Stateless datacenter load-balancing with Beamer Olteanu et al., NSDI’18
We’ve spent the last couple of days looking at datacenter network infrastructure, but we didn’t touch on the topic of load balancing. For a single TCP connection, you want all of the packets to end up at the same destination. Logically, a load balancer (a.k.a. ‘mux’) needs to keep some state somewhere to remember the mapping.
Existing load balancer solutions can load balance TCP and UDP traffic at datacenter scale at different price points. However, they all keep per-flow state; after a load balancer decides which server should handle a connection, that decision is “remembered” locally and used to handle future packets of the same connection. Keeping per-flow state should ensure that ongoing connections do not break when servers and muxes come or go…
There are two issues with keeping this state though. Firstly , it can sometimes end up incomplete or out of date (especially under periods of rapid network change, such as during scale out and scale in). Secondly, there’s only a finite amount of resource to back that state, which opens the door to denial of service attacks such as SYN flood attacks.
Beamer is a stateless datacenter load balancer supporting both TCP and Multipath TCP (MPTCP). It manages to keep the load balancers stateless by taking advantage of connection state already held by servers.
Our prototype implementation can forward 33 million minimum-sized packets per second on a ten core server, twice as fast as Maglev, the state of the art load balancer for TCP traffic. Our stateless design allows us to cheaply run Beamer in hardware too…
You can find Beamer at https://github.com/Beamer-LB.
Datacenter load balancing and problems of state
A typical load balancing deployment looks like this:
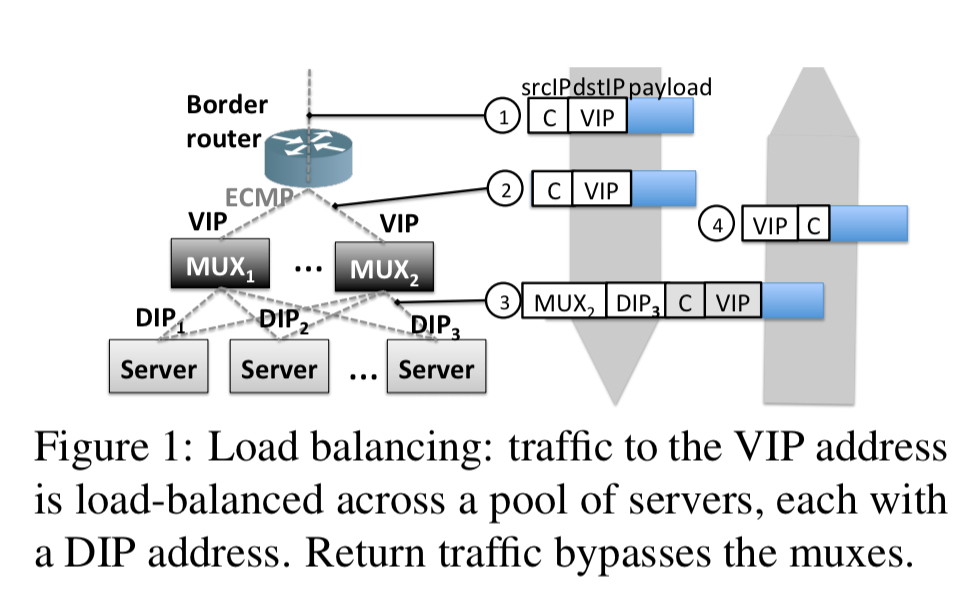
A datacenter border router is the door to the outside world. Muxes communicate with the border router using BGP, announcing the virtual IPs (VIPs) they are responsible for. A VIP is the outward facing IP address of a datacenter service. The border router uses equal-cost multipath routing (ECMP) to split the traffic equally across the muxes. Behind the VIP at a mux sits a pool of servers that actually provide the service. These destination servers have their own private addresses called direct IPs or DIPs. The mux chooses destination servers for new connections based on a hash of the five-tupleª. Changing the number of servers in the DIP pool means that at least some assignments of five-tuple hashes to DIPs will change (including those for existing connections). For this reason, once a mapping of connection to to DIP is chosen it is stored locally to ensure all future packets go to the same DIP.
a: (source ip, source port, destination ip, destination port, protocol)
The mux encapsulates the original packet and sends it on to the DIP. At the receiving server the packet is extracted, the original destination address changed from the VIP to the DIP, and it is then processed by the regular TCP stack. Any replies bypass the mux: for reply packets the source address is changed from the server’s DIP to the service’s VIP and the packet is sent directly to the client (aka Direct Source Return, DSR).
Because replies bypass the muxes, it is possible for the view of the connection state to differ between a destination server and a mux. For example, if a client disconnects after sending a SYN packet the mux will remember the mapping for minutes, but the chosen back-end server will terminate the connection after a few failed attempts at establishing it. SYN-flood attacks exploit this by deliberating creating large numbers of half-open connections until resource is exhausted. Defending against SYN-flood attacks requires keeping even more state at the muxes (SYN cookies), and/or terminating TCP at the mux. Both solutions limit scalability.
Scale out events which add more muxes and back-end servers can also cause problems. When we add a mux, the border router will start sending it traffic. If some of that traffic is for existing connections, the new mux won’t have any saved connection state for them. The 5-tuple hash would choose the same destination IP as the original mux though, so long as the number of backend servers is not changing at the same time. Which it usually is.
Beamer’s secret sauce: stable hashing and daisy-chaining
Consider a scale-out event as we just discussed, in which we start out with mux 1 and destination server A, and add mux 2 and destination server B.
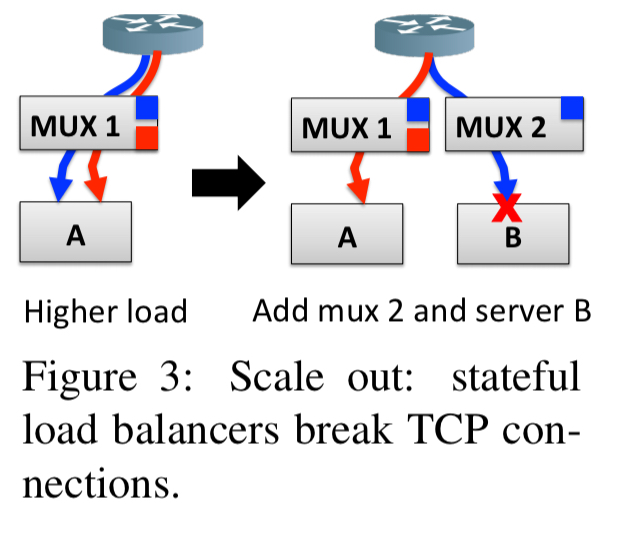
Traffic for an existing connection terminated at A might now start following the blue path (caused by ECMP balancing and different hash results inside mux 2 due to the change in size of the DIP pool). Normally, when B receives a packet for a connection it doesn’t know about, it would just reset the connection. In Beamer, B does not reset the connection, instead it forwards packets it doesn’t have state for to A, where they can be processed normally. (How B knows to send them to A we’ll come to shortly). This forwarding between backend servers is called daisy chaining and is the core idea behind Beamer. During times of stability, we won’t need to avail ourselves of the daisy chaining facility, but under change we can use it to keep things running without interruption. Since the load balancer was only retaining state to keep consistent routing in the face of change, we now don’t need state in the load balancer!
There are three key parts to Beamer:
- A stable hashing algorithm that reduces the amount of churn caused by DIP pool changes. This ensures we don’t need to daisy chain very often, keeping performance high.
- An in-band signalling mechanism that gives servers enough information to do daisy chaining when they need to.
- A fault-tolerant control plane that scalably disseminates data plane configurations to all mutexes.
Stable hashing
A simple hashing algorithm would be to use hash(5tuple) % N where N is the number of DIPs. This causes a lot of churn in assignments when N changes though. Consistent hashing, rendezvous hashing, and Maglev hashing all combine good load balancing with reduced disruption under churn. A downside is that muxes end up with lots of matching rules, reducing performance.
Beamer’s answer is a layer of indirection called stable hashing. Before load balancing starts for a given VIP the operators determines a fixed number of buckets B, such that B is larger than the maximum number of expected DIPs in the pool (e.g., B = 100N). Each bucket is assigned to a single server at a time, a server can be responsible for multiple buckets simultaneously. The number of buckets and bucket to server assignments are known by all muxes (yes, that’s state!! ) and disseminated via a separate control plane mechanism. Strictly then, Beamer muxes are not stateless, but critically they don’t maintain any per-flow state.
When a packet arrives, muxes hash it to a bucket by computing
b=hash(5tuple) % Band then forward the packet to the server currently assigned bucket B. As B is constant by construction, server churn does not affect the mapping result: a connection always hashes to the same bucket regardless of the number of active DIPs.
Changing bucket-to-server mappings are stored in a coordination service (Apache ZooKeeper in the implementation), and muxes retrieve the latest version before serving traffic. Changes to bucket-to-DIP mappings are rare, so the mechanism has low coordination overhead.
Bucket-to-server mappings can be managed using consistent hashing or similar. Beamer uses a greedy assignment algorithm that aims to maximise contiguous bucket ranges assigned to muxes, which reduces the number of rules needed and is especially useful for hardware deployments.
Daisy chaining
Daisy chaining is used to cope with the period when a bucket-to-server assignment has changed, but there are still in-flight connections with the old destination server. On reconfiguration, a mux saves the previous DIP for each bucket along with the time the reallocation took place. Encapsulated packets from the mux to the (new) DIP carry this information with them.
When a packet arrives at a backend server it is processed locally if it is a SYN, a valid SYN-cookie ACK, or it belongs to a local connection. Otherwise, the server inspects the last-bucket-change timestamp in the packet. If it is within the daisy chaining timeout (a hard limit of four minutes in the implementation) then the previous DIP is extracted and packet is forwarded. If we are outside of the time limit the packet is dropped and a RST is sent back to the source.

There’s one more problem that can occur when rolling out an update across muxes. Suppose we start with a configuration including only mux 1, and then mux 2 comes online and a bucket reconfiguration is rolled out. A connection is routed via mux 2 (which has the new configuration) to backend server A. If via ECMP subsequent packets end up being sent to mux 1, before mux 1 has switched to the new configuration, then mux 1 will know nothing about the new bucket-to-server mapping and may well route the packet to a different backend without the correct daisy chaining information. To solve this an epoch (generation) number is also included in the packets.
When (a backend server) receives a mid-connection packet that can not be daisy chained and for which it has no state, it will check if the generation number from the mux equals the highest generation number seen; if yes, the connection will be reset. If not, the server silently discards the packet. This will force the client to retransmit the packet, and in the meantime the stale mux mappings will be updated to the latest generation, solving the issue. Note that, if the border router uses resilient hashing, the mechanism above becomes nearly superfluous.
MPTCP
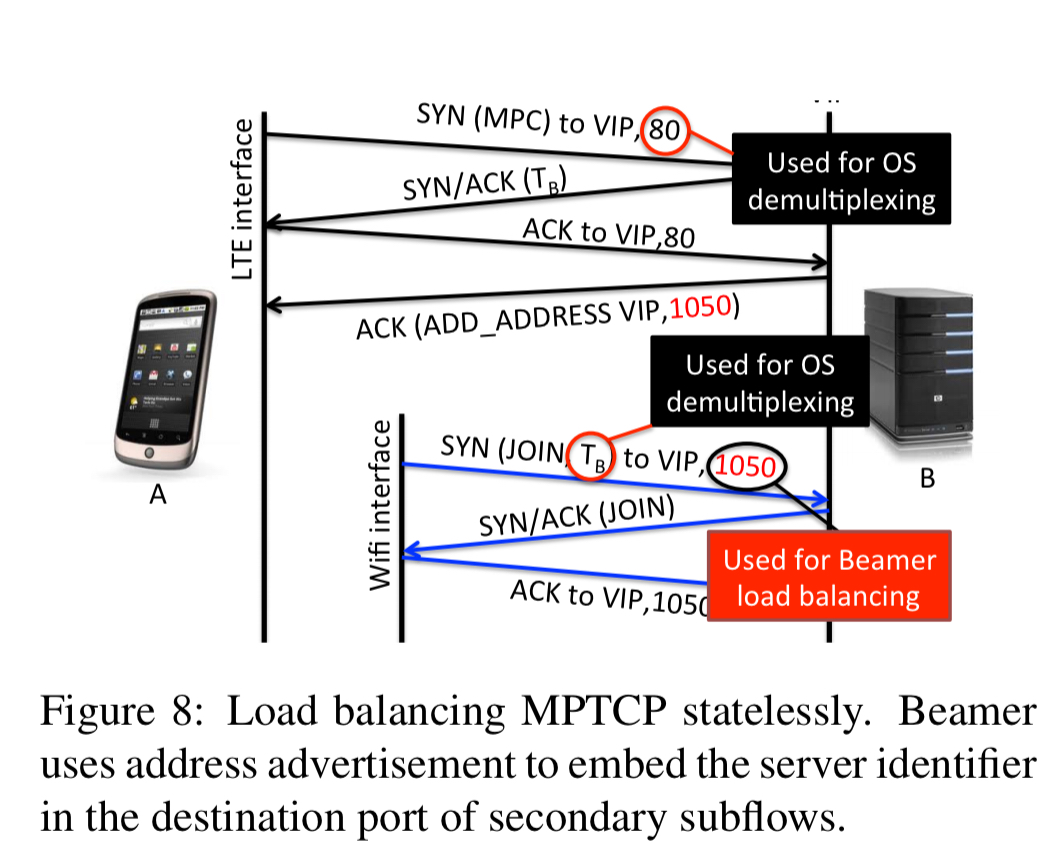
Beamer can also handle MPTCP traffic (all iOS-based phones have MPTCP, as do high end Android devices). MPTCP connections contain multiple subflows. Beamer uses the (otherwise unused) destination port in SYN JOIN packets to encode the server identifier for secondary subflows. Ports 1-1024 are reserved for actual services, port numbers in the range 1025-65535 are used to encode server identifiers.
Whenever a new MPTCP connection is established, servers send an ACK with
add addressoption to the client with the VIP address and the server identifier as port number. The client remembers this new address/port combination and will send subsequent subflows to it.
The control plane
The control plane is built on top of ZooKeeper and uses two-phase commit to keep copies in sync. Only the controller writes to ZooKeeper, and muxes only read. Backend servers do not interact with ZooKeeper at all.
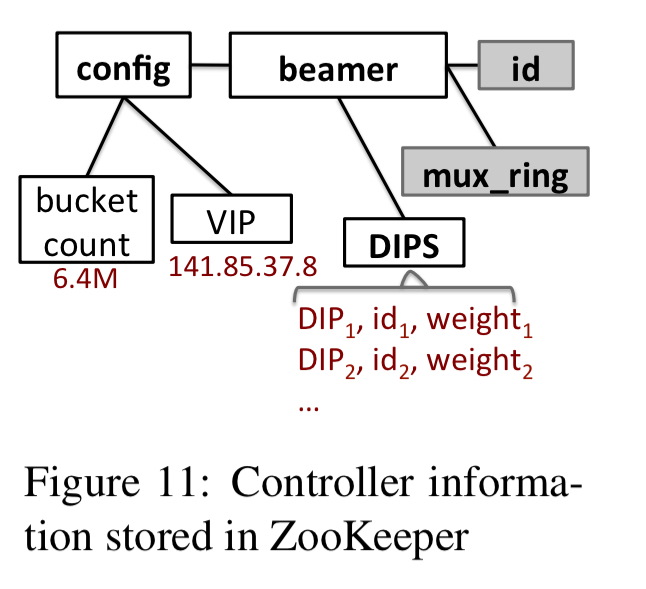
See §4.5 for the fine print.
Evaluation results
Experiments on EC2 tested Beamer with one hundred muxes, 64K DIPs, and 6.4 million buckets.
Our results show that Beamer is simultaneously fast and robust: no connections are ever dropped, in contrast to stateful approaches, Beamer’s dataplane performance is twice that of the best existing software solution, and our mux introduces negligible latency when underloaded (100µs).
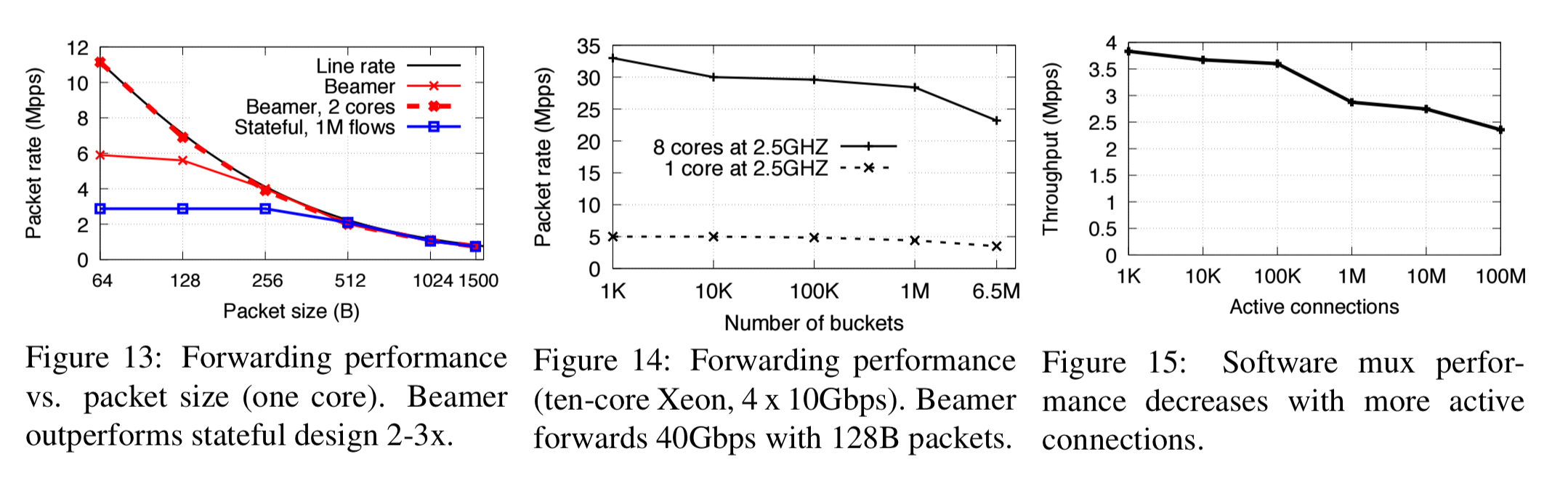
(Enlarge)
With a single server sourcing around 1-10Gbps of traffic, a single software mux could cater for 50-500 servers. Testing a P4 prototype implementation using a hardware simulator showed that a P4 mux can handle around 60Mpps.
The evaluation section also contains an analysis of the impact of mux churn (§6.2), MPTCP load balancing (§6.3), and controller scalability (§6.4), which I don’t have space to cover here. The short version is that everything seems to work well!
Our experiments show that Beamer is not only fast, but also extremely robust to mux and server addition, removal, or failures as well as heavy SYN flood attacks.

{kind=link}
3 thoughts on “Stateless datacenter load-balancing with Beamer”
Comments are closed.