Maglev: A Fast and Reliable Software Network Load Balancer – Eisenbud et al. 2016
Maglev is Google’s software load balancer used within all their datacenters. It offers greater scalability and availability than hardware load balancers, enables quick iteration, and is much easier to upgrade. Maglev is a just another distributed system running on the commodity servers within a cluster. Maglev must provide an even distribution of traffic, connection persistence (packets belonging to the same connection should always be directed to the same service endpoint), and high throughput with small packets. The first of these requirements is satisfied through the use of Equal Cost Multipath (ECMP) forwarding. The latter two are satisfied through a combination of consistent hashing and connection tracking.
The Big Picture
Every Google service has one or more Virtual IP addresses (VIPs). A VIP is different from a physical IP in that it is not assigned to a specific network interface, but rather served by multiple service endpoints behind Maglev. Maglev associates each VIP with a set of service endpoints and announces it to the router over BGP; the router in turn announces the VIP to Google’s backbone. Aggregations of the VIP networks are announced to the Internet to make them globally accessible. Maglev handles both IPv4 and IPv6 traffic, and all the discussion below applies equally to both…
Google’s DNS servers assign users to nearby frontend locations taking into account both the user’s geolocation and also the current load at each location. DNS will return a VIP, and the user will then try to establish a connection with that VIP. A router inside of Google’s datacenter that receives a VIP packet forwards it to one of the Maglev machines in the cluster through ECMP (all Maglev machines announce the VIP with the same cost). The Maglev machine will select a backend endpoint and encapsulate the packet using GRE (Generic Routing Encapsulation) – it is unpacked and consumed at the backend service.
The response, when ready, is put into an IP packet with the source address being the VIP and the destination address being the IP of the user. We use Direct Server Return (DSR) to send responses directly to the router so that Maglev does not need to handle returning packets, which are typically larger in size.
Every Maglev machines contains a controller and a forwarder. The controller monitors the health of the forwarder and decides whether to announce or withdraw all the VIPs via BGP. The forwarder does all the heavy lifting.
All VIP packets received by a Maglev machine are handled by the forwarder. At the forwarder, each VIP is configured with one or more backend pools. Unless otherwise specified, the backends for Maglev are service endpoints. A backend pool may contain the physical IP addresses of the service endpoints; it may also recursively contain other backend pools, so that a frequently used set of backends does not need to be specified repeatedly.
A forwarder’s config manager learns the VIPs to be served from configuration objects – either read from files or received via RPCs. All config updates are committed atomically.
Packet Forwarding
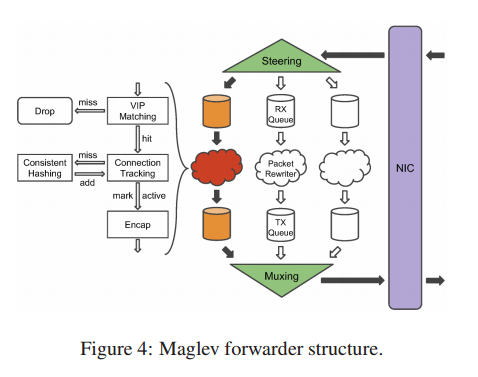
The forwarder receives packets directly from the NIC, rewrites them with GRE/IP headers, and sends them back to the NIC. The Linux kernel is completely bypassed.
Packets from the NIC are processed by the steering module which assigns them to one of a number of packet receiving queues using a hash function. Each queue is serviced by a dedicated thread which is pinned to a dedicated CPU core. These packet rewriter threads recompute the hash of the packet (the previous hash is not reused in order to avoid cross-thread synchronization) and look up the hash value in a connection tracking table. If a match is found and the backend is still healthy then the result is reused. Otherwise the thread consults the consistent hashing module to select a new backend for the packet, and adds a new entry to the connection tracking table. Each thread has its own connection tracking table to avoid contention. Once a backend has been selected, the packet is encapsulated with the appropriate GRE/IP headers and sent to the thread’s transmission queue. The muxing module polls all transmissions queues and passes the packets back to the NIC.
For both the selection of a receiving queue, and the hashing done within a packet rewriter thread, Maglev uses 5-tuple hashing: source IP, source port, destination IP, destination port, IP protocol number.
The steering module performs 5-tuple hashing instead of round-robin scheduling for two reasons. First, it helps lower the probability of packet reordering within a connection caused by varying processing speed of different packet threads. Second, with connection tracking, the forwarder only needs to perform backend selection once for each connection, saving clock cycles and eliminating the possibility of differing backend selection results caused by race conditions with backend health updates. In the rare cases where a given receiving queue fills up, the steering module falls back to round-robin scheduling and spreads packets to other available queues. This fallback mechanism is especially effective at handling large floods of packets with the same 5-tuple
If a large datagram is split into two (or more) fragments (IP fragmentation) then only the first fragment contains all of the 5-tuple elements; subsequent fragments contain only the L3 header (3-tuple). Only a few VIPs are allowed to receive fragments, and they are handled by configuring all Maglevs with a special backend pool consisting of all Maglev machines in the cluster. A fragment is hashed using the 3-tuple and forwarded to a Maglev from the pool based on the hash value. Here a fragment table is kept which records forwarding decisions for first-fragments so that subsequent fragments can be sent to the same destination.
For efficient communication between Maglev and the NIC, Maglev pre-allocates a packet pool shared between the NIC and the forwarder on start-up. The steering and muxing modules maintain a ring queue of pointers to packets in the packet pool.

Both the steering and muxing modules maintain three pointers to the rings. At the receiving side, the NIC places newly received packets at the received pointer and advances it. The steering module distributes the received packets to packet threads and advances the processed pointer. It also reserves unused packets from the packet pool, places them into the ring and advances the reserved pointer. The three pointers chase one another as shown by the arrows. Similarly, on the sending side the NIC sends packets pointed to by the sent pointer and advances it. The muxing module places packets rewritten by packet threads into the ring and advances the ready pointer. It also returns packets already sent by the NIC back to the packet pool and advances the recycled pointer. Note that the packets are not copied anywhere by the forwarder.
Normally it takes the packet thread about 350ns to process each packet on Google’s standard servers. With a packet pool size of 3000 and a forwarder processing 10M packets per second, it takes about 300µs to process all buffered packets.
Backend Selection with Consistent Hashing
For connection-oriented protocols such as TCP, we need to send all the packets of a connection to the same backend. Under normal circumstances the connection tracking table takes care of this – but we still need to assign a backend in the case that the table has no entry, and since tables are not shared across threads, let alone Maglev instances, things like rolling upgrades of Maglev clusters can lead to connections switching between Maglev instances.
Maglev provides consistent hashing to ensure reliable packet delivery under such circumstances.
In fact, Maglev aims for ‘minimal disruption’ rather than an absolute guarantee. A small number of disruptions is tolerable by Maglev. Thus Maglev’s scheme aims for:
- fair load balancing – each backend should receive an almost equal number of connections, and
- minimal disruption – when the set of backends changes, a connection will likely be sent to the same backend as it was before
At the core of the approach is a lookup table…
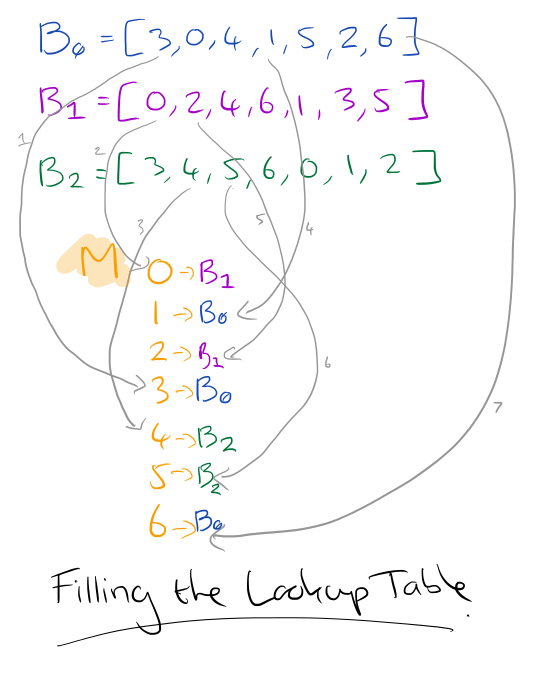
The basic idea of Maglev hashing is to assign a preference list of all the lookup table positions to each backend. Then all the backends take turns filling their most-preferred table positions that are still empty, until the lookup table is completely filled in. Hence, Maglev hashing gives an almost equal share of the lookup table to each of the backends. Heterogeneous backend weights can be achieved by altering the relative frequency of the backends’ turns…
Let N be the size of a VIP’s backend pool. A table is constructed with M entries, where M is a prime number and M > 100 * N, which will ensure at most a 1% difference in hash space assigned to backends.
Each backend node is associated with a random permutation of 0..M-1. To construct this random permutation, Google rely on the fact that each backend server has a unique name. Using two different hash functions, an offset and skip value are calculated for the backend:
offset = hash1(name) mod M
skip = hash2(name) mod (M-1) + 1
Suppose M is 7, and for a given backend i offset = 3 and skip = 4. We would generate the random permutation for this backend as follows:
permutation[i][0] = 3
permutation[i][1] = 0 // (3 + 1*4) mod 7
permutation[i][2] = 4 // (3 + 2*4) mod 7
permutation[i][3] = 1 // (3 + 3*4) mod 7
permutation[i][4] = 5 //(3 + 4*4) mod 7
permutation[i][5] = 2 // (3 + 5*4) mod 7
permutation[i][6] = 6 // (3 + 6*4) mod 7
Once we have permutations for all i backends, we fill in the lookup table M by allowing each backend to pick a slot in turns until all the slots are filled (a bit like captains picking players for a school sports team). When a backend gets to pick a slot, it works through its permutation list, and chooses the first slot in M from that list which is not already taken.
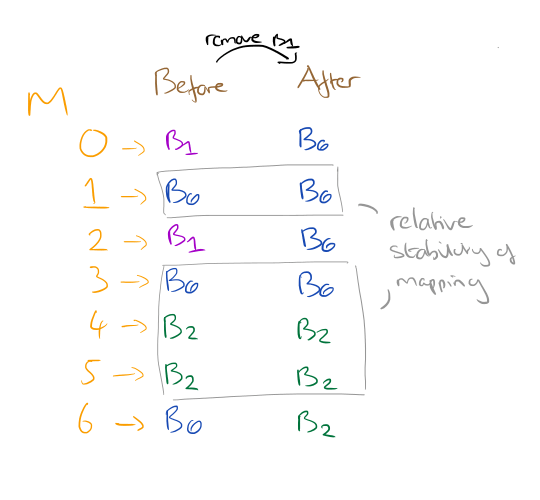
The reason for going to these lengths is the relative stability of the mappings when a backend node is added or removed. Consider what happens if B1 is removed from the lookup table in our previous scenario and we rebuild the lookup table:
We built Maglev to scale out via ECMP and to reliably serve at 10Gbps line rate on each machine, for cost-effective performance with rapidly increasing serving demands. We map connections consistently to the same backends with a combination of connection tracking and Maglev hashing. Running this software system at scale has let us operate our websites effectively for many years, reacting quickly to increased demand and new feature needs.

Adrian, in your hand-drawn diagrams (which are lovely, by the way) your zeros look a lot like sixes. Good job this wasn’t confusing. :-)