recommendations from. This paper describes how Pinterest do it. One of the requirements is that recommendations need to be calculated in real-time on-demand. I’m used to thinking about the shift from batch to real-time in terms of improved business responsiveness, more up-to-date information, continuous processing, and so on. Pinterest give another really good reason which is obvious with hindsight, but hadn’t struck me before: when you compute recommendations using a batch process, you have to calculate the recommendations for every user every batch cycle (e.g. once a day). This is necessary because you don’t know which ones will actually be required in the current window. When only a small subset of the overall user base will actually need recommendations though, you’re wasting a lot of resources computing all the other values which will never be used. When you can make recommendations in real-time though, you only have to compute the recommendations you’re actually going to use.
Pinterest’s scalable real-time recommendation system is called Pixie, and it currently drives more than 80% of all user engagement.
Pins, boards, and recommendations
In the world of Pinterest, users view pins and curate them into collections called boards. There are hundreds of millions of users undertaking this manual categorisation of pins into boards.
Thus, we can think of Pinterest as a giant human curated bipartite graph of 7 billion pins and boards, and over 100 billion edges.
Through the paper you’ll see the following notation: P denotes a set of pins, and B a set of boards. E(p) represents board nodes connected to pin p, and E(b) represents pins connected to board b.
The central recommendation problem is this: given a query set Q comprising a set of pins and corresponding weights, return a set of pins (or boards) that the user may be interested in.
The query set Q is user-specific and is generated dynamically after every action of the user— most recently interacted pins have high weights while pins from a long time ago have low weights.
Among other things, Pixie recommendations are used to show a grid of pins in a user’s ‘homefeed’ (home page) that the user might find relevant to save in their board. Whenever a user clicks on a pin, Pixie is used to show related pins. When a user views one of their own boards, Pixie is used to suggest other pins to be saved to the board. Pixie is also used to recommend “Picked for you” boards.
These are only a few examples of applications that use Pixie — others include the email and personalized articles. Over half of all the pins that users save each day on Pinterest come from systems backed by Pixie.
Pixie random walks
Pixie generates recommendations using random walks. We start with a simplified random walk algorithm, and then transform it step by step into Pixie.
Consider a single starting pin q. We can simulate a number of random walks starting from q, and record the visit count for each candidate pin the algorithm visits. The higher the visit count for a pin, the more related it is to the original seed pin q. The number of steps in each random walk is controlled by a parameter 

To arrive at the Pixie Random Walk algorithm we now need to apply four enhancements to the basic procedure above:
- Biasing the walk towards user-specific pins
- Using multiple weighted query pins
- Boosting pins relating to multiple query pins
- Early stopping to minimise the number of steps (time) while maintaining result quality
User bias
We want user-specific recommendations, even when starting from the same query pins. An example is biasing towards pins and boards in the same language as the user’s settings.
We solve the problem of biasing the random walk by changing the random edge selection to be biased based on user features… In practice, this modification turns out to be very important as it improves personalization, quality, and topicality of recommendations, which then leads to higher engagement.
The set of user features U are passed as an input to the process along with the query pins.
Multiple weighted query pins
Pixie makes recommendations based on multiple input query pins, not just a single pin. Each pin in the query set is assigned a different weight based on the time and type of interactions the user has had with the pin. The random walk algorithm is run for each query pin in the set, with each run capturing its own set of visit counts.
An important insight here is that the number of steps required to obtain meaningful visit counts depends on the query pin’s degree. Recommending from a high-degree query pin that occurs in many boards requires many more steps than from a pin with a small degree. Hence, we scale the number of steps allocated to each query pin to be proportional to its degree.
For each pin a scaling factor 
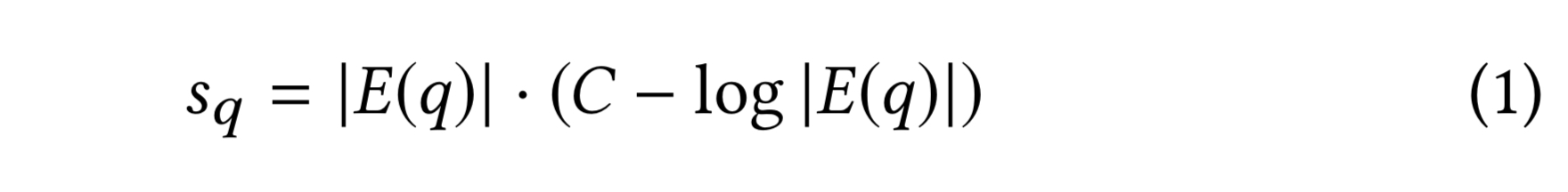
Using the scaling factor, the number of steps 

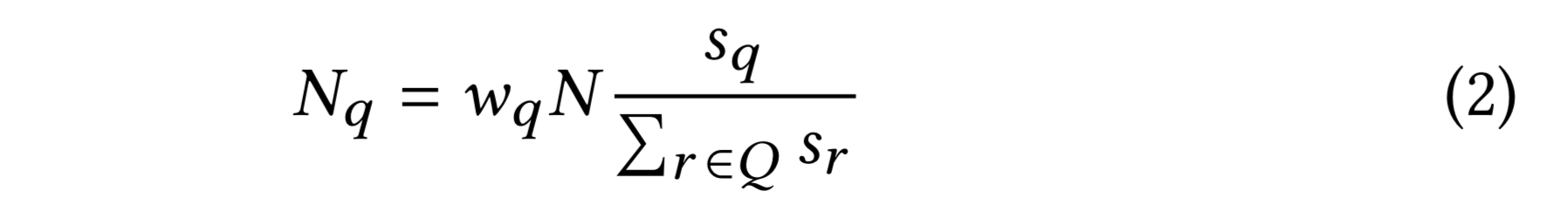
The visits counts generated from each query pin are them combined using the method described next.
Boosting
Candidates with high visit counts from multiple query pins are considered more relevant to the query than candidates that may have an equally high visit count but where all of those visits come from a single query pin. Thus rather than simply aggregating visit counts across all seed pins, the following formula is used to combine them:
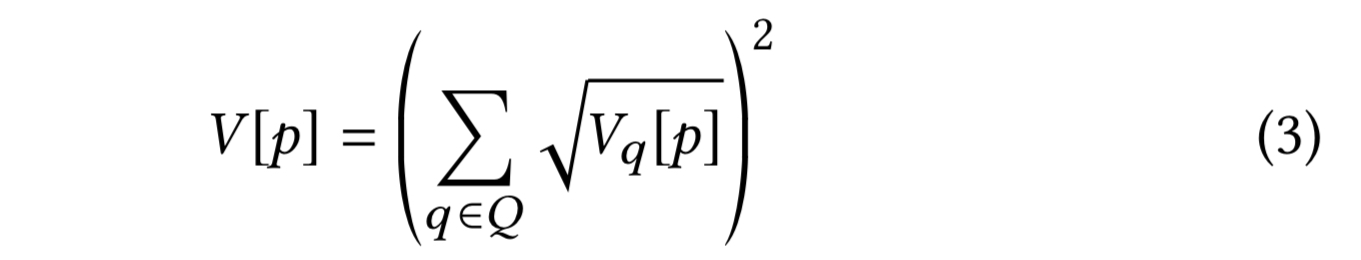
Consider a query with four initial query pins. If the visit counts for a given pin at the end of a a set of random walks are [16,0,0,0] then the combined visit score will be 16 still. But if the visit counts are [4,4,4,4] then the combined visit score will be (2+2+2+2)^2 = 64.
Early stopping
Since we’re making recommendations in real-time, and the user is waiting, faster response times are much better. Once a set of top candidate pins has become stable, we can terminate the random walking early. As an efficient approximation to this, Pixie stops when at least 

Putting it all together
Combining all the elements above, we end up with the following:

There’s still one more piece of the puzzle that is important to Pixie’s overall performance: pruning the graph that is used as input to the whole process.
The original Pinterest graph has 7 billion nodes and over 100 billion edges. However, not all boards on Pinterest are topically focused. Large diverse boards diffuse the walk in too many directions, which then leads to low recommendation performance. Similarly, many pins are mis-categorized into wrong boards. The graph pruning procedure cleans the graph and makes it more topically focused.
LDA topic models are run on each pin description in a board to obtain topic vectors. Boards with high entropy in topic vectors are removed from the graph, along with all their edges. Pin with very high degree are also pruned via selective edge removal, which discards edges connecting to boards where there is low cosine similarity between the topic vector of the pin and the board.
The pruned graph has approximately 1 billion boards, 2 billion pins, and 17 billion edges. In the evaluation, recommendations from the pruned graph are shown to be 58% more relevant to the user.
Implementation details
For each node edges are stored in an adjacency list, and the adjacency lists are concatenated into one contiguous edgeVec array. Visit counts are maintained in open addressing hash table with linear probing. The number of steps N provides an upper bound on the number of keys the hash table needs to support, and to avoid resizing an array of size N is conservatively allocated at the outset.
The pruned graph is generated by from a Hadoop pipeline followed by a graph compiler. The graph compiler runs on a single terabyte-scale RAM machine and outputs a pruned graph in binary format. Graph generation is run once per day.
Pixie is deployed on Amazon AWS r3.8xlarge machines with 244GB of RAM. The pruned Pinterest graph fits into about 120GB of main memory. Having the whole graph in memory on a single machine means that:
- The random walk does not have to cross machines, bringing huge performance benefits
- Queries can be answered in real-time and multiple walks can be executed on the graph in parallel
- Pixie can be scaled an parallelized by simply adding more machines to the cluster.
At 99%-ile latency Pixie takes 60ms to produce recommendations, and a single Pixie server can serve about 1,200 recommendation requests per second. The overall cluster servers around 100,000 requests per second.
Thanks to the high performance, scalability, and generic nature of the Pixie architecture and algorithms, we anticipate a bright future with new algorithms and graphs featuring novel node types and edge definitions for even more applications at Pinterest.

What I find most interesting about algorithms like this (and this includes algorithms like the one that Netflix uses for recommendations) is the evaluation phase. In this article you quote them as saying the recommendations after some pruning were “58% more relevant to the user.”
How on earth do they know? How can you measure the “correctness” of such algorithms? Netflix makes recommendations based on a small number of your own choices: but who is to say they are ‘right’? (If I review Mary Poppins and Harry Potter and the Philosopher’s Stone and Netflix recommends some Swedish Noir, are they wrong?)
I’d like to see some serious criticism of this end of this story.
Hi Steve, in this case they used A/B testing to see whether their was more user engagement (pin clicks) with Pixie vs the prior system:
“The ultimate test of the quality of Pixie recommendations is the lift in user engagement in a controlled A/B experiment where a random set of users experiences Pixie recommendations, while other users experience recommendations given by the old Hadoop-based production system that precomputes recommendations and is not real-time. Any difference in engage- ment between these two groups can be attributed the increased quality of Pixie recommendations.”