Anna: A KVS for any scale Wu et al., ICDE’18
This work comes out of the RISE project at Berkeley, and regular readers of The Morning Paper will be familiar with much of the background. Here’s how Joe Hellerstein puts it in his blog post introducing the work:
As researchers, we asked the counter-cultural question: what would it take to build a key-value store that would excel across many orders of magnitude of scale, from a single multicore box to the global cloud? Turns out this kind of curiosity can lead to a system with pretty interesting practical implications. The key design point for answering our question centered on an ongoing theme in my research group over the last many years: designing distributed systems that avoid coordination. We’ve developed fundamental theory (the CALM Theorem), language design (Bloom), program checkers (Blazes), and transactional protocols (HATs, Invariant Confluence). But until now we hadn’t demonstrated the kind of performance and scale these principles can achieve across both multicore and cloud environments. Consider that domino fallen.
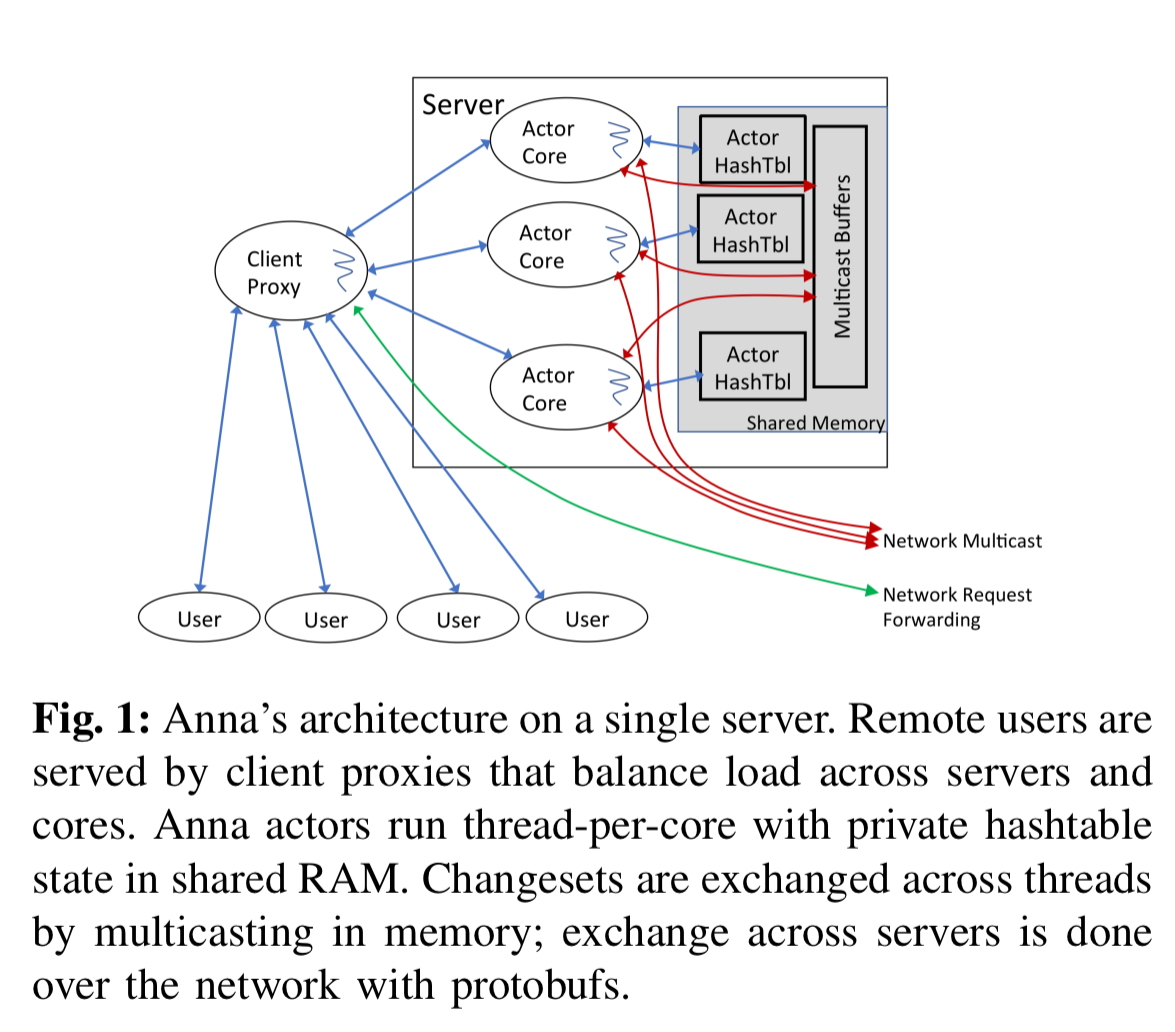
At it’s core Anna uses coordination-free actors. Each actor is a single thread of execution, and is mapped to a single core (see e.g. FFWD that we looked at recently). The coordination-free part comes from managing all state in lattice-based composite data structures (think Bloom and CRDTs). There is communication between actors that happens at the end of every epoch (epochs determine the limit of staleness for GET operations), but this is asynchronous gossip and not on the critical path of request handling.
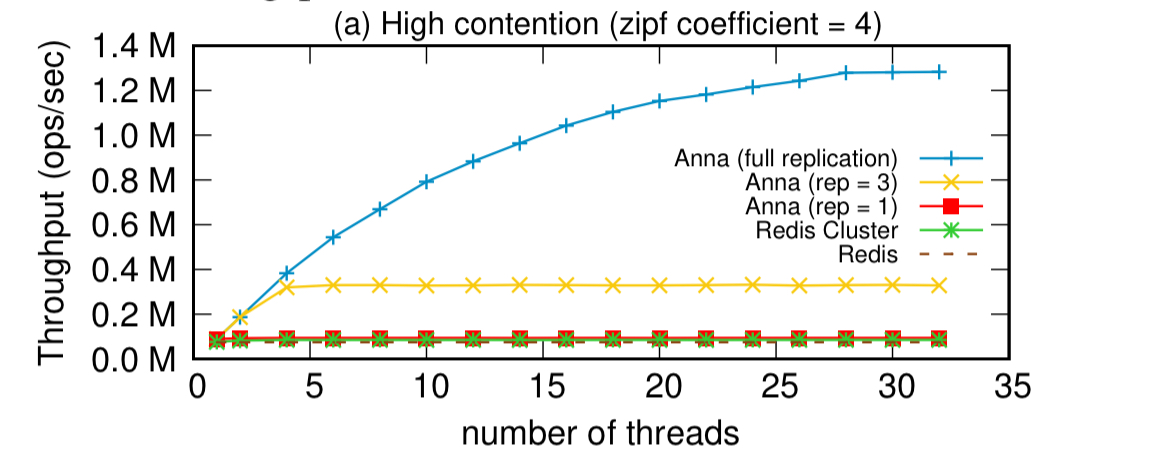
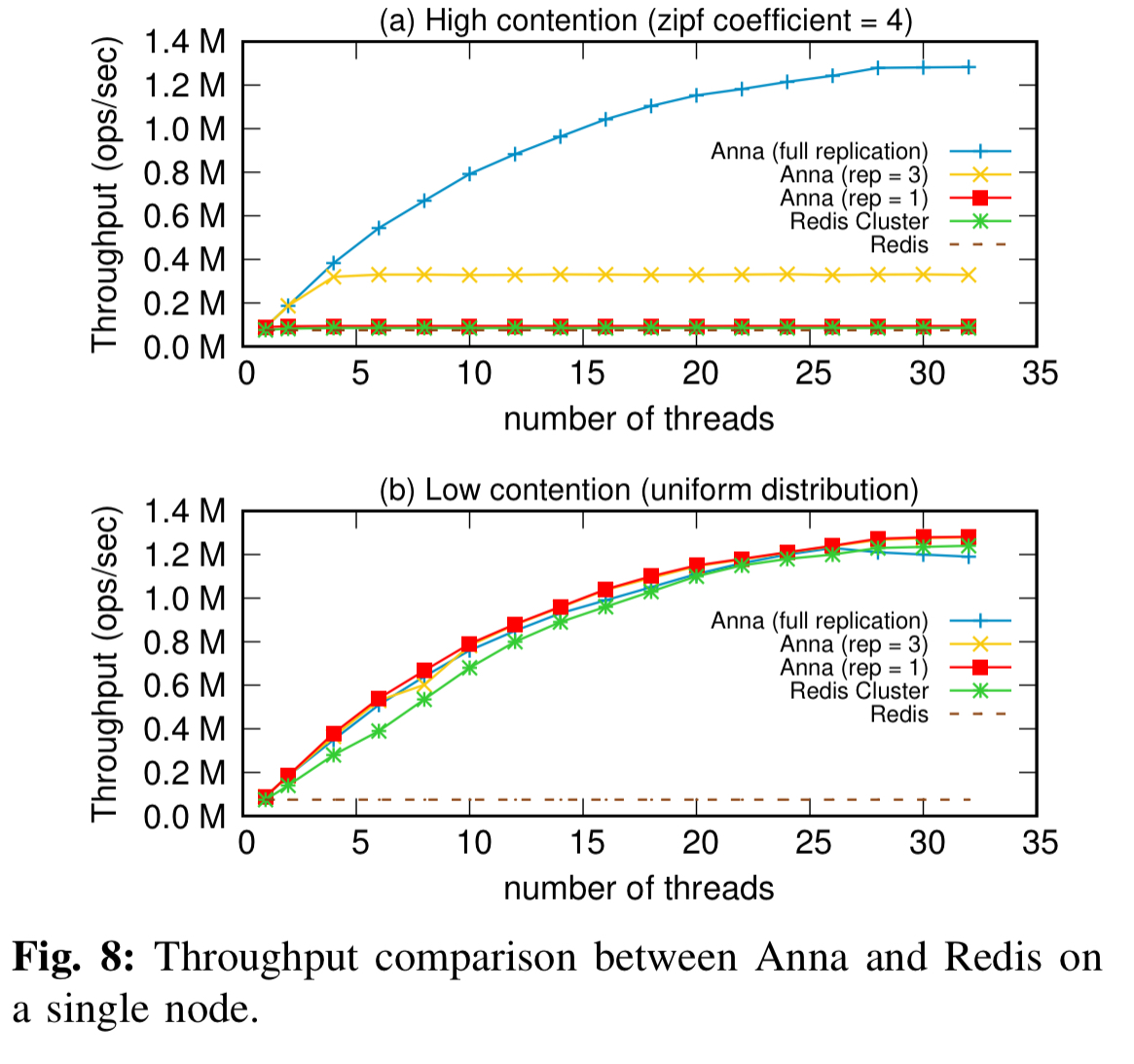
The success of the design in scaling across orders of magnitude is shown in the following results, where Anna outperforms Redis (and Redis Cluster) on a single node:
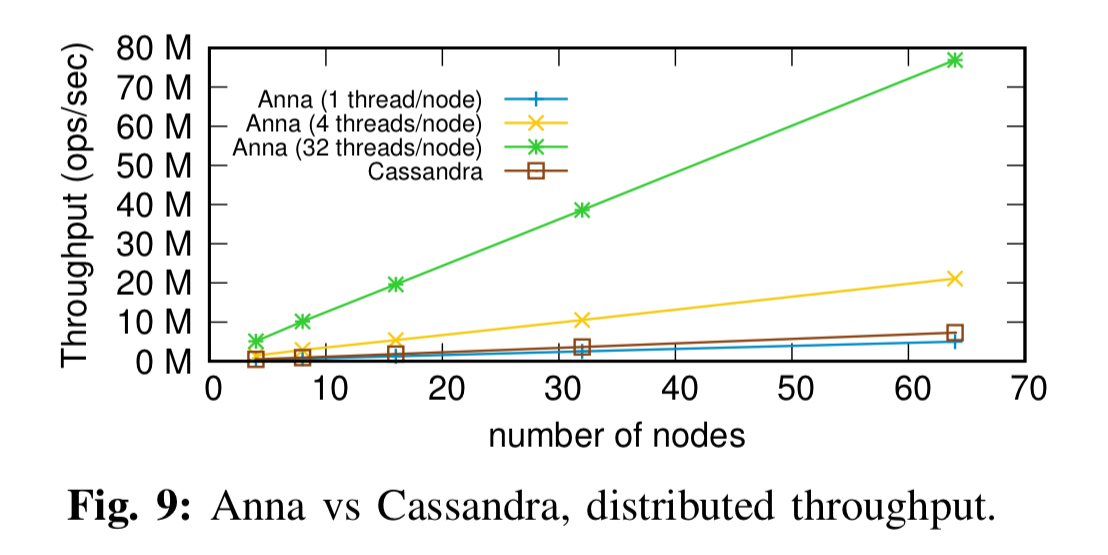
And also outperforms Cassandra in a distributed setting:
It’s got a way to go to trouble KV-Direct though ;).
Design goals for Anna
The high-level goal for Anna was to provide excellent performance on a single multi-core machine, while also being able to scale up elastically to geo-distributed cloud deployment. The system should support a range of consistency semantics to match application needs. From this, four design requirements emerged:
- The key space needs to be partitioned, not just across nodes when distributed, but also across cores within a node.
- To scale workloads (especially those with highly skewed distributions, aka. ‘hot keys’) the system should use multi-master replication to concurrently serve puts and gets against a single key from multiple threads.
- For maximum hardware utilisation and performance, the system should have wait-free execution such that a thread is never blocked on other threads. This rules out locking, consensus protocols, and even ‘lock-free’ retries.
- To support a wide-range of application semantics without compromising the other goals, the system should have a unified implementation for a wide range of coordination-free consistency models.
Perhaps the primary lesson of this work is that our scalability goals led us by necessity to good software engineering discipline.
Lattices
The key to achieving coordination-free progress is the use of lattice-based composition (strictly, bounded join semi-lattices). Such lattices operate over some domain S (the set of possible states), with a binary ‘least upper bound’ operator, 

> Lattices prove important to Anna for two reasons. First, lattices are insensitive to the order in which they merge updates. This means they can guarantee consistency across replicas even if the actors managing those replicas receive updates in different orders…. Second, simple lattice building blocks can be composed to achieve a range of coordination-free consistency levels.
Anna adopts the lattice composition approach of Bloom, in which simple lattice-based (ACI) building blocks such as counters, maps, and pairs can be composed into higher-order structures with ACI properties checkable by induction. If each building block has ACI properties, and the composition rules preserve ACI properties, then we can validate composed data structures without needing to directly verify them.
> The private state of each worker in Anna is represented as a lattice-valued map lattice (MapLattice) template, parameterized by the types of its keys and values…. User’s PUT requests are merged into the MapLattice. The merge operator of MapLattice takes the union of the key sets of both input hash maps. If a key appears in both inputs then the values associated with the key are merged using the ValueLattice’s merge function.
Different lattice compositions can be used to support different consistency levels. For example, the lattice below supports causal consistency. The vector clock is itself a MapLattice with client proxy ids as keys and version numbers as values.
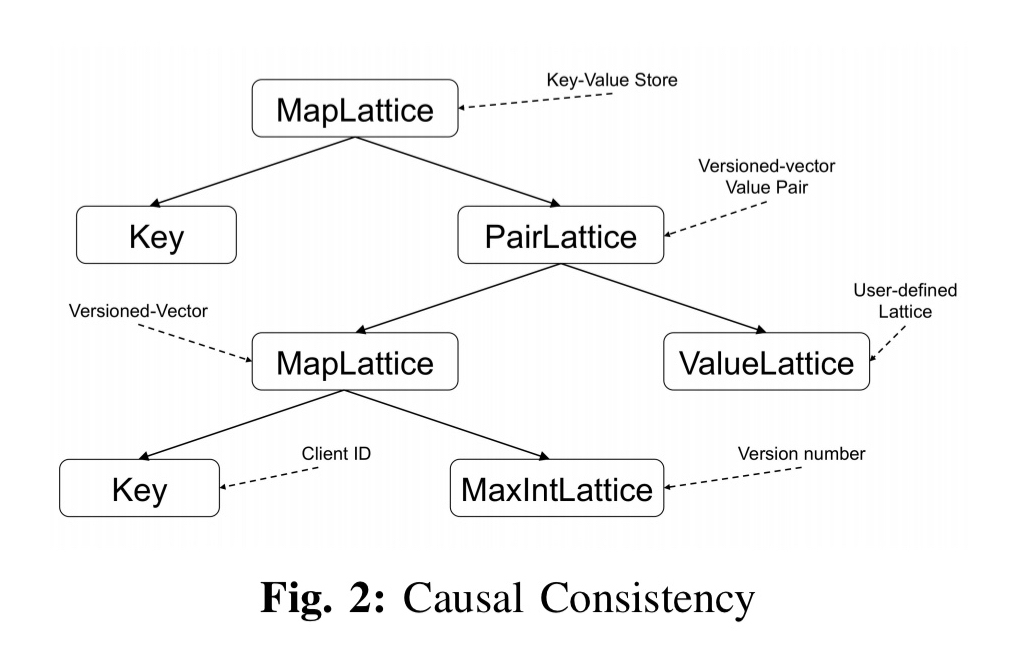
Merge operations take a (vector clock, value) pair and use the least upper bound function to merge incomparable concurrent writes.
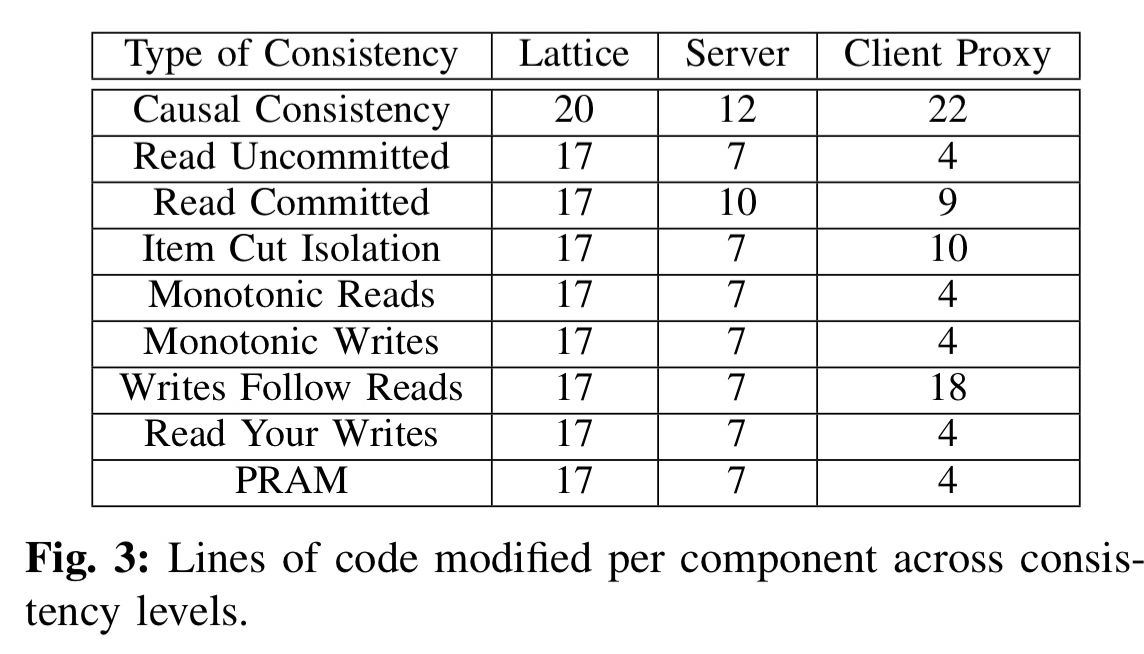
It takes only a very few lines of code to change the implementation to support other consistency models. Starting with simple eventual consistency, the following table shows the number of additional C++ loc needed to implement a variety of coordination-free consistency levels.
Design and implementation
On a given node, an Anna server consists of a collection of independent threads, each of which runs the coordination-free actor model. The state of each actor is maintained in a lattice-based data structure. Each actor/thread is pinned to a unique CPU core in a 1:1 correspondence. There is no shared key-value state: consistent hashing is used to partition the key space across actors. Multi-master replication is used to replicate data partitions across actors.
Processing happens in time-based multicast epochs (of e.g. 100ms). During an epoch any updates to a key-value pair owned by an actor are added to a local changeset. At the end of the epoch, local updates in the change set are merged using the merge operator of the lattice, and then multicast to the relevant masters for those keys. Actors also check for incoming multicast messages from other actors, and merge key-value updates from those into their own local state. The staleness of GET responses is bounded by the (configurable) multicast period.
Communication between actors is done using ZeroMQ. Within a node this will be via the intra-process transport, between it will be via protocol buffers over a tcp transport.
Actors may join and leave dynamically. See section VII.C in the paper for details.
The entire codebase, excluding third-party libraries such as ZeroMQ, but including the lattice library, support for all consistency levels, and the client proxy code, is around 2000 lines of C++.
Evaluation
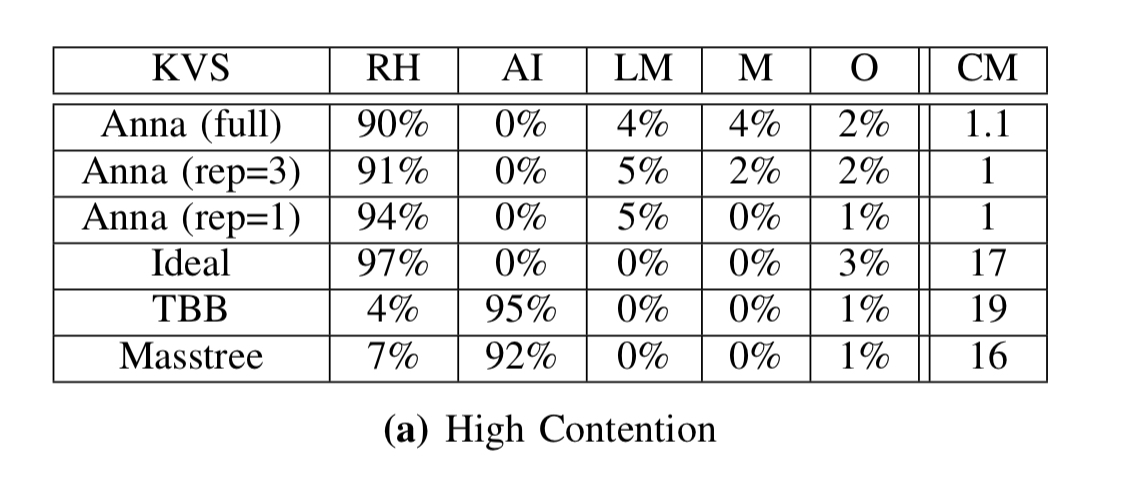
Starting with performance on a single node, Anna’s performance really shines under high-contention workloads when using full replication across all actors, and spends the vast majority of its time actually processing requests (as opposed to waiting).
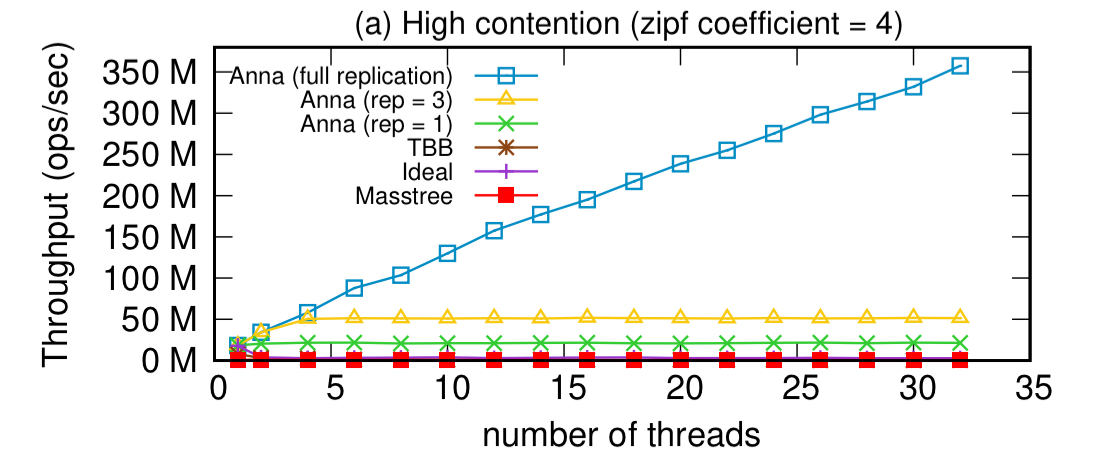
Under low contention workloads though, it’s much more efficient to use a lower replication factor (e.g., 3 masters per key):
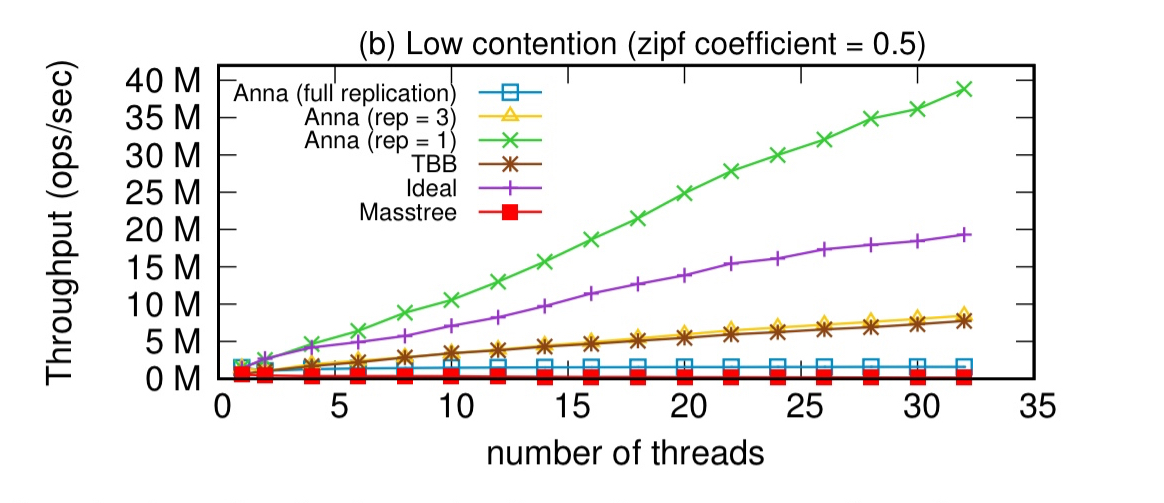
The lesson learned from this experiment is that for systems that support multi-master replication, having a high replication factor under low contention workloads can hurt performance. Instead, we want to dynamically monitor the data’s contention level and selectively replicate the highly contented keys across threads.
As another reference point, here’s the single node comparison to Redis under high and low contention workloads:
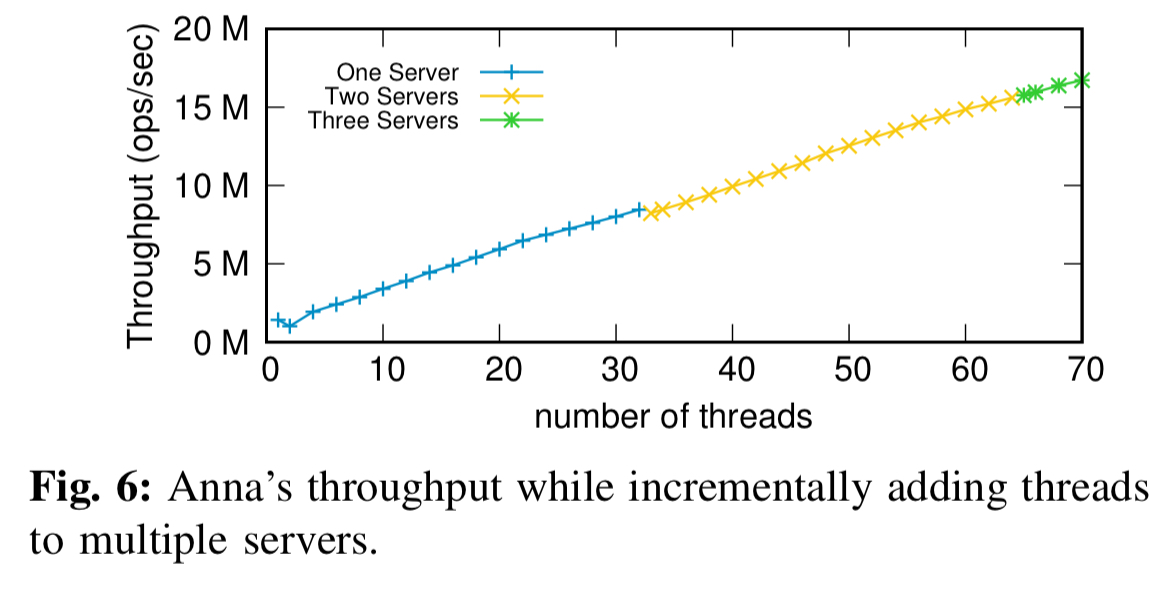
Anna scales well when adding threads across multiple servers (the slight drop at the 33rd thread in the chart below is because this is first thread residing on a second node, triggering distributed multicast across the network):
As we saw previously, in the distributed setting, Anna compares very favourably against Cassandra:
*
In summary:
- Anna can significantly outperform Redis Cluster by replicating hot keys under high contention.
- Anna can match the performance of Redis Cluster under low contention.
- Anna can outperform Cassandra by up to 10x when permitted to use all 32 available cores on each of its nodes.
The last word
I’m going to leave the last word to Joe Hellerstein, from his blog post:
Anna is a prototype and we learned a ton doing it. I think the lessons of what we did apply well beyond key-value databases to any distributed system that manages internal state—basically everything. We’re now actively working on an extended system, codename Bedrock, based on Anna. Bedrock will provide a hands-off, cost-effective version of this design in the cloud, which we’ll be open-sourcing and supporting more aggressively. Watch this space!

At it’s core Anna uses coordination-free actors. <– NO!
At its core Anna uses coordination-free actors. <– YES!!
Fix it! (I hate to hit this with a speling flam (sic) but the content is just too damn good to leave it!!!!)
Formula not rendering “($\perp(a,a) = a,\ \forall a \in S$)”?
Formula not rendering? ($\perp(a,a) = a,\ \forall a \in S$)