Skyway: connecting managed heaps in distributed big data systems Nguyen et al., ASPLOS’18
Yesterday we saw how to make Java objects persistent using NVM-backed heaps with Espresso. One of the drawbacks of using that as a persistence mechanism is that they’re only stored in the memory of a single node. If only there was some way to create a cluster of JVMs, and efficiently copy objects across remote heaps in the cluster… Meet Skyway!
Skyway is aimed at JVM-based big data systems (think Spark, Flink) that end up spending a lot of their time serializing and deserializing objects to move them around the cluster (e.g., to and from workers – see ‘Making sense of performance in data analytics frameworks’). Java comes with a default serialization mechanism, and there are also many third party libraries. Kryo is the recommended library for use with Spark.
Consider a small Spark cluster (3 worker nodes each with a 20 GB heap) running a triangle counting algorithm over the LiveJournal graph (about 1.2GB). With both the standard Java serializers and Kryo, serialization and deserialization combined account for a significant portion of the overall execution time (more than 30%).
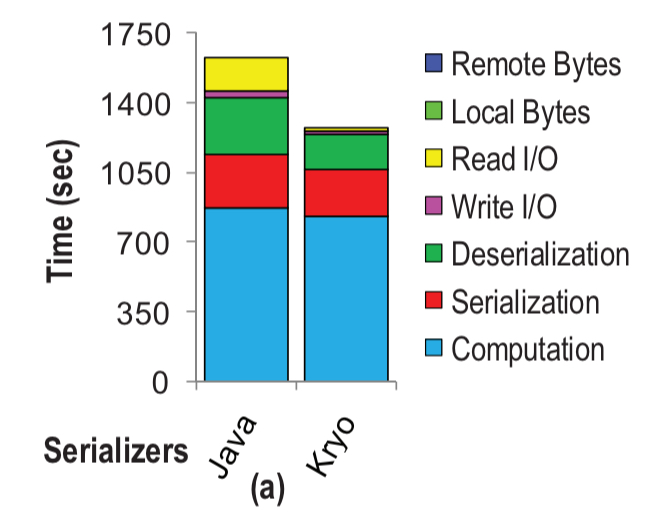
Where does all the time go? To transfer an object o from one JVM to another takes three steps:
- A serialization procedure turns the whole object graph reachable from o into a binary sequence. During this process the serializer extracts the object data, strips the header, removes all references stored in an object, and changes the representation of certain metadata.
- The byte sequence is sent across the wire
- A deserialization procedure reads the byte sequence, creates objects accordingly, and rebuilds the object graph in the managed heap of the receiver machine.
In a big data system, a transfer can involve millions of objects, which means invoking, e.g., reflection APIs millions of times or more. Moreover, the Java serializer represents every type by a string containing the name of a class and all its superclasses. These type strings can consume a huge portion of the byte sequence transferred across the network, and reflection has to be used on the receiver end to resolve types from the string. Reflection is also heavily used when repairing object references in the graph on the receiving end.
The key problem with existing S/D (serialization/deserialization) libraries is that, with an existing JVM, there are no alternative routes to transfer objects other than first disassembling and pushing them down to a (different) binary format, and the reassembling and pulling them back up into a remote heap. In this paper, we advocate to build a “skyway” between managed heaps so that data objects no longer need to pushed down to a lower level for transfer.
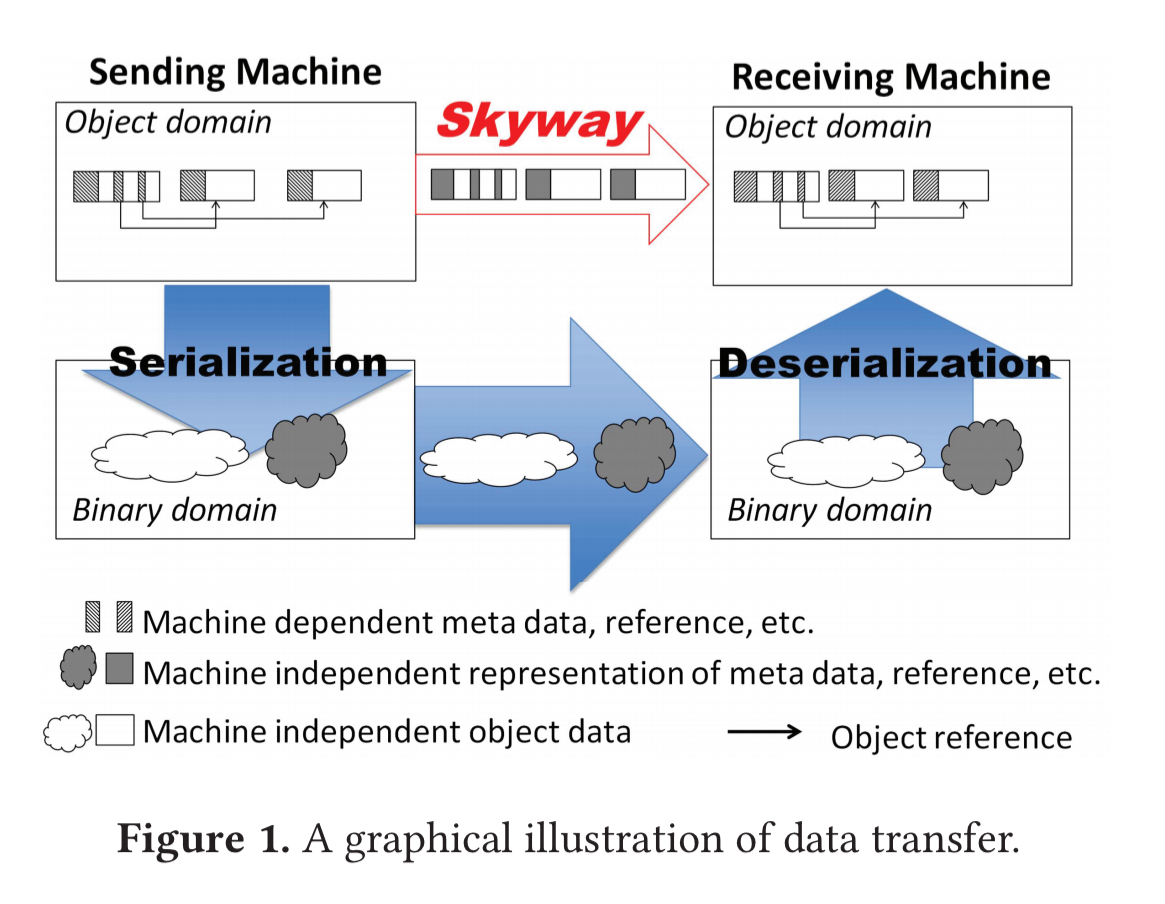
At a high level, Skyway is fairly easy to understand. It extends the JVM (OpenJDK) to enable object graphs to be moved as is from one heap to another, and immediately used on a remote node right after the move. Given a root object o, Skyway performs a GC-like traversal copying every reachable object into an output buffer while performing only a very lightweight adjustment to machine-dependent metadata. Crucially, the object format is not changed and every object is transferred as a whole. This includes the hashcode, so that hash-based data structures can be used on the receiver node without rehashing.
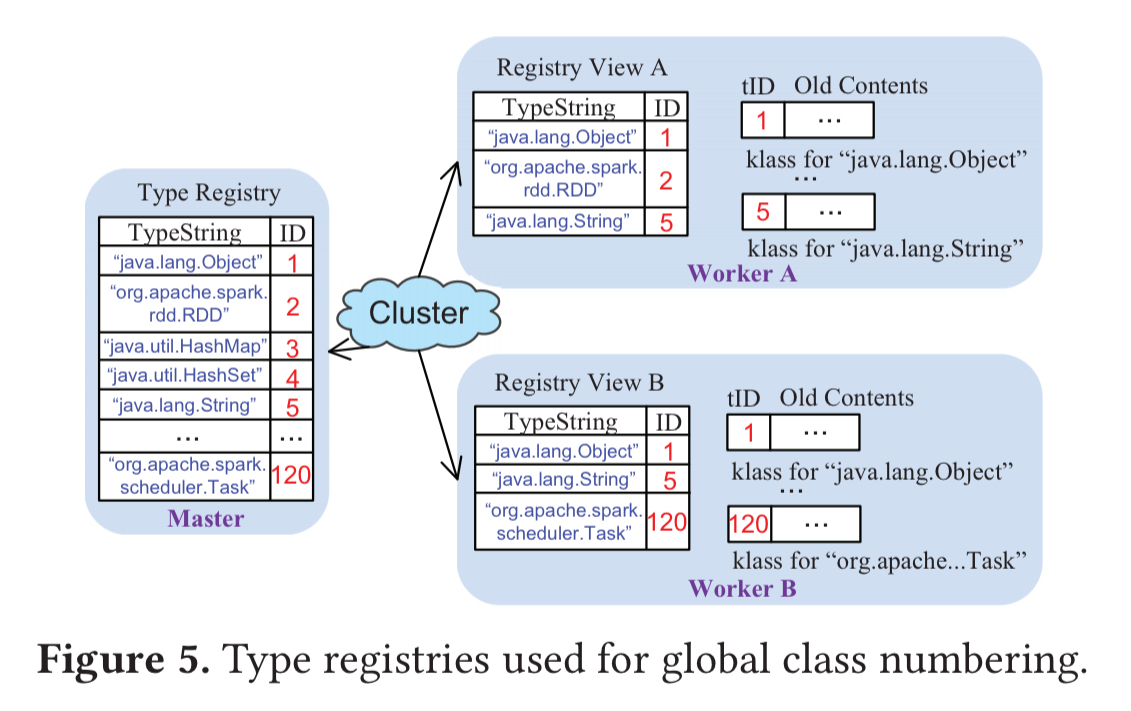
Types are represented by a global type-numbering procedure which assumes a master-workers pattern and keeps a registry of all types and their ids at the master. Workers communicate with the master to obtain ids for classes upon class loading.
Absolute addresses in objects are turned into relative addresses when copied into the output buffer. The output buffer is streamed to an input buffer at the remote node, where the relative addresses are turned back into absolute addresses in the target heap.
…data processing applications frequently shuffle many millions of objects and do so in strongly delimited phases. Hence, sending objects in batch without changing their formats provides significant execution efficiency. Second, the use of modern network technology enables extra bytes to be quickly transferred without incurring much overhead.
Skyway under the covers

Skyway uses a GC-like mechanism to discover the object graph reachable from a set of root objects. Objects encountered during the traversal are copied into an output buffer (located in off-heap native memory so it doesn’t interfere with GC), which is streamed to the corresponding buffer(s) on the receiving node. Input buffers are allocated in the old generation (tenured) of the managed heap, and can span multiple memory chunks – handy since you don’t always know the ultimate size of the buffer when streaming starts. Root objects in a stream are demarcated by special top marks which helps the receiver to efficiently read entire graphs without needing to parse all of their content. Once a data transfer is complete, Skyway updates the card table of the Parallel Scavenge GC making the new objects reachable via garbage collection.
Skyway can support heterogeneous clusters, where JVMs may have different object formats, by adjusting the format of objects as they are copied into the output buffer. The implementation on top of OpenJDK 1.8.0 touches the classloader subsystem, the object/heap layout, and the Parallel Scavenge garbage collector.
Skyway develops a distributed type-registration system that automatically allows different representations of the same class on different JVM instances to share the same integer ID. This system completely eliminates the need to represent types during data transfer…
The driver / master JVM maintains a complete type registry covering all classes that have been loaded in the cluster, initially populated by scanning its own loaded classes after JVM startup. When a worker JVM starts up it requests a copy of the registry from the driver, giving it a view of all classes loaded in the cluster to that point. If a worker JVM loads a class that does not yet exist in its local registry view it checks with the driver to obtain an ID for it. Whereas the standard Java serializer sends a type string over the network with every object, Skyway sends a type string at most once for every class on each machine during the entire computation.
Performance evaluation
The first evaluation compares Skyway against 90 existing serialization libraries using the Java serializer benchmark set (JSBS). Results for the fastest 28 are shown below.

Skyway is the fastest of the lot: 2.2x faster than Kryo-manual (intrusive), and 67x faster than the Java serializer.
The next experiment modifies Spark (v1.2.0) to replace the use of Kryo-manual with the Skyway library. Four programs (Word Count, Page Rank, Connected Components, and Triangle Counting) are each run over four different graph inputs:
The following charts summarise the performance of Java serialisation, Kryo, and Skyway for each of the programs across each of the input graphs:
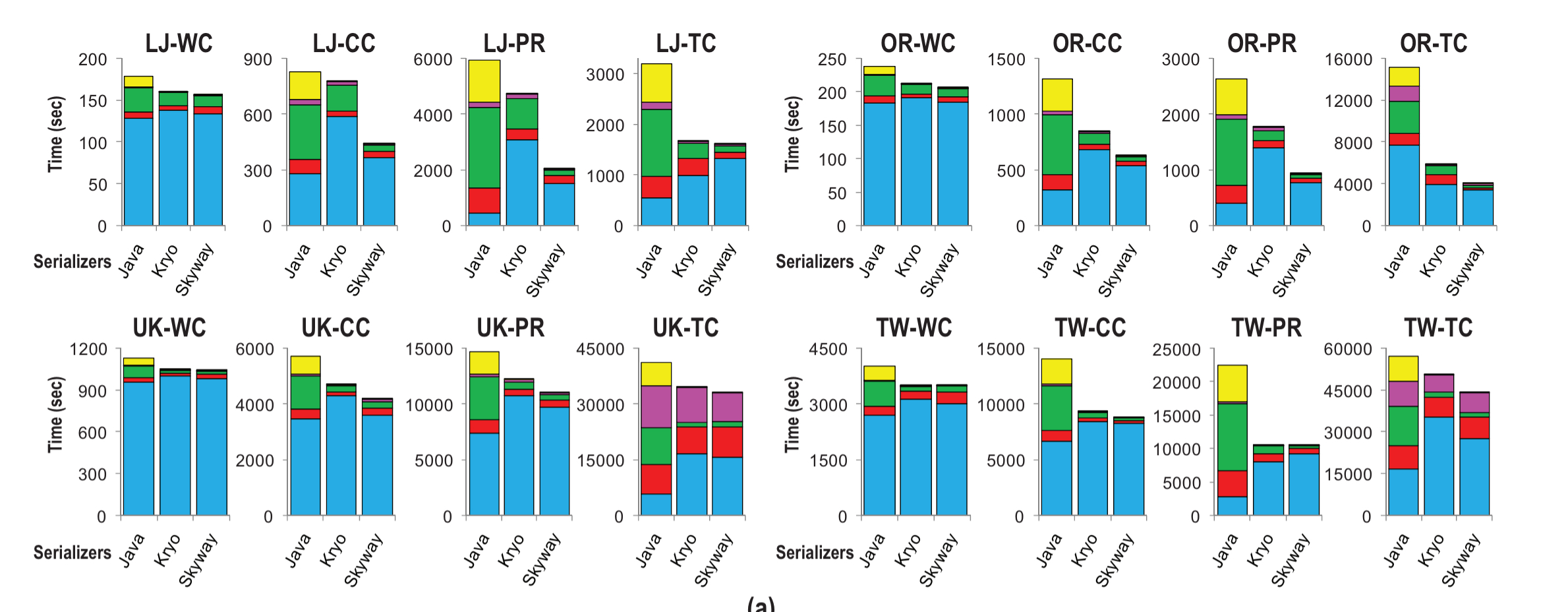

Skyway makes Spark run 36% faster than the Java serializer, and 16% faster than Kryo.
Skyway is also evaluated against Flink 1.3.2 (released Aug 2017) in a batch processing mode. The TPC-H data generator is used to generate a 100GB input dataset, and 5 representative TPC-H queries are transformed into Flink applications. The performance of Skyway vs Flink’s built-in serializer is show below:
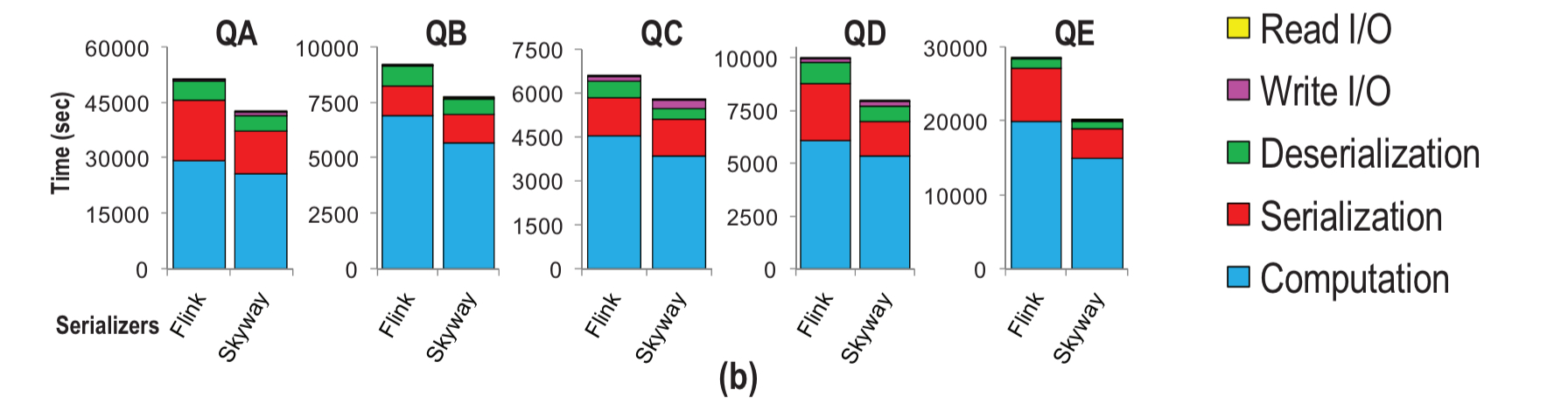
Skyway improves Flink’s performance by 19% on average.

Our evaluation shows that Skyway outperforms all existing S/D libraries and improves widely-deployed systems such as Spark and Flink.

Very cool!
I don’t think the authors are quite correct stating that java serializer sends the type name for every object. It sends class metadata (including the name) once per class within a given serialization stream. If a stream contains multiple objects of the same type, they will all refer to the offset of the same metadata block. For large object graphs, where # of objects >> # of classes, I expect the java serializer to be much more competitive (close to kryo). For small graphs, its overhead is considerable.
Typo and broken link to Kryo. (I assume you do mean Kryo).
Fixed, thank you! I’d spelt ‘Kryo’ wrong in about five places :(!