The dynamics of innocent flesh on the bone: code reuse ten years later van der Veen et al., CCS’17
It’s been ten years since the publication of “The geometry of innocent flesh on the bone,” the paper that introduce the notion of Return Oriented Programming and use of gadgets to craft exploits. In the intervening ten years, a variety of defences have been constructed, and also of course a number of ROP variations that seek to defeat those defences.
In practice, code-reuse attacks on a system with state-of-the-art defenses are extremely challenging. Such attacks require an attacker to analyse the protected program to find available defense-specific payloads that can be used to implement the desired malicious payload.
These attacks use static analysis to find available gadgets. In today’s paper, the authors introduce a dynamic approach to finding gadgets based on carefully observing a process as it executes. Newton is a run-time gadget-discovery framework based on constraint driven dynamic taint analysis that “can easily find function call gadgets even in the presence of state-of-the-art code-reuse defenses.”
A high-level overview of Newton
The Newton framework pushes the victim binary and its shared libraries through a pipeline of (1) static analysis, and (2) dynamic analysis — on top of a dynamic taint analysis (DTA) engine. During both phases, the target and write constraint managers apply user-defined constraints to the analysis, eventually yielding a list of callsites an attacker can control and, for each callsite, a list of callees an attacker can target under a given defense (or combination of defenses) regime.
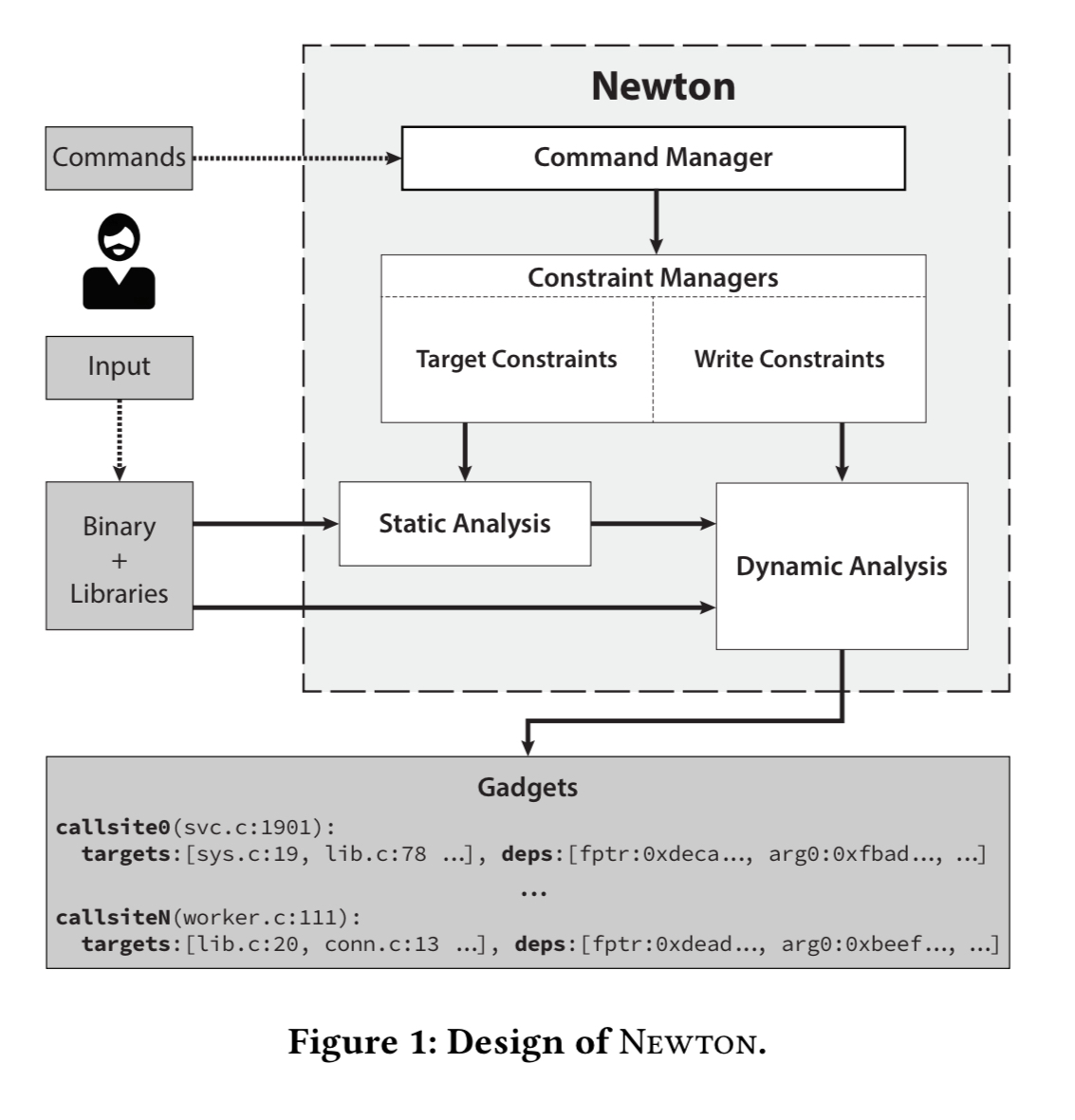
Suppose we want to attack a server application, such as nginx. The nginx process is started, and we wait for it to finish initialisation and sit waiting on a socket for connections. Newton is configured by passing it a script that tells Newton which set of rules (constraints) to follow when looking for gadgets. There are two types of constraints:
- Write constraints specify what Newton should assume about the attacker’s ability to corrupt writable memory. With no write constraints specified, Newton assumes an attacker can corrupt anything: function pointers, data pointers, and non-pointer values such as integers or strings.
- Target constraints specify what Newton should assume about the attacker’s ability to select callees of a controlled callset. With no additional constraints beyond the baseline the target set consists of all functions in the program and library code.
As we’ll see soon, different combinations of write and target constraints can be used to model a variety of defenses against code reuse attacks that may be encountered in the wild.
With Newton configured and the victim process in a quiescent state, we tell Newton to begin tracking user controlled memory dependencies using the DTA engine. Next the attacker sends a command to the process being analysed, using the inputs they intend to use during the final exploit (for example, making a GET request).
While the server processes the request as normal, Newton is performing its DTA in the background. Attacker controlled memory is initially modelled by marking regions under the attackers control (for example, the URL from the GET request) as tainted. Each byte in memory is associated with a unique tag, such that attacker controlled memory dependencies can be tracked at byte granularity.
Our dynamic taint analysis engine is capable of tracking the taint source address for each tainted value or pointer in memory. For each tainted byte, this tells us exactly by which memory addresses it was tainted. This allows us to track, when a tainted callsite is discovered, where the taint originated for the associated function pointer and each of the arguments. The source of the taint is then a candidate value for the attacker to corrupt, to control the callsite and mount a code-reuse attack.
Dynamic analysis is also used to scan user-defined ranges of writable memory for code pointers. Live code pages are those pointed to by pointers in live data memory that can potentially be leaked and overwritten.
Once the sample request(s) have been traced, the user can issue the ‘get-gadgets’ command to Newton, which will return a set of gadgets (callsites and targets) that are under the user’s control given the chosen defense model, initial quiescent state, and the set of server interactions. And as they say, “it’s all downhill from there!”
Modelling (and overcoming) code reuse defences in Newton
Newton can model state-of-the-art code reuse defences, which the authors break down into four different categories:
- Control flow integrity (CFI) defences instrument indirect callsites to ensure that only legal targets allowed by the program control flow graph are permitted. Some CFI solutions use only static analysis, other use dynamic information such as history.
- Information hiding defences such as Address Space Layout Randomisation (ASLR) and eXecute-Only Memory (XoM) try to make the locations of gadgets unknown to an attacker.
- Re-randomisation defences re-randomise and invalidate information at runtime(ideally) before the attacker has a chance to use it and craft just-in-time code reuse attacks.
- Pointer integrity defences prevent attackers from tampering with code or data pointers. This can be encryption based, in which pointers are encrypted with per-pointer or address-dependent keys, or isolation based in which all code pointers are isolated in a protected safe region.
Section 3 in the paper describes these defense mechanisms in more detail, and section 8 (related work) describes the evolution of return-oriented programming attacks. Both are well worth reading if this topic is of interest to you.
For the proposed defences in the literature, the authors then show how a fairly small set of write constraints and target constraints can be used to model their effects. The mapping is shown in the following table:
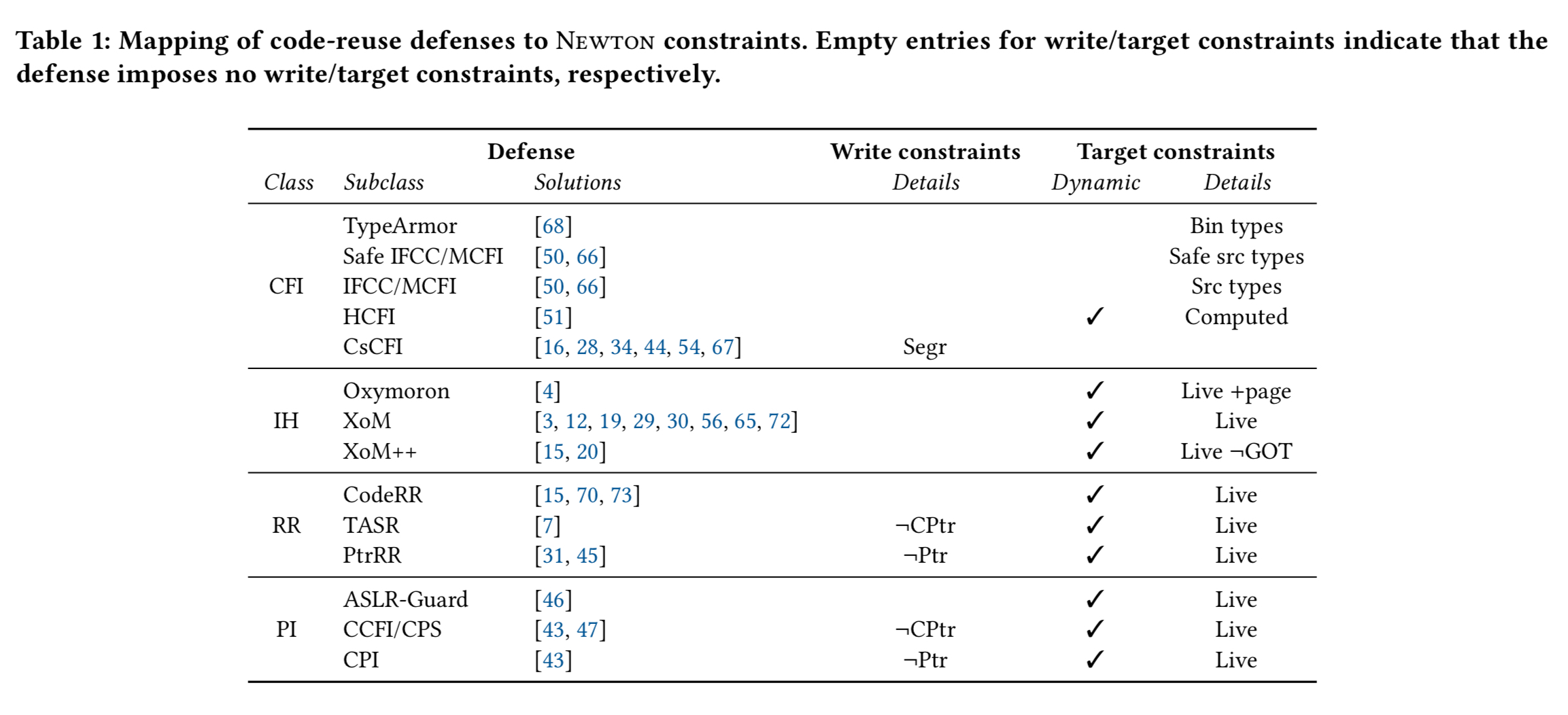
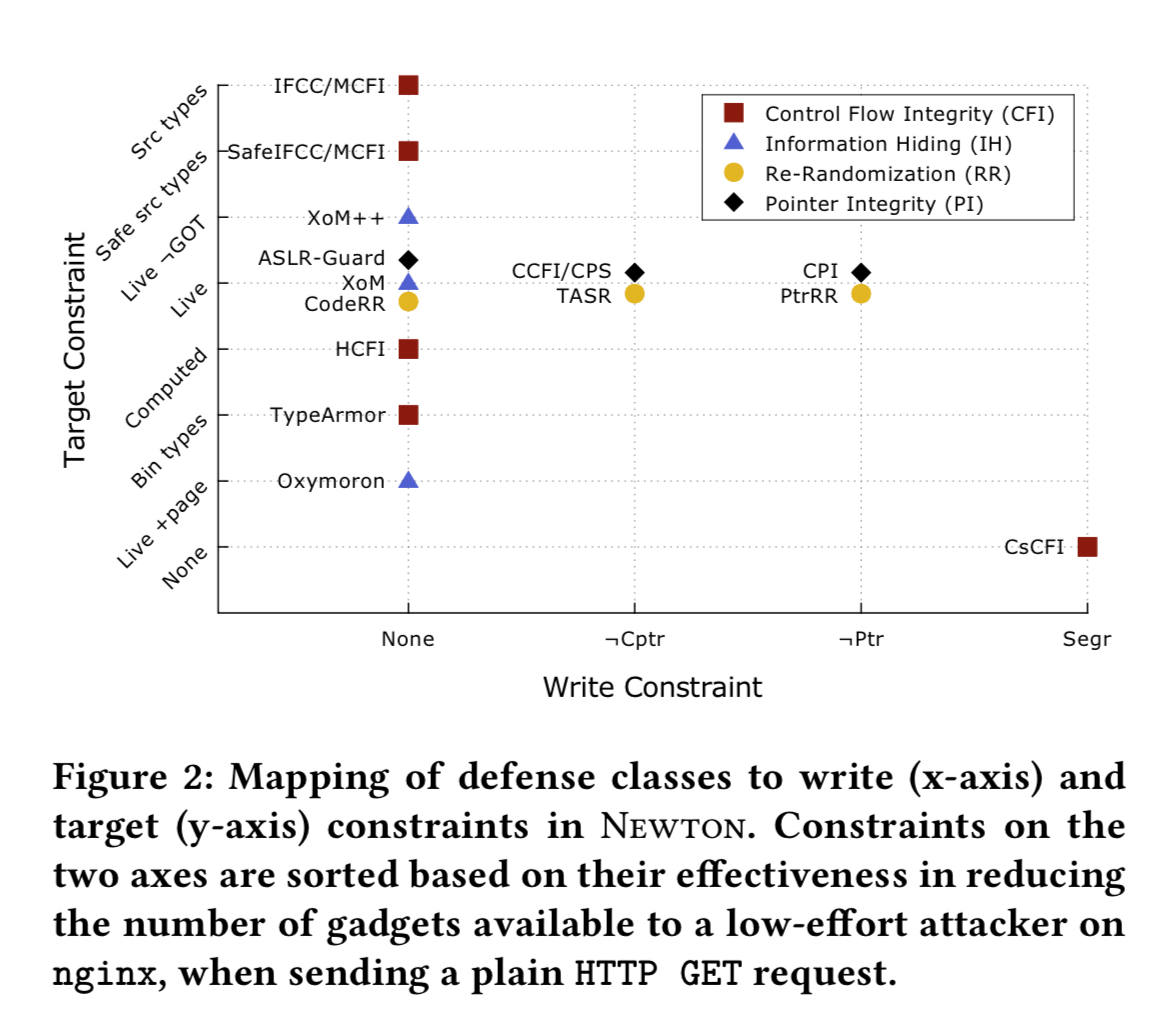
What this also reveals is that even defences that seem quite similar on the surface turn out to offer comparable guarantees.
Defenses that share both the same write and target constraints impose equivalent security restrictions, so that each (x,y) point in Figure 2 (below) forms an equivalence class.
Newton in action
Newton is evaluated against nginx, Apache and lighttpd, memchached, redis, and bind, with nginx being treated in the most depth in the paper.
Target constraints
The table below shows what the analysis finds when sending nginx a simple GET request, for different combinations of dynamic constraints. ‘Live’ indicates a constraint that limits targets to live code pointers, ‘Live +page’ limits targets to pages pointed to by live code pointers, ‘Live ¬GOT’ also eliminates code pointers in the Global Offset Table, and ‘computed’ restricts targets to those determined by code pointers computed during execution.
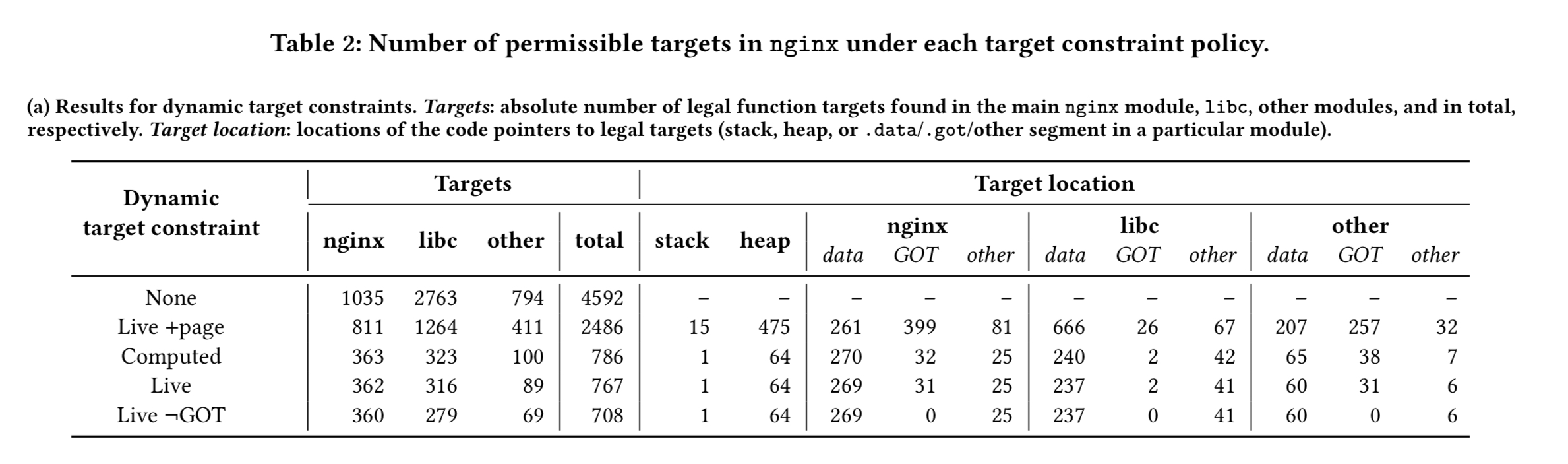
For example, looking at the computed row, we can see that after handling the GET request, 786 computed pointers reside in memory. Of these, 1 was stored on the stack and 64 on the heap. The remaining pointers originate from loaded modules: for example 270 in nginx’s data sections, 32 from its global offset tables, and 25 in the remaining sections and other modules.
We can also look at additional constraints discovered through static analysis. ‘Bin’ constraints come from analysing solely the program’s binary, ‘Safe src types’ come from source code analysis with some leeway for interchangeability between e.g., int * and void *, ‘Src’ constraints come from full analysis of the types in the source code.
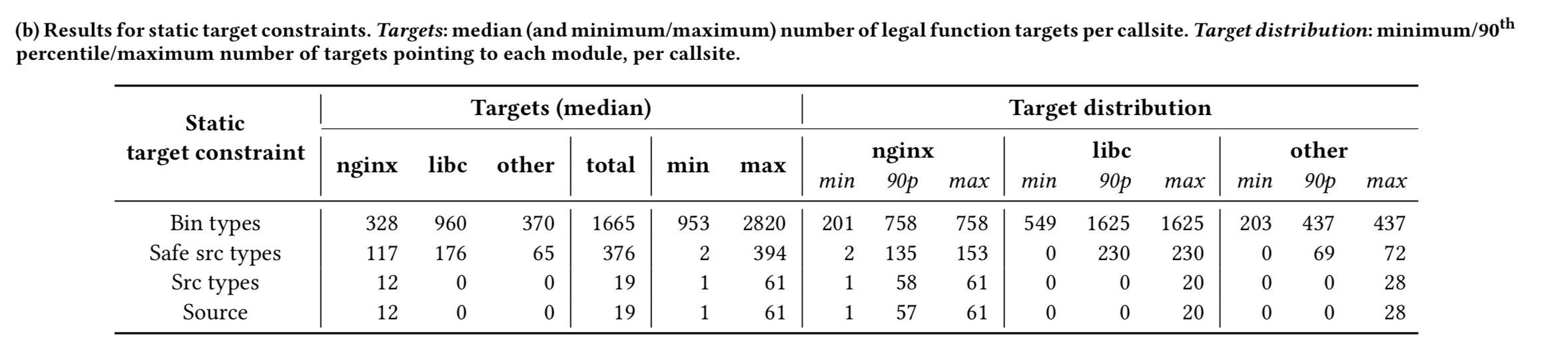
Overall, the main takeaway from (the above tables) is the ease with which our methodology allows us to compare the strength of even extremely different defense subclasses. For instance, it is clear that the strongest dynamic target constraint is ‘Live ¬GOT’, imposed by the XoM++ defense subclass…. It is also clear that static type-based constraints are in general stronger than dynamic ones.
Write constraints
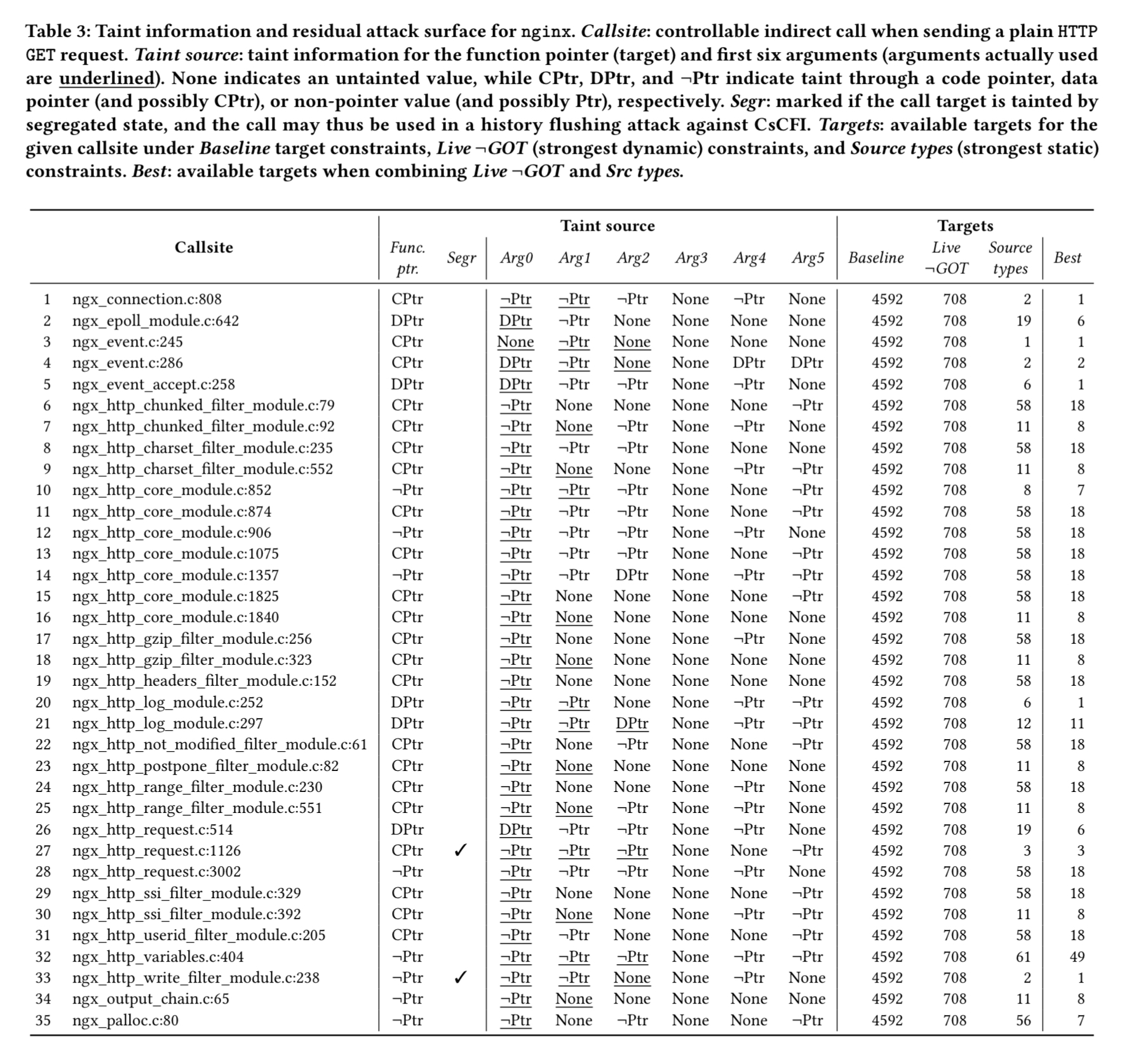
The following table shows the potential controllability of callsites in nginx given varying write constraints. 13 of the 35 callsites have a target tainted by a non-code pointer value, making them controllable even when code pointers are protected. 8 callsites are controllable under all write constraints imposed by current defences. Many of the callsites have a significant number of legal targets.
(Enlarge).
Results are similar for the other server processes investigated.
These results show that Newton is capable of locating controllable callsites and a choice of potential targets under even the strongest defenses. Recall that these results assume a low-effort attacker, sending only a single request to each server; thus, these results are a lower-bound for the number of controllable callsites.
An example attack
Callsite 33 from the table above is in the function ngx_http_write_filter, and it looks like this:
chain = c->send_chain(c, r->out, limit);
send_chain and c itself are controllable, and Newton also reports that the second r->out argument is tainted and controllable from corrupted connection-specific state. The third argument, limit, can also be controlled by controlling the limit_rate and limit_rate_after configuration variables. Execution continues correctly if the send_chain call is diverted to a different target returning a 0 value, so calls can be chained via repeated interactions with the server.
Newton also provides a list of 4592 possible targets for the selected callsite. “We target mprotect to escalate code reuse to a code corruption attack.” Once the mprotect call has succeeded, another request is issued to corrupt the libc gettimeofday function with the author’s own shellcode. When nginx processes the next request, it calls this function and the shellcode executes. End to end the attack looks like this:

(Enlarge)
There’s a video and expanded explanation on the VUsec website.
Using Newton, we found gadgets compatible with state-of-the-art defenses in many real-world programs… Our effort ultimately shows that, to sufficiently reduce the attack surface against a dynamic attack model, we must combine multiple state-of-the-art code-reuse defenses, or, alternatively deploy more heavyweight defenses at the cost of higher overhead.
Something like the Eigen-ROP defense for example would I believe still apply.

{kind=link}
{kind=link}
One thought on “The dynamics of innocent flesh on the bone: code reuse ten years later”
Comments are closed.