DéjàVu: A map of code duplicates on GitHub Lopes et al., OOPSLA ‘17
‘DéjàVu’ drew me in with its attention grabbing abstract:
This paper analyzes a corpus of 4.5 million non-fork projects hosted on GitHub representing over 482 million files written in Java, C++, Python, and JavaScript. We found that this corpus has a mere 85 million unique files.
That means there’s an 82% chance the file you’re looking at has a duplicate somewhere else in GitHub. My immediate thought is “that can’t possibly be right!” The results seem considerably less dramatic once you understand the dominant cause though.
The motivation for the study was to aid in selecting random samples of code bases to be used as the basis for other studies (it’s common in software engineering research to analyse projects on GitHub). What these results show is that simple random selection is likely to lead to samples including high duplication, which may bias the results of research. The clone map produced by the authors can be used to understand the similarity relations in samples of projects, or to curate sample to reduce duplicates. DéjàVu is a publicly available index of code duplication.
I’ll break the rest of this write-up into three sections – first let’s understand what the authors mean when they say “duplicate”, then we’ll look at the duplication findings, and finally we’ll get to the question of what’s causing there to be so much duplication in the first place.
Defining duplicate
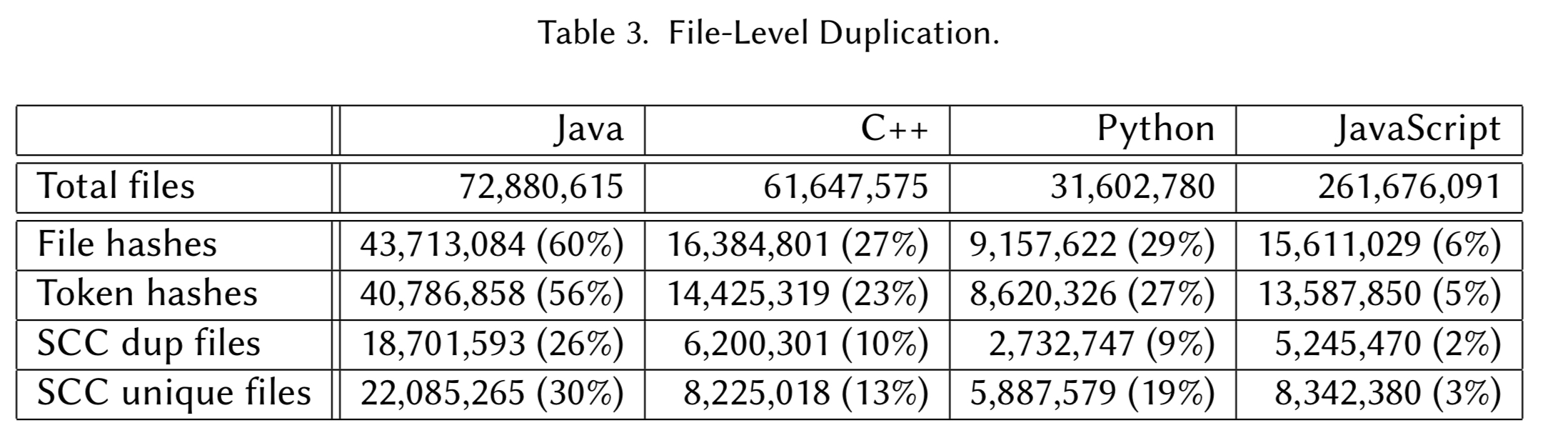
At the outset of this work, we were planning to study different granularities of duplication. As the results came in, the staggering rate of file-level duplication drove us to select three simple levels of similarity. A file hash gives a measure of files that are copied across projects without changes. A token hash captures minor changes in spaces, comments, and ordering. Lastly, SourcererCC captures files with 80% token similarity. This gives an idea of how many files have been edited after cloning.
To create the token hash all comments, white space and terminals are removed from the file, and then tokens are grouped by frequency. This results in strings such as “… (void, 2), (print, 2), (System, 1), …”. The token hash is an MD5 of the tokenized output string.
In addition to file-level duplication, the authors also look at project overlap – i.e. projects that contain some number of files in common. A statement “A is cloned in B at x%” means that x% of the files in project A can also be found in project B.
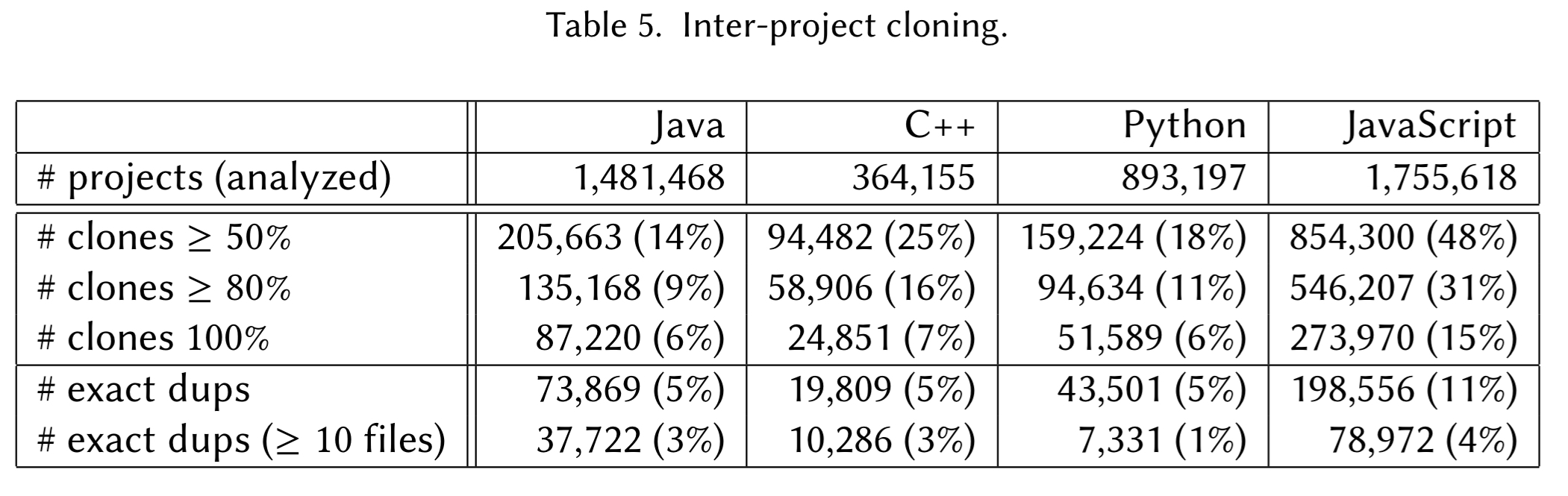
The authors look at projects in Java, C/C++, Python, and JavaScript, per the table below:
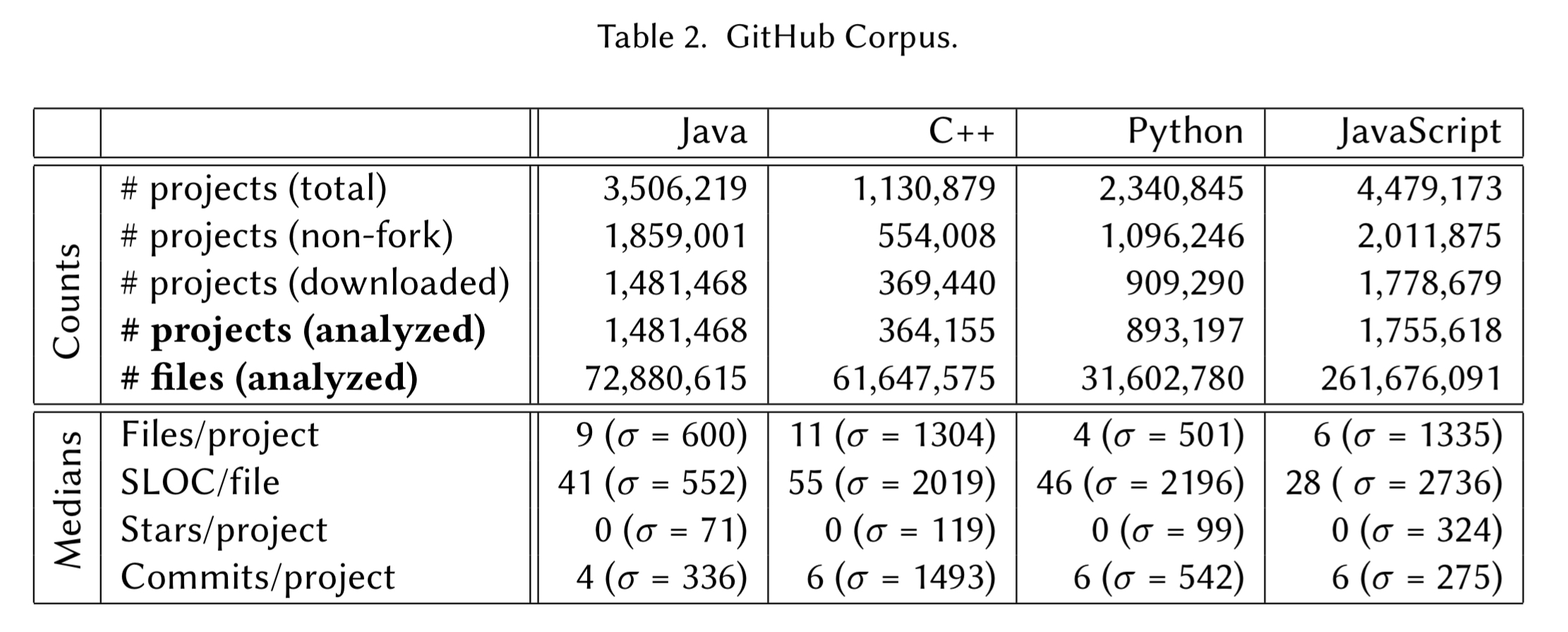
This excludes any projects which are forks (and hence we expect to contain duplication). The data shows a long tail of small (and not very active) projects – which is no great surprise. Python and JavaScript projects (especially when discounting files downloaded by NPM but then checked into source code control) tend to be smaller than Java and C/C++ projects.
What the analysis reveals
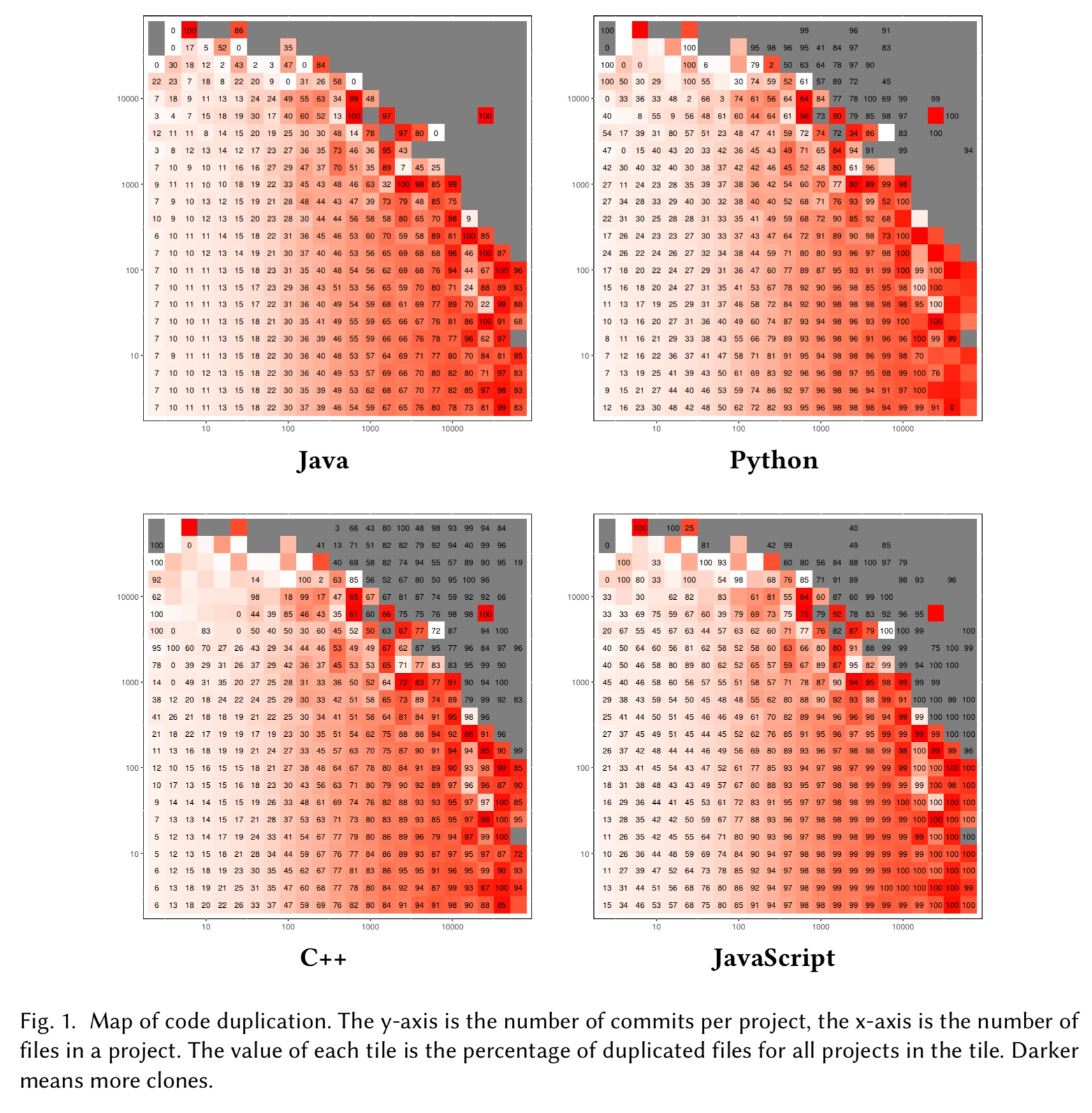
Looking across the whole corpus, the authors find the following levels of duplication:
The amount of duplication varies with the language: the JavaScript ecosystem contains the largest amount of duplication, with 94% of files being file-hash clones of the other 6%; the Java ecosystem contains the smallest amount, but even for Java, 40% of the files are duplicates; the C++ and Python ecosystems have 73% and 71% copies respectively. As for near-duplicates (SourcererCC), Java contains the largest percentage: 46% of files are near-duplicate clones.
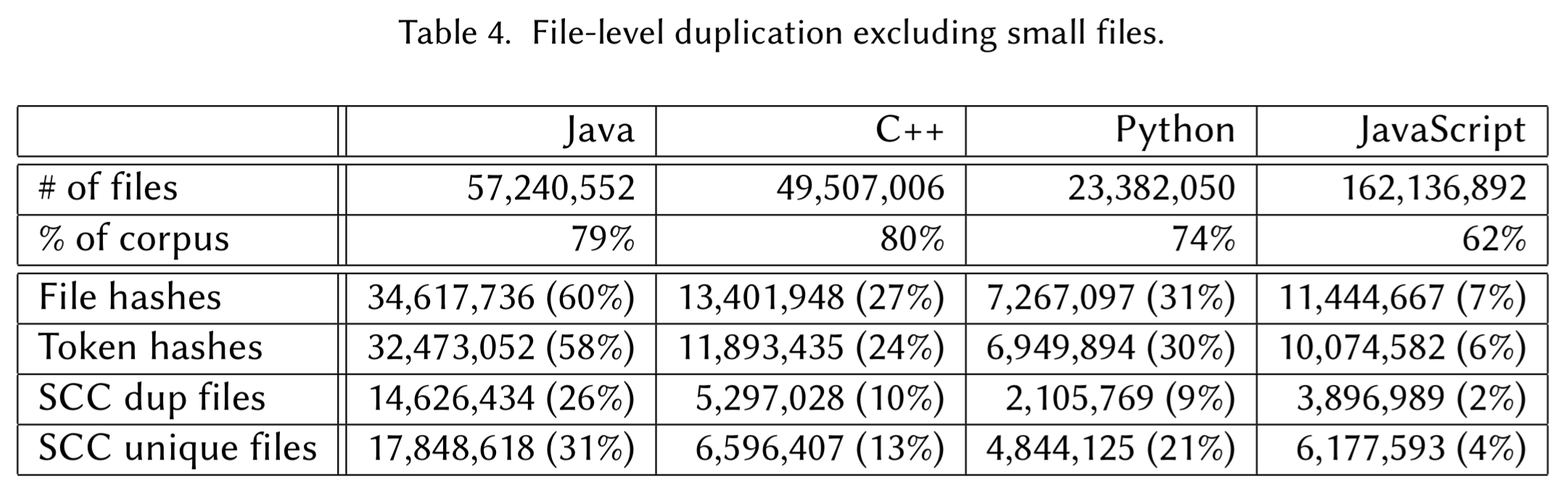
There’s one outlier we should probably remove straight away – the empty file with size 0 is duplicated 2.2M times! Another trivial file that is frequently duplicated is a file containing just 1 empty line. The authors redid the analysis, this time excluding small files with less than 50 tokens. This leaves us with the following picture when looking at a file level:
When we look at the project level, we find high levels of cloning between projects too:
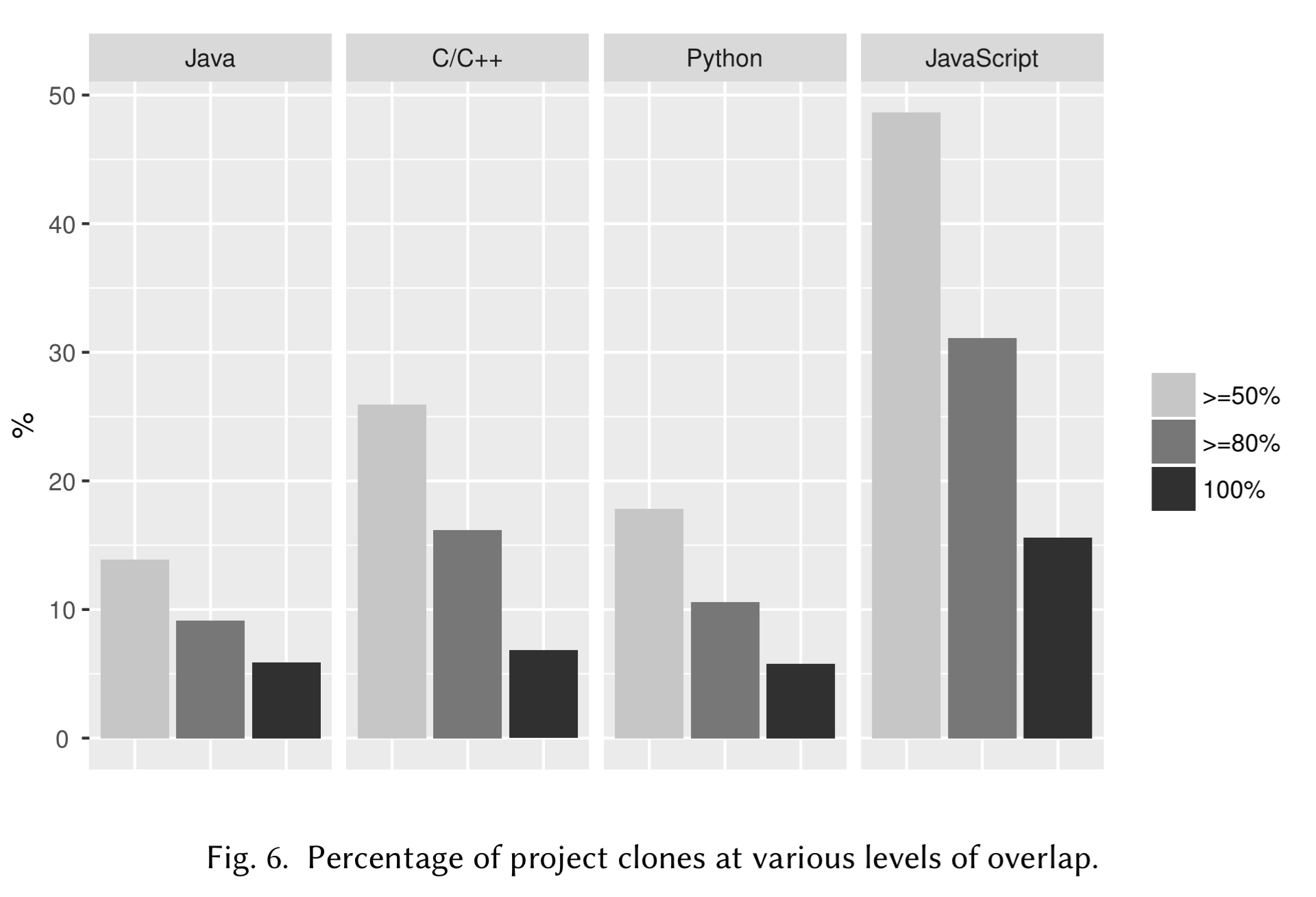
JavaScript comes on top with respect to the amount of project-level duplication, with 48% of projects having 50% or more files duplicated in some other project, and an equally impressive 15% of projects being 100% duplicated [and remember, there are no forks in the dataset].
Why so many duplicates?
The numbers presented in the previous section portray an image of GitHub not seen before. However, that quantitative analysis opens more questions. What files are being copied around, and why? What explains the differences between the language ecosystems? Why is the JavaScript ecosystem so much off the charts in terms of duplication?
The answers can be found in project dependencies, popular frameworks, and in code generation.
The reason the duplication level is so high for JavaScript turns out to be related to NPM: many projects are committing libraries available through NPM as if they are part of the application code. “This practice is the single biggest cause for the large duplication in JavaScript.” Even though only 6% of projects include their node\_modules directory, they are ultimately responsible for almost 70% of the entire files. If ever you have felt like you are downloading the universe when running npm install, here’s the data to prove it: including nested dependencies (nesting up to 47 levels deep was discovered, with median 5) the number of unique included projects has median 63, and maximum 1261.
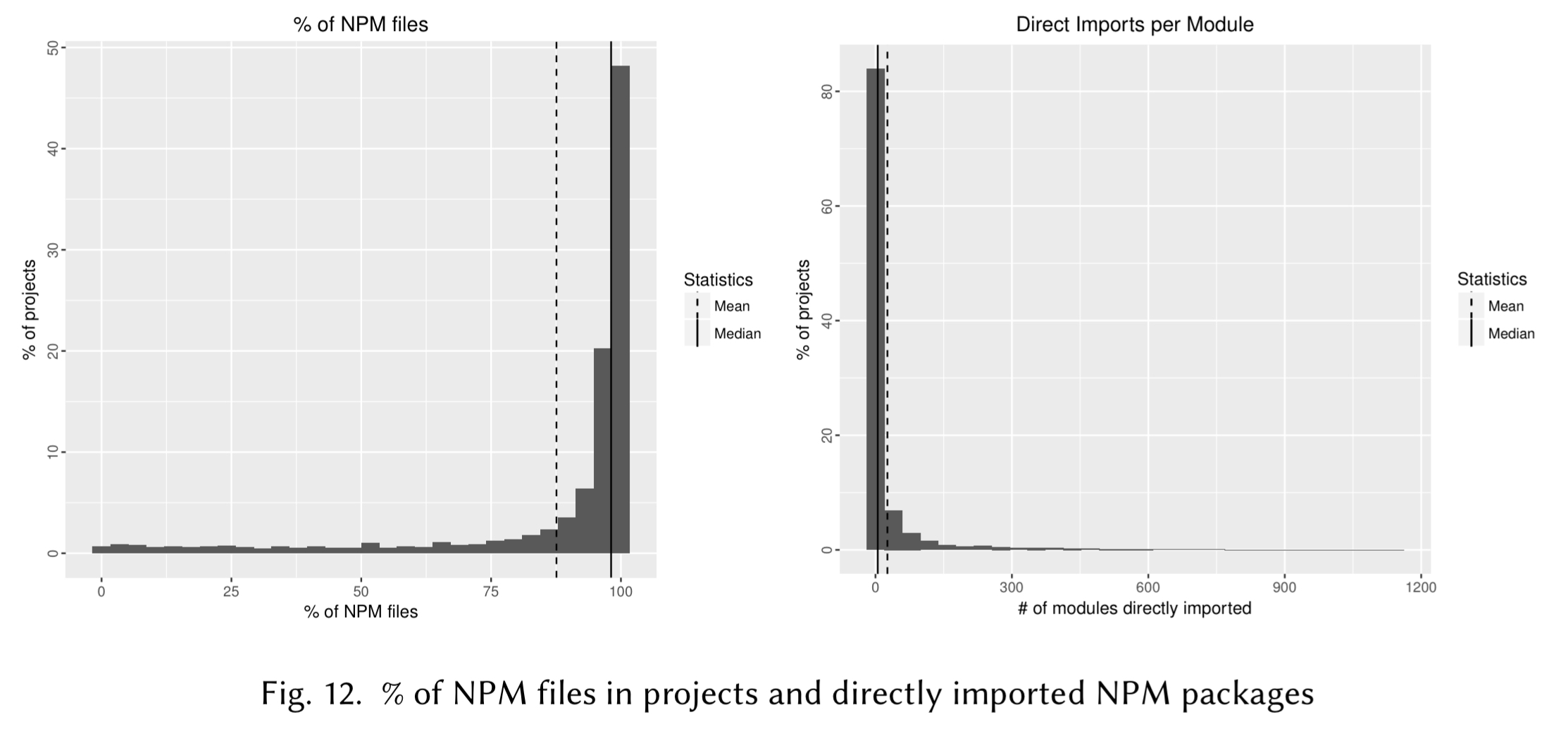
Some of the worst culprits are projects generated by the Angular Full Stack Generator, and by Yeoman.
Outside of NPM, popular libraries and frameworks are still widely duplicated. In Java the most common culprits are ActionBarSherlock and Cordova. In C/C++ it is boost and freetype. Outside of NPM, jQuery is most popular in the JavaScript world. Python seems to have greater diversity.
The presence of external libraries within the projects’ source code shows a form of dependency management that occurs across languages, namely, some dependencies are source-copied to the projects and committed to the projects repositories, independent of being installed through a package manager or not.
Investigating SourcererCC duplicates reveals another kind of cloning. 20 clone pairs were randomly selected for analysis and categorised into (i) intentional copy-paste clones, (ii) unintentional accidental clones, and (iii) auto-generated clones.
It is interesting to note that clones in categories ii) and iii) are both unavoidable and created because of the use of the popular frameworks.
The majority of the clone pairs fall into the auto-generated category – generated for example by Apache Axis, Android, and JAXB in the Java universe, Django in Python (django-admin startproject), and Angular and express project files in JavaScript. If you’re doing a lot of generation for your own projects, you might want to check out what Atomist are doing (‘Turn any repo into a software factory’).
The source control system upon which GitHub is built, Git, encourages forking projects and independent development of those forks… However, there is a lot more duplication of code that happens in GitHub that does not go through the fork mechanism, and instead, goes in via copy and paste of files and even entire libraries.
So there you have it, GitHub is full of cloned dependencies and auto-generated code. But you know what, I think that’s a pretty fair reflection of many modern software development projects – project starters are pretty common, and we’re nearly always building on top of a huge pile of dependencies. The percentage of truly unique code that we write in any one project probably is pretty tiny when you count all that. You may still be wondering what’s going on with those JavaScript projects and npm at 94% duplication. Prior to 2015, the official advice from npm was to check dependencies into your source code control system. Why? See e.g. ‘The NPM debacle was partly your fault (and here’s what you can do about it).’ Short version – npm was designed to be used in your development environment, but not as part of your deployment process. That advice changed in 2015 with the introduction of npm shrinkwrap, but this is not without it’s own challenges. A compromise is to make a dedicated node_modules repository and commit that into git, see for example ‘My node_modules are in git again.’ A quick search on GitHub still shows plenty of node_modules commit activity as of the time of writing.

Interesting. Do you have statistics for the split between categories i, ii and iii?
Come on, you could at least link to a non-paywalled pdf, e.g., one of the author’s website: http//:janvitek.org/pubs/oopsla17b.pdf
Github use a deduplicating filesystem, so they don’t care about the duplicates.
It’s marked as Open Access on the ACM DL site, so hopefully everyone should be able to access from there. But if anyone does have trouble, see Derek’s link in the parent.
The last paragraph is missing the latest (~2yrs) advancements on the Yarn CLI and the npm CLI: the opt-in shrinkwrap is now deprecated in favour of an automated opt-out lockfile.
Many languages, such as golang, encourage vendoring of code. Thus code duplication is a feature, not a bug in these environments.
Any reason why md5 was chosen over sha256/sha3. I’m especially curious due to the sample size and md5 having known collisions.
Just curious why md5 was chosen based on it’s history of collisions when sha256/sha3 are available. If it was a time/space issue, that’s cool, just curious on the reasoning.