Google workloads for consumer devices: mitigating data movement bottlenecks Boroumand et al., ASPLOS’18
What if your mobile device could be twice as fast on common tasks, greatly improving the user experience, while at the same time significantly extending your battery life? This is the feat that the authors of today’s paper pull-off, using a technique known as processing-in-memory (PIM). PIM moves some processing into the memory itself, avoiding the need to transfer data from memory to the CPU for those operations. It turns out that such data movement is a major contributor to the total system energy usage, so eliminating it can lead to big gains.
Our evaluation shows that offloading simple functions from these consumer workloads to PIM logic, consisting of either simple cores or specialized accelerators, reduces system energy consumption by 55.4% and execution time by 54.2%, on average across all of our workloads.
Energy as a limiting factor
While the performance requirements of consumer devices increase year on year, and devices pack in power-hungry CPUs, GPUs, special-purpose accelerators, sensors and high-resolution screens to keep pace, lithium ion battery capacity has only doubled in the last 20 years. Moreover, the thermal power dissipation in consumer devices is now a severe performance constraint.
…among the many sources of energy consumption in consumer devices…, data movement between the main memory system and the computation units (e.g., CPUs, GPU, special-purpose accelerators) is a major contributor to the total system energy.
For example, when scrolling through a Google Docs web page, simply moving data accounts for 77% of the system energy consumption.
…the energy cost of moving data is orders of magnitude higher than the energy cost of computation. We find that across all of the applications we study, 62.7% of the total system energy, on average, is spent on data movement between main memory and the compute units.
PIM to the rescue?
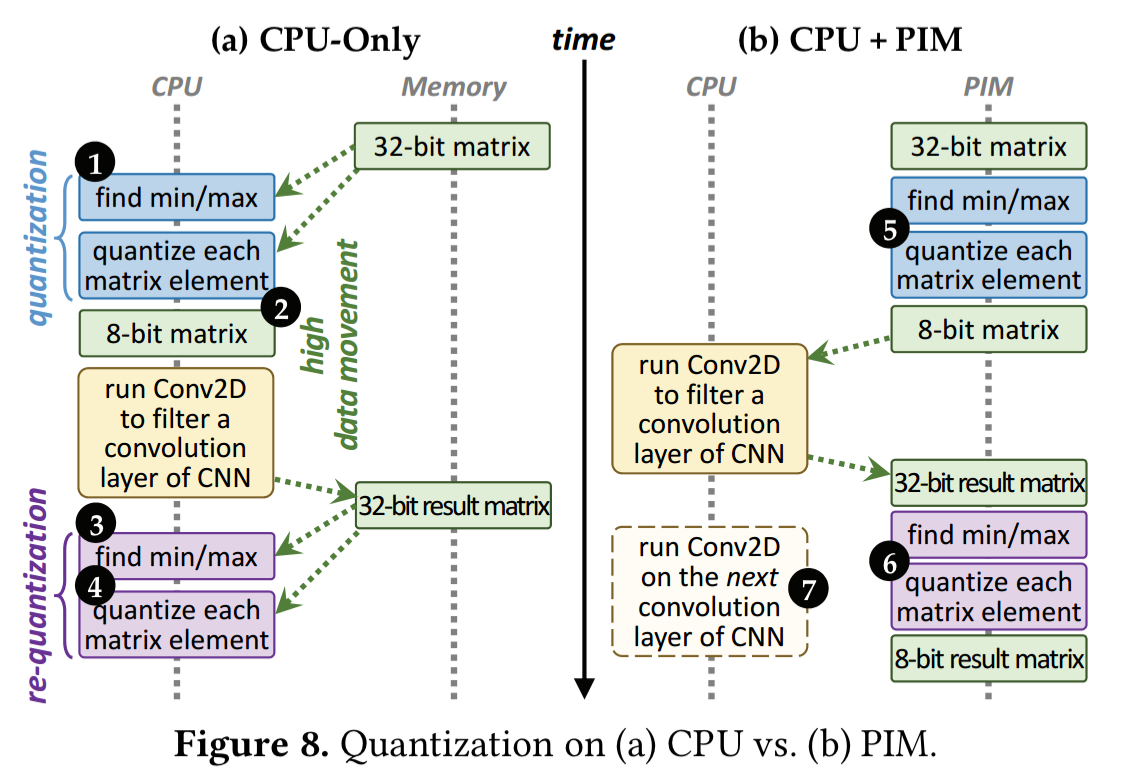
It follows therefore that the total system energy requirements can be greatly reduced (which is the main goal of the work, the performance speed-ups are just a nice bonus!) if we can avoid moving data. If we don’t want to move the data, the alternative is to move the compute to where the data already is. Here we’re talking about data in memory (DRAM), and compute on a CPU. How can we offload compute from CPUs to DRAM???
The emergence of 3D-stacked DRAM architectures offers a promising solution. These architectures stack multiple layers of DRAM arrays within a single chip, and use vertical through-silicon vias (TSVs) to provide much greater bandwidth between layers than the off-chip bandwidth available between DRAM and the CPUs. Several 3D-stacked DRAM architectures provide a dedicated logic layer within the stack that can have low-complexity (due to thermal constraints) logic.
Using this logic layer, it is possible to perform processing in memory (PIM), also known as near-data processing. Offloading processing using PIM avoids the energy hungry data movement, and also enables us to take advantage of the high-bandwidth, low-latency data access inside the DRAM. Given the area and energy constraints of consumer devices though, there’s not a lot of room to play with. So the offloaded processing logic needs to be kept relatively simple.
The paper explores two different ways of utilising the available PIM capacity:
- By creating a PIM core: a small low-power general-purpose embedded core,
- By embedding a small collection of fixed-function accelerators (PIM accelerators).
PIM accelerators can provide larger benefits, but require custom logic to be implemented for each workload.
To study the feasibility and benefits of PIM for consumer devices, the authors study several common workload types using when browsing the web, running TensorFlow models (used by e.g. Google Translate, Google Now, and Google Photos), playing videos (e.g. YouTube), and video capture (e.g. Google Hangouts)….
These workloads are among the most commonly used applications by consumer device users, and they form the core of many Google services that each have over a billion monthly active users.
Browsing the web
The user perception of browser speed is based on page load time, smooth scrolling, and fast switching between tabs. The authors study the energy demands in scrolling and tab switching tasks (both of which also involve page loading).
Scrolling
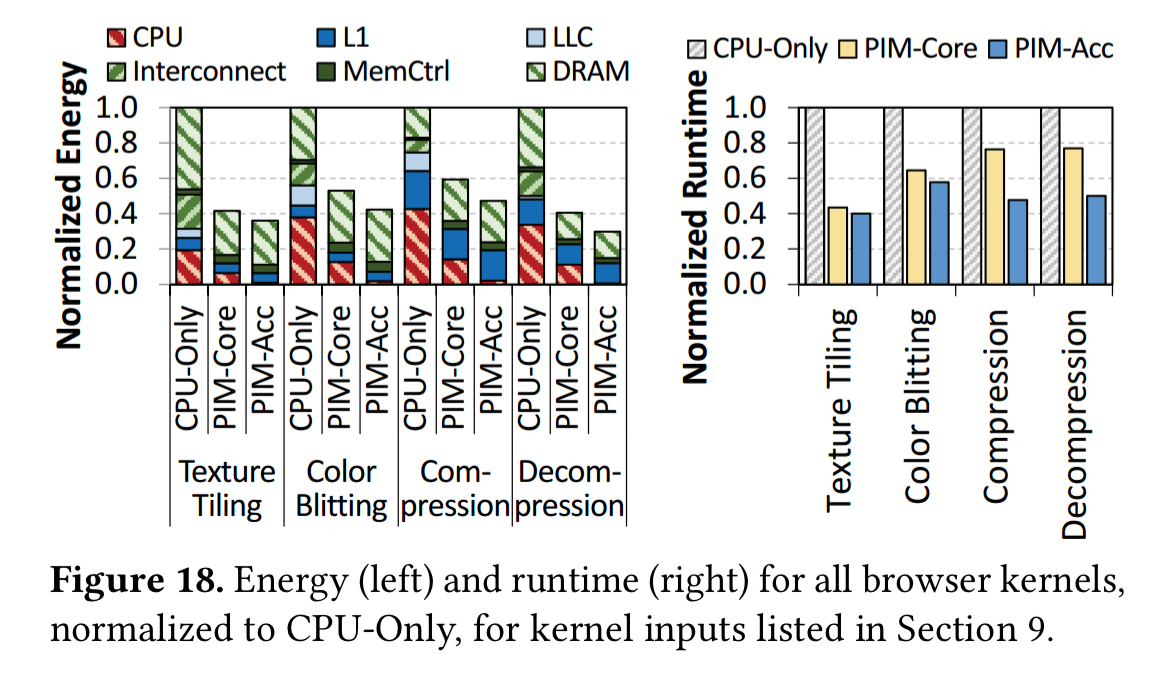
On average across all pages in the test, 41.9% of page scrolling energy is spent on texture tiling and colour blitting:
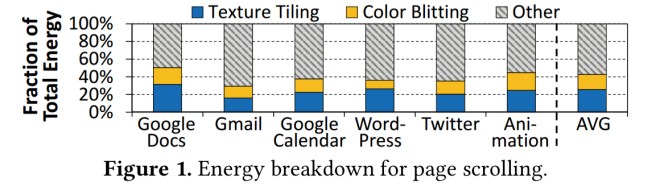
For scrolling through a Google Docs web page, fully 77% of the total energy consumption turns out to be due to data movement.
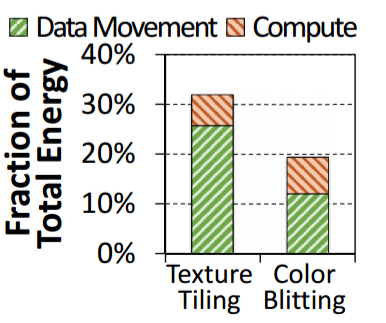
Texture tiling is the biggest culprit. The standard texture tiling process reads linear bitmaps in from memory, converts them to tiled textures, and writes the tiles back to memory (see left-hand side of the figure below). If we can offload texture tiling to PIM, we can save all that data movement back-and-forth:
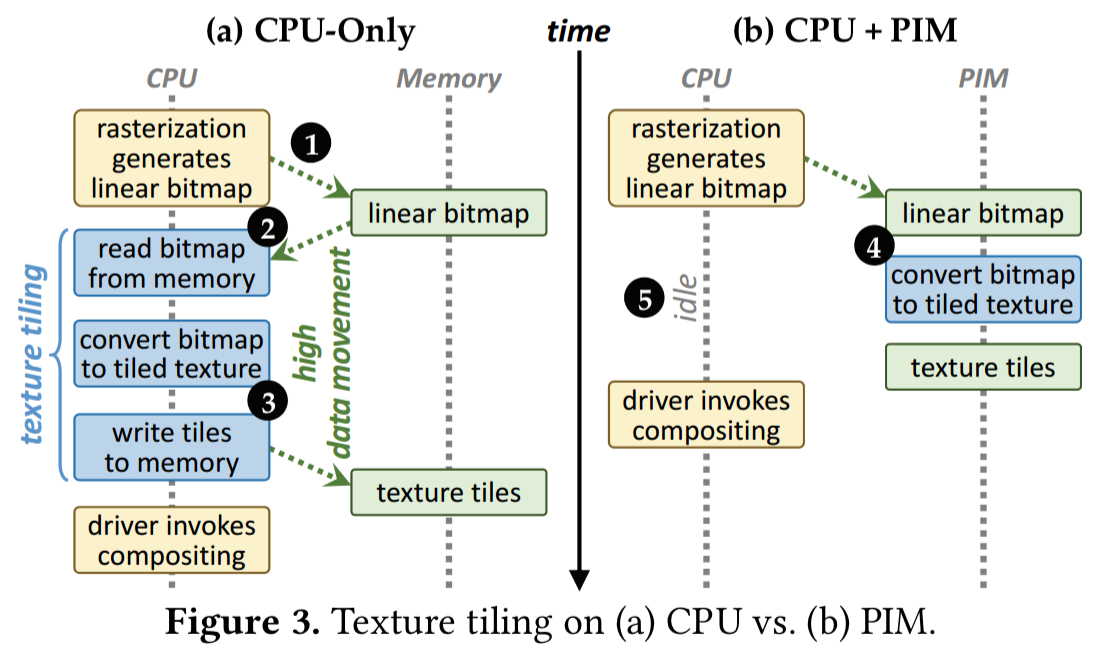
Our analysis indicates that texture tiling requires only simple primitives: memcopy, bitwise operations, and simple arithmetic operations (e.g. addition). These operations can be performed at high performance on our PIM core, and are amenable to be implemented as a fixed-function PIM accelerator.
19.1% of the total system energy used during page scrolling is attributable to color blitting, and 63.9% of that to data movement. Color blitting also requires only low-cost computations such as memset, simple arithmetic, and shift operations. Thus it can also be moved to PIM.
Switching tabs
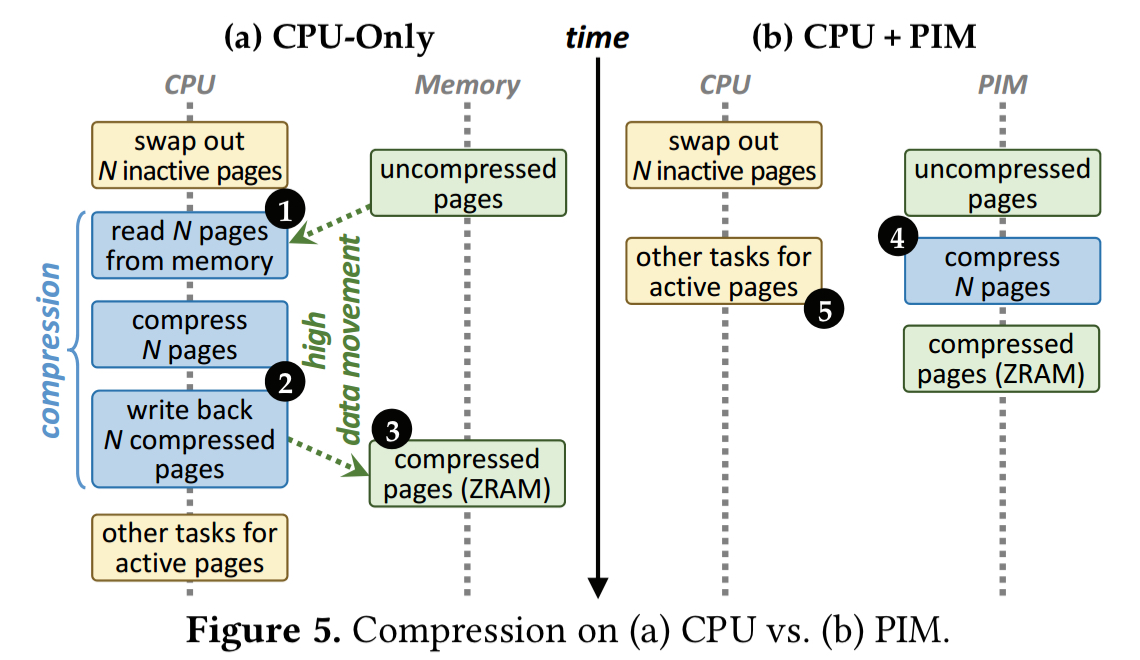
When under memory pressure, Chrome compresses the memory pages of inactive tabs and places them into a DRAM-based memory pool called ZRAM. Swapping data in and out and the associated compression and decompression causes a lot of data movement.
Compression and decompression are both good candidates to move to PIM-based execution. Chrome’s ZRAM uses LZO compression which uses simple operations and can execute without performance loss on the PIM core.
Benefits
The following chart compares the energy costs of the CPU-only approach versus using the general purpose PIM core or special purpose PIM accelerators. On average, PIM core reduces energy consumption by 51.3%, and PIM accelerators by 61.0%. Moreover, PIM-Core and PIM-Acc both significantly outperform the CPU only approach, improving performance on average by 1.6x and 2.0x respectively.
Feeding it forwards (TensorFlow Mobile)
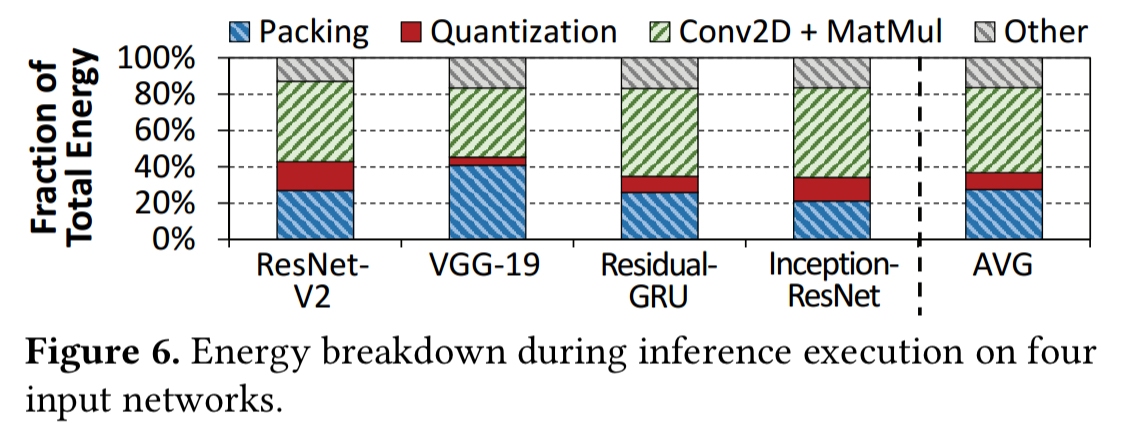
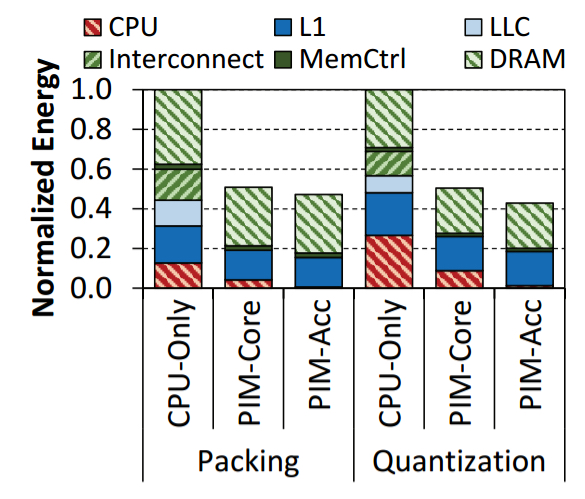
Within TensorFlow mobile, an energy analysis reveals that the most energy-hungry operations are packing/unpacking and quantization (39.3% of total system energy). Together these are responsible for 54.4% of the data movement energy.
They are also responsible for a large chunk of the execution time:
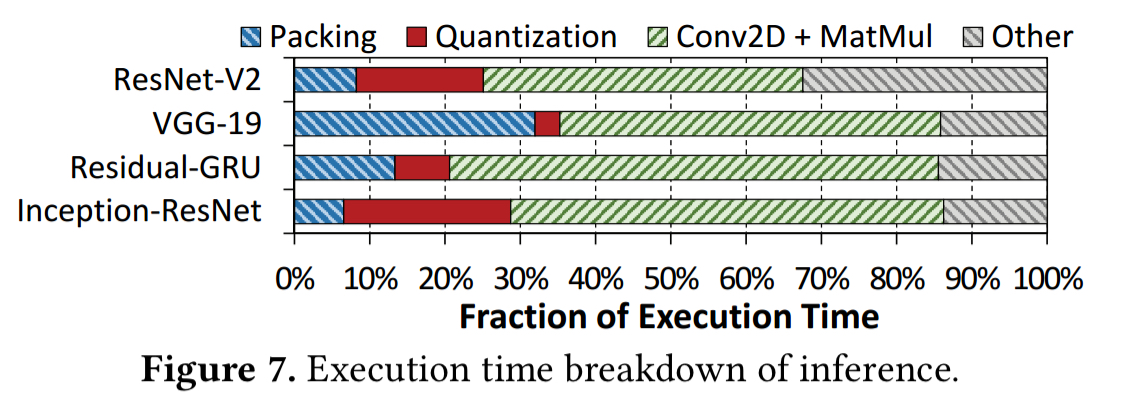
Packing and unpacking reorder elements of matrices to minimise cache misses during multiplication, and quantization converts 32-bit floating point and integer values into 8-bit integers.
Our analysis reveals that packing is a simple data reorganization process and requires simple arithmetic operations to scan over matrices and compute new indices. As a result, packing and unpacking can be performed at high performance on our PIM core, or on a PIM accelerator…
Quantization is also a simple data conversion operation and can be similarly offloaded:
The end result is a 50.9% (54.9%) reduction in energy usage for PIM-Core (PIM-Accelerator) compared to the CPU-only benchmark.
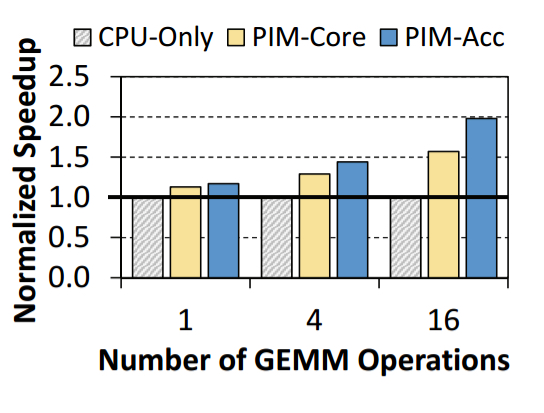
Furthermore, the PIM-based approaches also show speedups of up to 2x, depending on the number of GEMM (Generalized Matrix Multiplication) performed.
Watching and recording videos
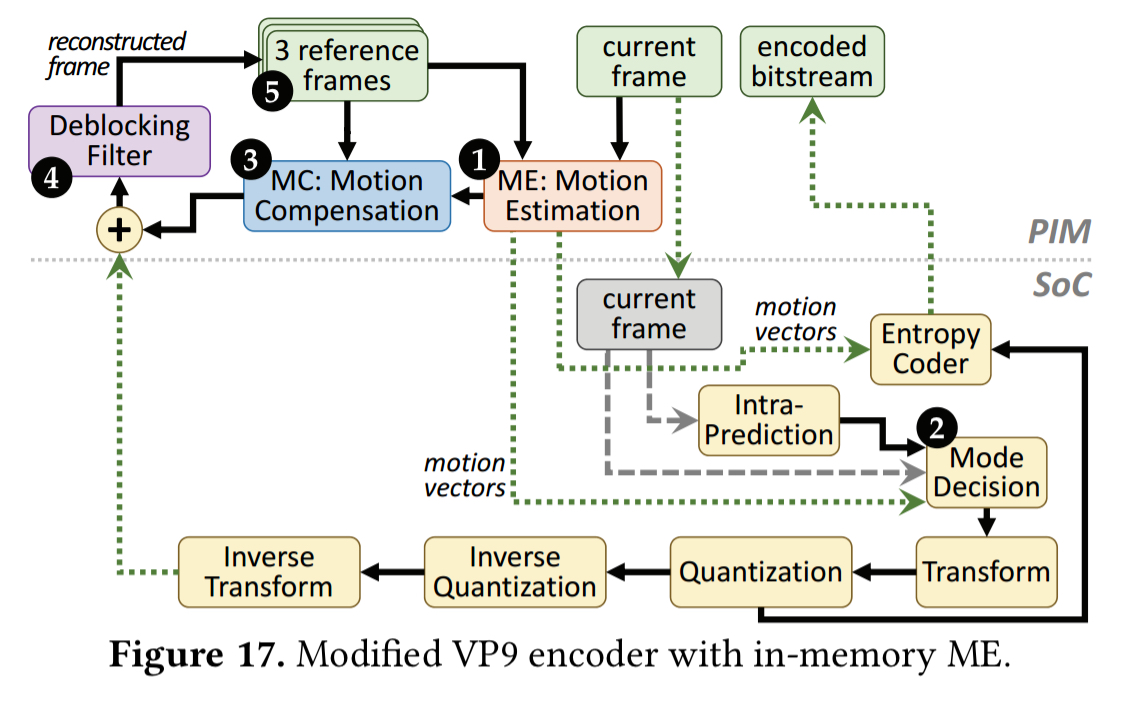
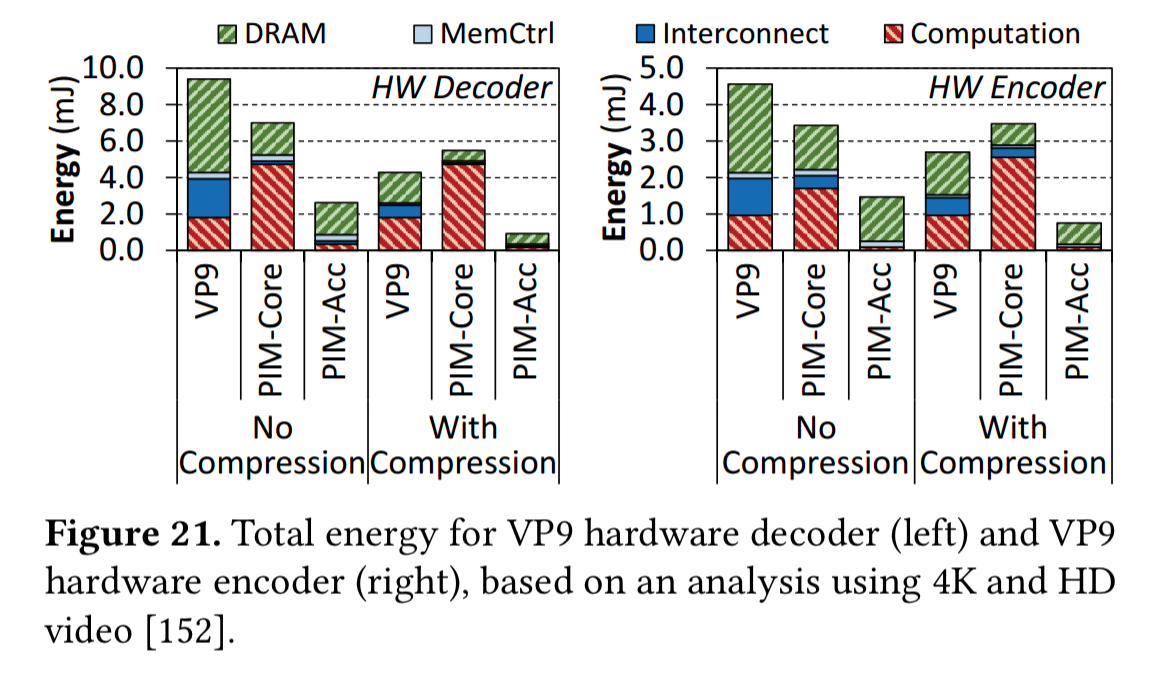
The paper contains an analysis of both software and hardware based VP9 decoding (an open-source codec widely used by video-based applications). For higher resolution playback, hardware decoders are essential. Even in the hardware case, the authors still find a significant amount of off-chip data movement generated by the hardware decoder. The main culprit is a process called sub-pixel interpolation, which takes place in the motion compensation (MC) unit and requires reading reference frame data (2.9 reference frame pixels are read from DRAM for every pixel of the current frame).
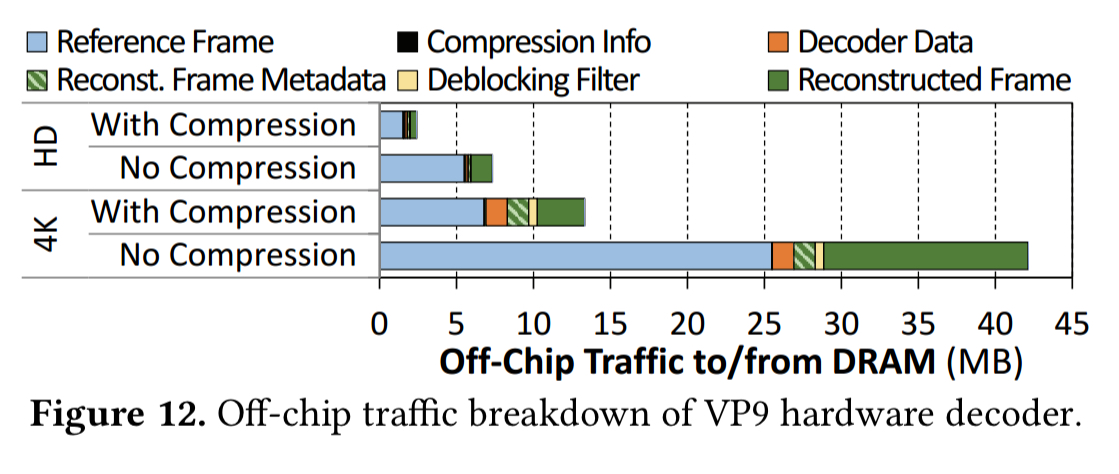
The MC unit is a good fit for PIM execution, because we can eliminate the need to move reference frames from memory to the on-chip decoder, thus saving significant energy.
Recording (encoding) shows a similar high rate of data movement due to reference frame fetching. The Motion Estimation unit responsible for this can also be moved to PIM execution.
In the video case though, with compression enabled, PIM-Core actually uses 63.4% more energy than the VP9 hardware baseline. But PIM accelerators still bring benefits: reducing energy by 75.1% during decoding, and 68.9% during encoding.
In summary
Our comprehensive experimental evaluation shows that PIM cores are sufficient to eliminate a majority of data movement, due to the computational simplicity and high memory intensity of the PIM targets. On average across all of the consumer workloads that we examine, PIM cores provide a 49.1% energy reduction (up to 59.4%) and a 44.6% performance improvement (up to 2.2x) for a state-of-the-art consumer device. We find that PIM accelerators provide larger benefits, with an average energy reduction of 55.4% (up to 73.5%) and performance improvement of 54.2% (up to 2.5x) for a state-of-the-art consumer device.

That’s incredible! Am I correct in assuming that they designed a new chip to make this happen, or were they able to “reprogram” existing hardware?
Hello Dr Colyer
Long time reader, always appreciate your diligent selection, reading and reporting. This is a very useful paper, thanks a bundle!
Some words/sentence seems to be missing to add up to 54.4% ” that the most energy-hungry operations are packing/unpacking and quantization (39.3% of total system energy). Together these are responsible for 54.4% of the data movement energy.”
This PIM idea seem to be borne out by the 2015 research shown here https://twitter.com/daniel_bilar/status/620640582243909632
Smartphone apps 65%-75% energy spend on ads. 20-65% savings possible optimizing I/O
Thanks and have a great day
Everything old is new again.
Remember when graphics processing was moved off-CPU because it was too-expensive? Now we’ve got PIMs because moving the data is too expensive.
I predict there will be new android hardware released with PIM support within 6 months.
I think RFC1925, item 6 is applicable here:
(6) It is easier to move a problem around (for example, by moving the problem to a different part of the overall [network] architecture) than it is to solve it.
(6a) (corollary). It is always possible to add another level of
indirection.