Dynamic routing between capsules Sabour et al., NIPS’17
The Morning Paper isn’t trying to be a ‘breaking news’ site (there are plenty of those already!) — we covered a paper from 1950 last month for example! That said, when exciting research news breaks, of course I’m interested to read up on it. So The Morning Paper tends to be a little late to the party, but in compensation I hope to cover the material in a little more depth than the popular press. Recently there’s been some big excitement around Geoff Hinton’s work on capsules (and let’s not forget the co-authors, Sabour & Frosst), AlphaZero playing Go against itself, and Scharwtz-Ziv & Tishby’s information bottleneck theory of deep neural networks. This week I’ll be doing my best to understand those papers, and share with you what I can.
There are two capsule-related papers from Hinton. The first of them is from NIPS’17, and it’s today’s paper choice: ‘Dynamic routing between capsules.’ Some of the ideas in this paper are superseded by the ICLR’18 submission ‘Matrix capsules with EM routing’ that we’ll look at tomorrow, nevertheless, there’s important background information and results here. Strictly, we’re not supposed to know that the ICLR’18 submission is by Hinton and team – it’s a double blind review process. Clearly not working as designed in this case!
Exponential inefficiencies
For thirty years, the state-of-the-art in speech recognition used hidden Markov models with Gaussian mixtures, together with a one-of-n representation encoding.
The one-of-n representations that they use are exponentially inefficient compared with, say, a recurrent neural network that uses distributed representations.
Why exponentially ineffecient? To double the amount of information that an HMM (hidden Markov model) can remember we need to square the number of hidden nodes. For a recurrent net we only need to double the number of hidden neurons.
Now that convolutional neural networks have become the dominant approach to object recognition, it makes sense to ask whether there are any exponential inefficiencies that may lead to their demise. A good candidate is the difficulty that convolutional nets have in generalizing to novel viewpoints.
CNNs can deal with translation out of the box, but for robust recognition in the face of all other kinds of transformation we have two choices:
- Replicate feature detectors on a grid that grows exponentially with the number of dimensions, or
- Increase the size of the labelled training set in a similarly exponential way.
The big idea behind capsules (a new kind of building block for neural networks) is to efficiently encode viewpoint invariant knowledge in a way that generalises to novel viewpoints. To do this, capsules contain explicit transformation matrices.
Introducing Capsules
A network layer is divided into many small groups of neurons called “capsules.” Capsules are designed to support transformation-independent object recognition.
The activities of the neurons within an active capsule represent the various properties of a particular entity that is present in the image. These properties can include many different types of instantiation parameter such as pose (position, size, orientation), deformation, velocity, albedo, hue, texture, etc.. One very special property is the existence of the instantiated entity in the image.
(Albedo is a measure for reflectance or optical brightness of a surface – I had to look it up!).
The authors describe the role of the capsules as like ‘an inverted rendering process’ in a graphics pipeline. In a graphics pipeline for example we might start out with an abstract model of a 3D teapot. This will then be placed in the coordinate system of a 3D world, and the 3D world coordinate system will be translated to a 3D camera coordinate system with the camera at the origin. Then lighting and reflections are handled followed by a projection transformation into the 2D view of the camera. Capsules start with that 2D view as input and try to reverse the transformations to uncover the abstract model class (teapot) behind the image.
There are many possible ways to implement the general idea of capsules… In this paper we explore an interesting alternative which is to use the overall length of the vector of instantiation parameters to represent the existence of the entity and to force the orientation of the vector to represent the properties of the entity.
In 2D, the picture in my head looks something like this:
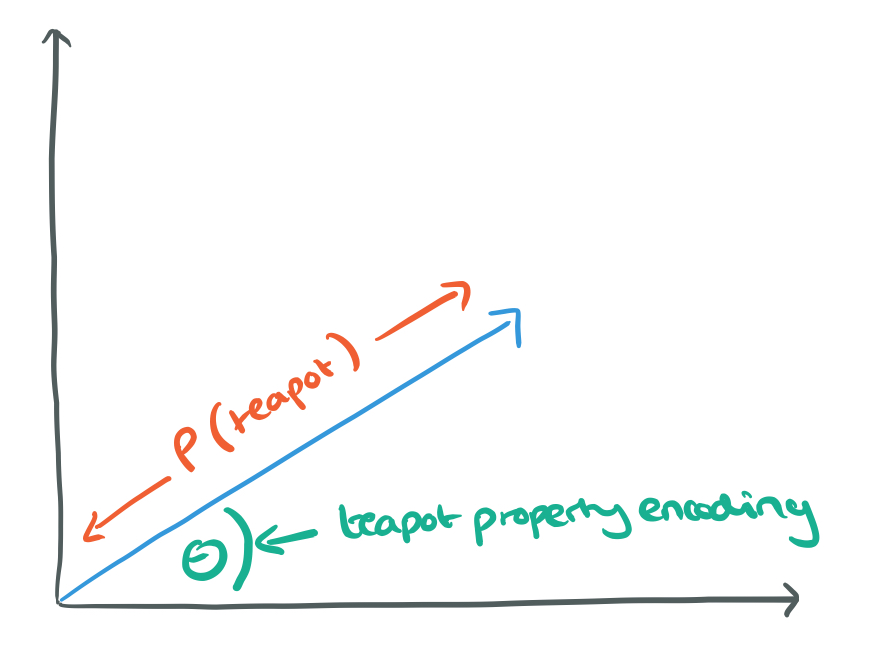
To turn the length of the vector into a probability we need to ensure that it cannot exceed one, which is done by applying a non-linear squashing function that leaves the orientation of the vector unchanged but scales down its magnitude.
For all but the first layer of capsules, the total input to a capsule
is a weighted sum over all “prediction vectors”
from the capsules in the layer below and is produced by multiplying the output
of a capsule in the layer below by a weight matrix


Where 
In convolutional capsule layers each unit in a capsule is a convolutional unit. Therefore, each capsule will output a grid of vectors rather than a single output vector.
Connecting capsules in layers
A Capsule Network, or CapsNet combines multiple capsule layers. For example, here’s a sample network for the MNIST handwritten digit recognition task:
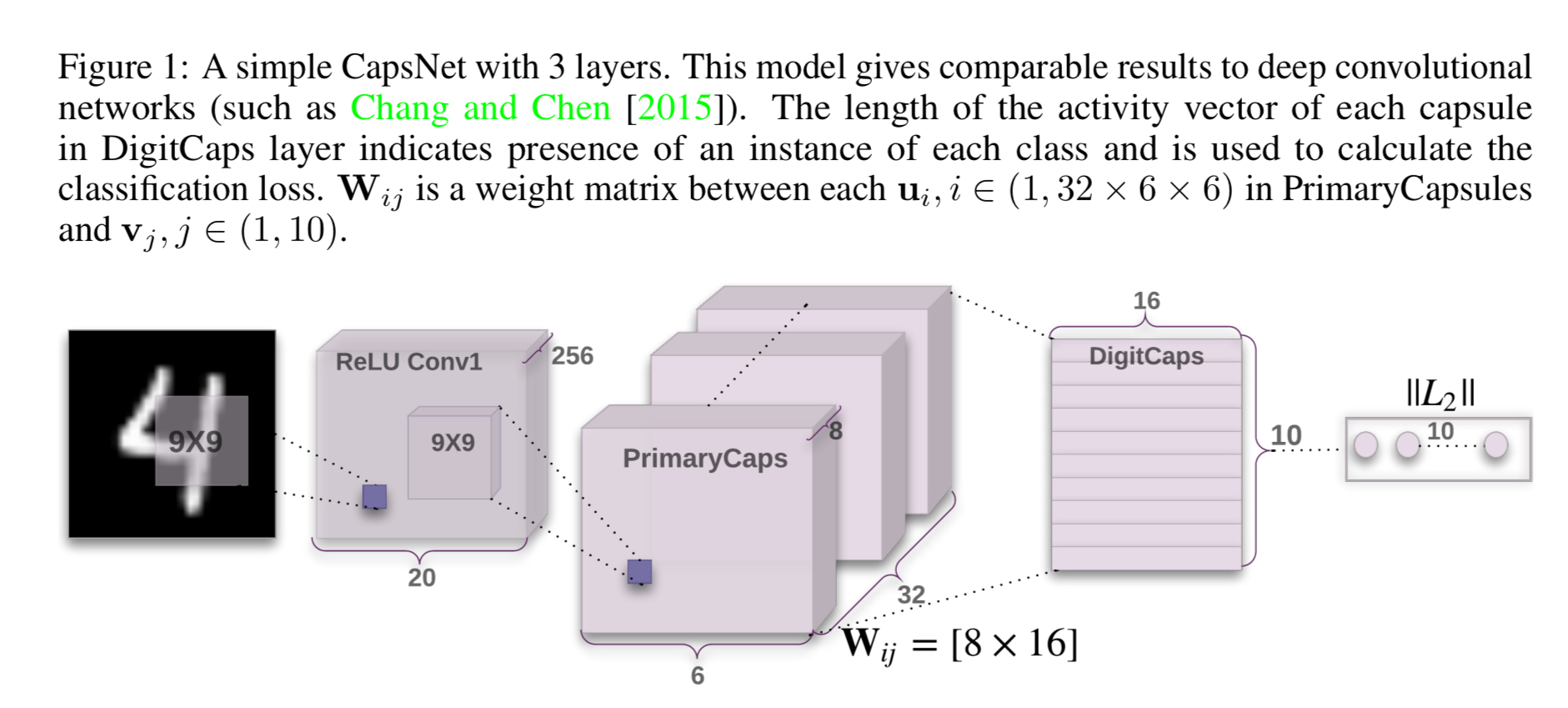
In general, the idea is to form a ‘parse tree’ of the scene. Layers are divided into capsules and capsules recognise parts of the scene. Active capsules in a layer from part of the parse tree, and each active capsule chooses a capsule in the layer above to be its parent in the tree.
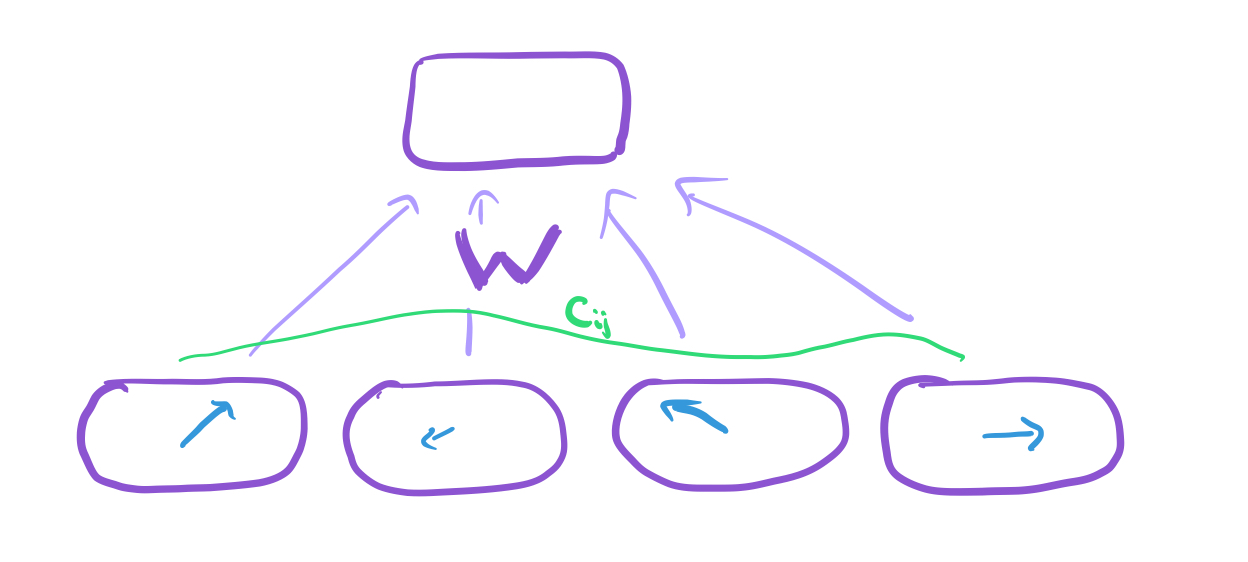
The fact that the output of a capsule is a vector makes it possible to use a powerful dynamic routing mechanism to ensure that the output of the capsule gets sent to an appropriate parent in the layer above.
- Initially the output is routed to all possible parents, but scaled down by coupling coefficients that sum to 1 (determined by a ‘routing softmax’).
- For each possible parent, the capsule computes a ‘prediction vector’ by multiplying its own output by a weight matrix.
- If the prediction vector has a large scalar product with the output of a possible parent, there is top-down feedback which has the effect of increasing the coupling coefficient for that parent, and decreasing it for other parents.
This type of “routing-by-agreement” should be far more effective than the very primitive form of routing implemented by max-pooling which allows neurons in one layer to ignore all but the most active feature detector in a local pool in the layer below.
To replicate knowledge across space, all but the last layer of capsules are convolutional.
In the final layer of the network (DigitCaps in the figure above) we want the top-level capsule for digit class 
Representations in MNIST
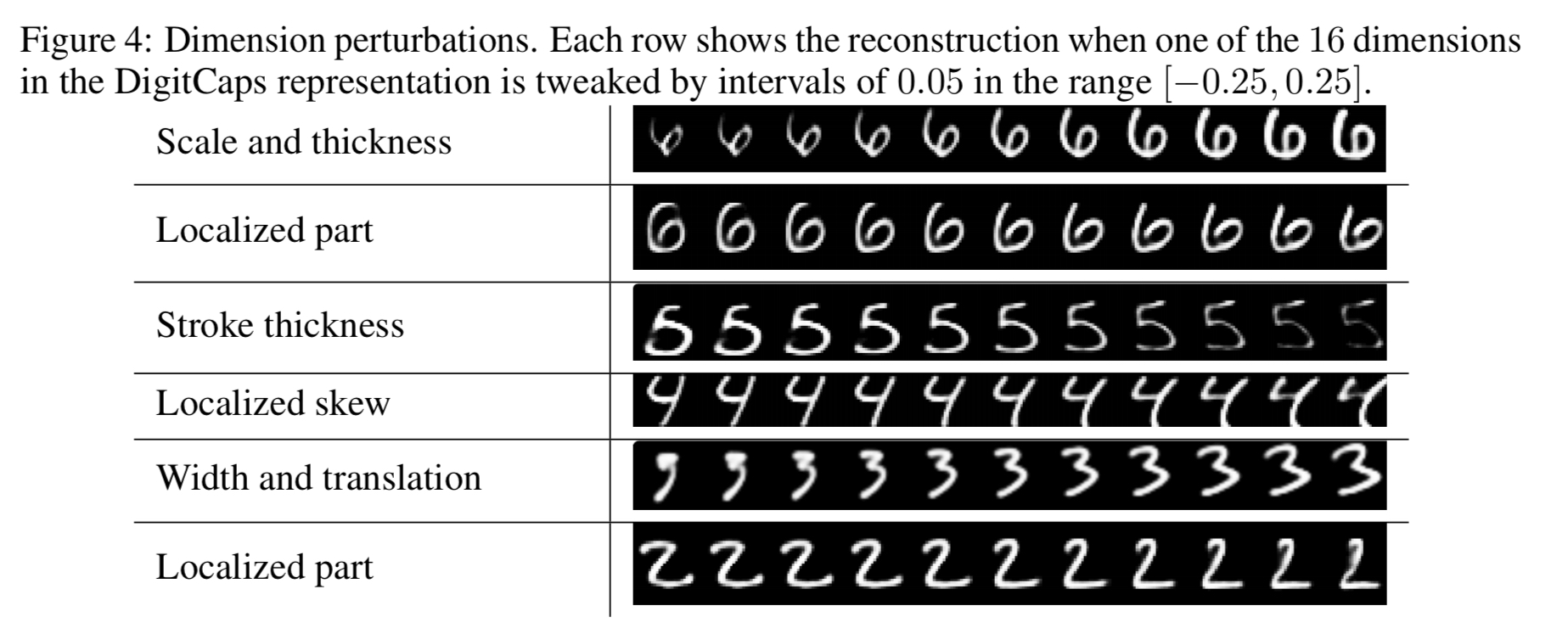
The CapsNet above is trained on MNIST, and then the capsules are probed by feeding perturbed versions of the activity vector into the decoder network to see how the perturbation affects the reconstruction.
Since we are passing the encoding of only one digit and zeroing out other digits, the dimensions of a digit capsule should learn to span the space of variations in the way digits of that class are instantiated. These variations include stroke thickness, skew and width. They also include digit-specific variations such as the length of the tail of a 2.
Here are some examples of the learned dimensions:
With a 3-layer network, CapsNet overall achieves a 0.25% test error – an accuracy previously only achieved by deeper networks.
To test the robustness of CapsNet to affine transformation, a CapsNet and traditional CNN were both trained on a padded and translated MNIST training set. The network was then tested on the affNIST data set, in which each example is an MNIST digit with a random small affine transformation. CapsNet and the traditional network achieved similar accuracy (99.23% vs 99.22%) on the expanded MNIST test set. CapsNet scored 79% on the affNIST test set though, handily beating the CNN’s score of 66%.
Segmentation
Dynamic routing can be viewed as a parallel attention mechanism that allows each capsule at one level to attend to some active capsules at the level below and to ignore others. This should allow the model to recognise multiple objects in the image even if objects overlap.
And indeed it does! A generated MultiMNIST training and test dataset is created by overlaying one digit on top of another with a shift of up to 4 pixels on each axis. CapsNet is correctly able to segment the image into the two original digits. The segmentation happens at a higher level than individual pixels, and so it can deal correctly with cases where a pixel is in both digits, while still accounting for all pixels.

A new beginning
Research on capsules is now at a similar stage to research on recurrent neural networks for speech recognition at the beginning of this century. There are fundamental representational reasons for believing it is a better approach but it probably requires a lot more insights before it can out-perform a highly developed technology. The fact that a simple capsules system already gives unparalleled performance at segmenting overlapping digits is an early indication that capsules are a direction worth exploring.
Xifeng Guo has a Keras implementation of CapsNet on GitHub which is helpful to study.

Can you comment on the “Replicate feature detectors on a grid that grows exponentially with the number of dimensions”? I didn’t quite get it.