Espresso: brewing Java for more non-volatility with non-volatile memory Wu et al., ASPLOS’18
What happens when you introduce non-volatile memory (NVM) to the world of Java? In theory, with a heap backed by NVM, we should get persistence for free? It’s not quite that straightforward of course, but Espresso gets you pretty close. There are a few things to consider, for example:
- we probably don’t want all of our objects backed by persistent memory, as it still has higher latency than DRAM
- we don’t want to make intrusive changes to existing code, and ideally would be able to continue using JPA (but why go through an expensive ORM mapping if we’re not targeting a relational store?)
- we need to ensure any persistent data structures remain consistent after a crash
Espresso adds a new type of heap, a persistent Java heap (PJH) backed by NVM, and a persistent Java object (PJO) programming abstraction which is backwards compatible with JPA. PJO gives a 3.24x speedup even over JPA backed by H2.
JPA, PCJ, and NVM
JPA is the standard Java Persistence API. Java classes are decorated with persistence annotations describing their mapping to an underlying relational database. It’s an ORM (Object Relational Mapper), so to persist user data all operations need to be translated into SQL statements which are then sent to a backing RDBMS through JDBC. This translation happens even when using an all-Java in-memory database such as H2.
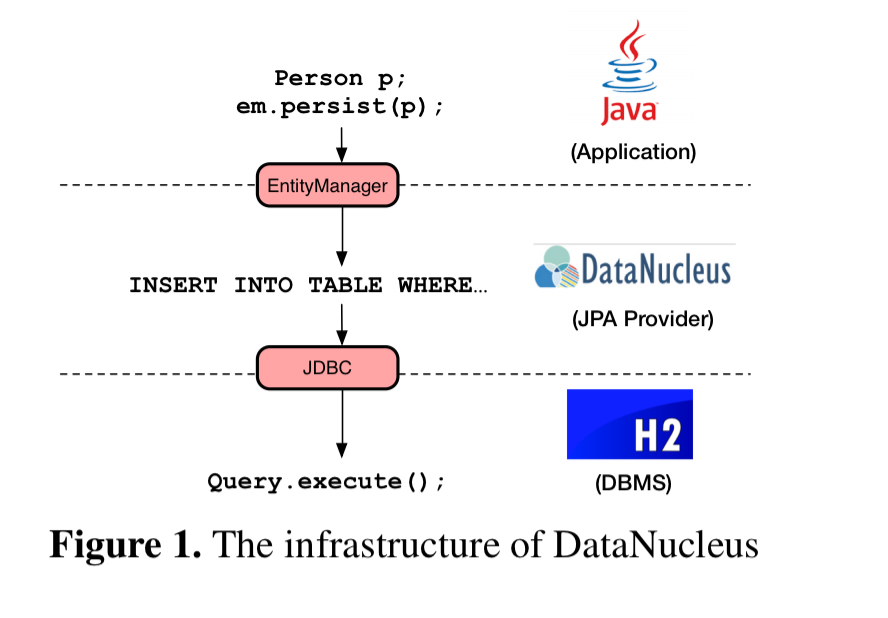
It turns out that all that mapping is quite expensive: transforming objects to SQL statements accounts for about 41.9% of the total execution time when using the DataNucleus JPA implementation over H2 on NVM.
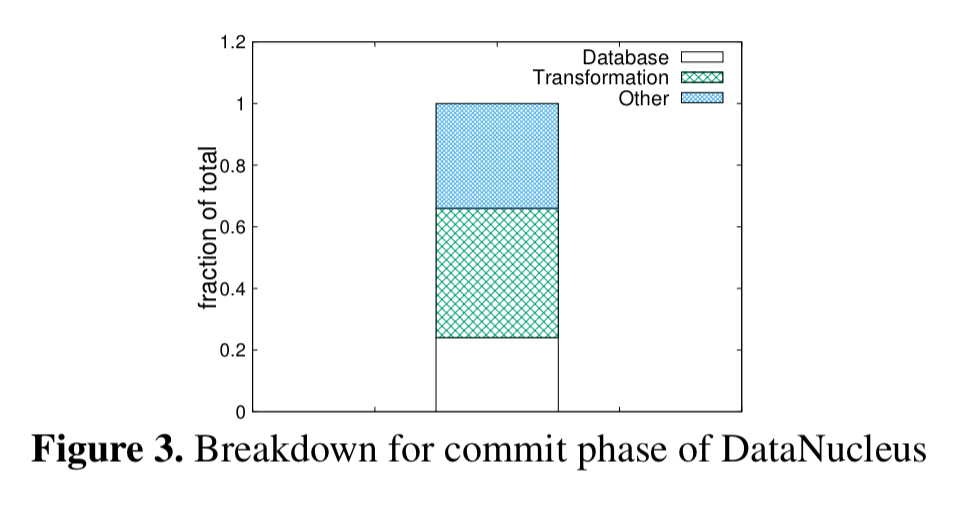
Stating the obvious perhaps, when we’re targeting persistent memory which can persist object state directly all of that translations seems unnecessary. NVM seems to more naturally fit with the object store paradigm.
For this reason, Intel introduced a project called Persistent Collections for Java (PCJ). PCJ is expressively designed to work with NVM, but introduces its own ugly (imho!) and intrusive programming model requiring non-trivial re-engineering to transform existing data structures into a form you can use with PCJ. Since it’s not especially well integrated with the JVM, PCJ stores all of its persistent data as native off-heap objects and has to provide its own synchronization and garbage collection as a result. This all introduces quite a bit of overhead – in fact, as we’ll see later, Espresso is up to 256x faster than PCJ!
What we really want for NVM object persistence is the following:
- A unified persistence model supporting both fine-grained (low-level) persistence and coarse-grained (e.g. JPA) persistence
- High performance, with minimal overhead
- Backward compatibility so that existing applications can be ported to run on top of it with ease.
Persistent Java Heaps (PJH)
Espresso adds a new PJH heap type based on the PSHeap (Parallel Scavenge Heap) in OpenJDK.
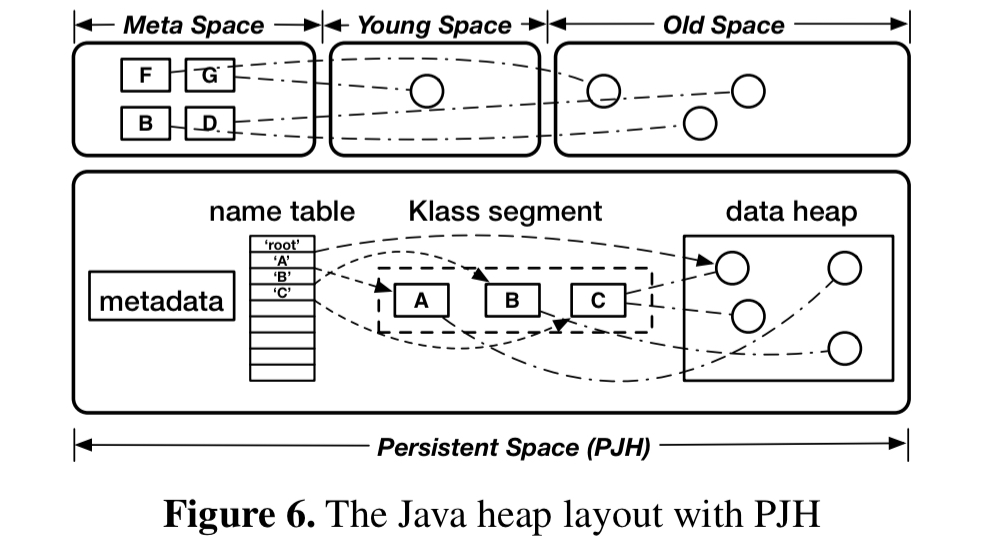
PJH is implemented as an independent Persistent Space against the original PSHeap. It is designed as a non-generational heap since we believe that NVM will be mostly used to store long-lived data due to its persistence guarantee and inferior performance compared to DRAM… The garbage collection algorithm for PJH resembles the old GC in PSGC (Parallel Scavenge Garbage Collector) in that it is designed for long-lived objects and infrequent collections…. All the components are persisted in NVM to guarantee the crash-consistency of the PJH.
Each object in Java holds a pointer to its class-related metadata, a Klass in OpenJDK. Since Espresso allows objects of the same type to be stored in both DRAM and NVM the same type can end up with two different Klasses, which you’ll see as those lovely ClassCastExceptions. PJH introduces the concept of an alias Klass to finesse this. All Klasses have a new field pointing to their alias Klass, and aliases share metadata such as static members and methods. Type checking is extended with alias checking, and the OpenJDK Server Compiler is extended to consider aliases during JIT optimisations as well.
The low-level programming model as a new keyword to the Java programming language: pnew. pnew works like new, except that it creates the corresponding object in a PJH heap backed by NVM.
Here’s a Person class with two persistent fields: id and name. You would create a persistent instance of this class with e.g. Person p = pnew Person(id, name). I’m not quite sure what it would mean if you used regular ‘new’ to create a Person object, given that its members are always created as persistent. That seems an odd mix.

In our programming model, users are allowed to create multiple PJH instances served for various applications. They are also required to define root objects as handles to access the persistent objects even after a system reboot.
The most obvious way to use this facility seems to be to have one persistent heap per aggregate entity. There are some low-level APIs for managing persistent heaps and their roots as follows:


One tricky thing with all these heaps is that it’s possible to have persistent (NVM backed) objects with pointers to volatile (DRAM backed) objects. What should happen to these pointers when a persistent heap is (re)loaded?
If users try to access a reference to volatile memory after heap reloading, the reference can point to anywhere and modifications of the referenced data can cause undefined consequences.
That sounds like a recipe for debugging hell! Fortunately you have to explicitly enable this rather dangerous mode, and the default is to set all pointers to volatile objects back to null on reloading. Yes, you’re going to have to watch out for NullPointerExceptions, but at least the behaviour is defined! Espresso also provides an set of simple annotations which can be used to ensure that persistent objects don’t have non-persistent state, but this requires applications to be modified explicitly for NVM. (I might have gone for a design similar to java.io.Serializable’s readObject to allow the programmer control over replacing the volatile objects).
Crash Consistency
Object allocation takes place in three stages:
- Fetching the Klass pointer from the constant pool
- Allocating memory and updating the value of the top pointer
- Initialising the object header
For crash consistency the value of the top pointer must be persisted immediately after step 2 (e.g., via cache flush and fence). The Klass pointer update in step 3 also needs to be persisted straight away.
The original garbage collection algorithm is also carefully modified to ensure crash consistency. The modifications mostly comprise a snapshot taken before the compact phase, and a timestamp-based algorithm to infer and recover from crash state. Details are in section 4.2.
Persistent Java Objects
PJH guarantees crash consistency for heap-related metadata, but for application data higher level ACID guarantees are still required. JPA provides a convenient programming model, but as we’ve seen it has high overheads when targeting NVM. Espresso’s Persistent Java Object (PJO) framework uses JPA interfaces and annotations, but works directly with PJH.
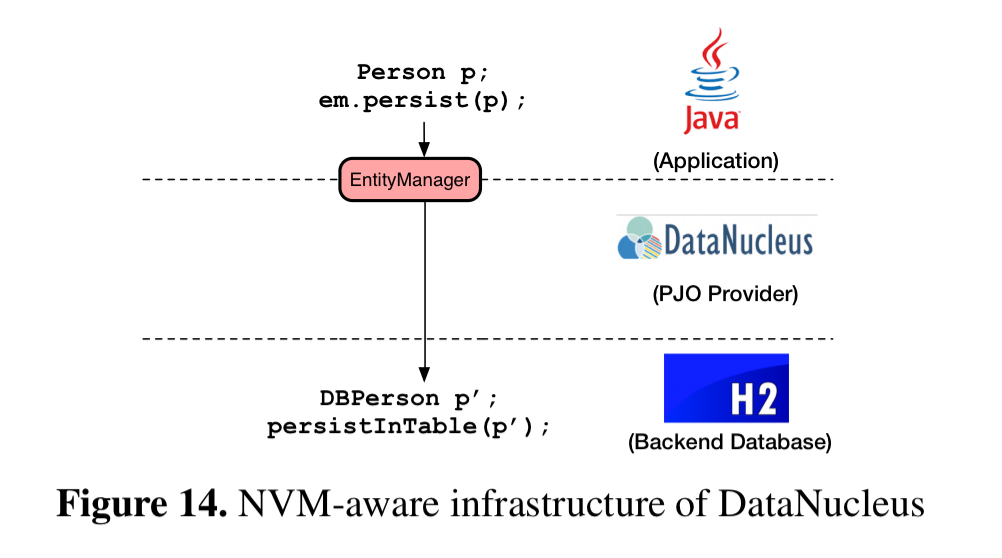
We have implemented a PJO provider by modifying DataNucleus. It provides the same APIs as JPA does such that no modification to applications is required. Programmers can leverage the APIs provided by the PJO provider to retrieve, process and update data in an object-oriented fashion. Similarly to JPA, PJO also supports various types such as inherited classes, collections, and foreign-key-like references.
H2 is also modified to make it support both PJO and PJH (mainly replacing new with pnew in the latter case).
Benchmarks
PJH smashes PCJ in tests, with speed-ups ranging from 6x to 256x. But you probably weren’t using PCJ anyway, so I’m not going to spend any space here drilling into that. Of more interest is the results from running the JPA Benchmark (JPAB) to compare PJO against vanilla JPA. The baseline is DataNucleus and H2 running on NVDIMM (note, it would go faster if DRAM was used for the baseline, i.e, the comparison wouldn’t look so favourable). Pitted against it is the PJO modified DataNucleus and H2. The third comparison line in the chart below (H2-PJO-v) is PJO implemented on the stock JVM using a normal heap supported by DRAM.
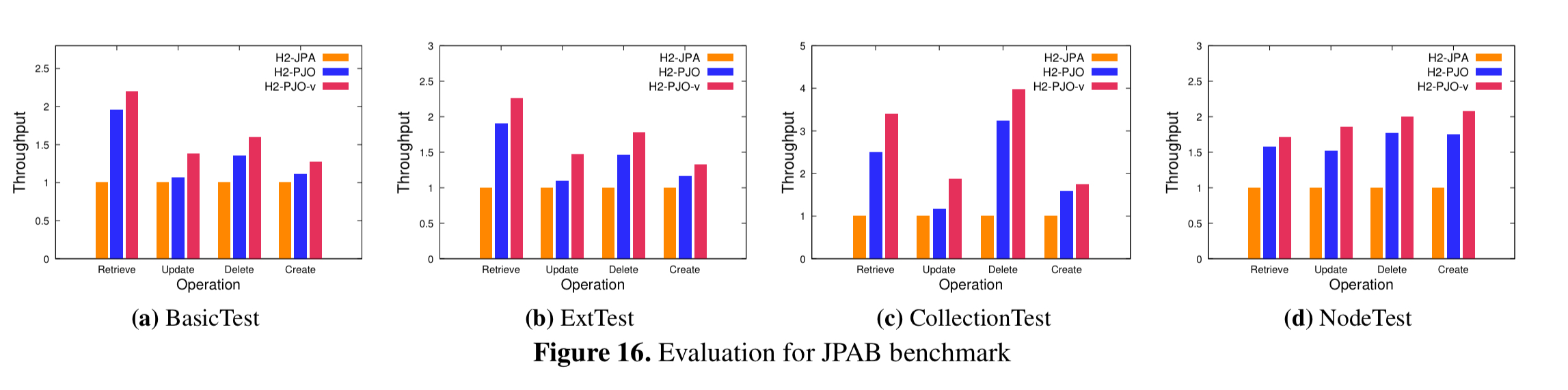
(Enlarge)
PJO (H2-PJO) outperforms H2-JPA in all cases and provides up to 3.24x speedup. (Compared to persisting to e.g. Postgres or MySQL it will offer even greater speedups of course). It’s still not quite as fast as ‘persisting’ to DRAM though (H2-PJO-v).

{kind=link}
One thought on “Espresso: brewing Java for more non-volatility with non-volatile memory”
Comments are closed.