Statistically rigorous Java performance evaluation Georges et al., OOPSLA’07
This paper won the 10-year most influential paper award at OOPSLA this year. Many of the papers we look at on this blog include some kind of performance evaluation. As Georges et al., show, without good experimental design and statistical rigour it can be hard to draw any firm conclusions, and worse you may reach misleading or incorrect conclusions! The paper is set in the context of Java performance evaluation, but the lessons apply much more broadly.
Benchmarking is at the heart of experimental computer science research and development… As such, it is absolutely crucial to have a rigorous benchmarking methodology. A non-rigorous methodology may skew the overall picture, and may even lead to incorrect conclusions. And this may drive research and development in a non-productive direction, or may lead to a non-optimal product brought to market.
A good benchmark needs a well chosen and well motivated experimental design. In addition, it needs a sound performance evaluation methodology.
… a performance evaluation methodology needs to adequately deal with the non-determinism in the experimental setup… Prevalent data analysis approaches for dealing with non-determinism are not statistically rigorous enough.
In the context of Java sources of non-determinism can include JIT compilation, thread scheduling, and garbage collection for example. For many benchmarks run today on cloud platforms, non-determinism in the underlying cloud platform can also be a significant factor.
Problems with performance evaluations
Common at the time of publication (it would be interesting to do a similar assessment of more recent papers) was a method whereby a number of performance runs – e.g. 30 – would be done, and the best performance number (smallest execution time) reported. This was in accordance with SPECjvm98 reporting rules for example. Here’s an example of doing this for five different garbage collectors.
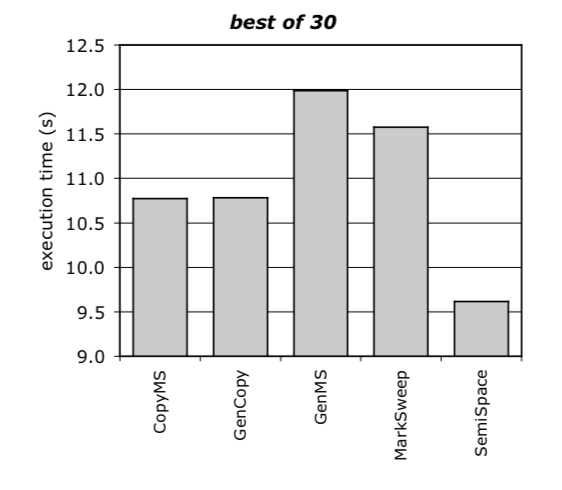
CopyMS and GenCopy seem to perform about the same, and SemiSpace clearly outperforms GenCopy.
Here are the same experiment results, but reported using a statistically rigorous method reporting 95% confidence intervals.
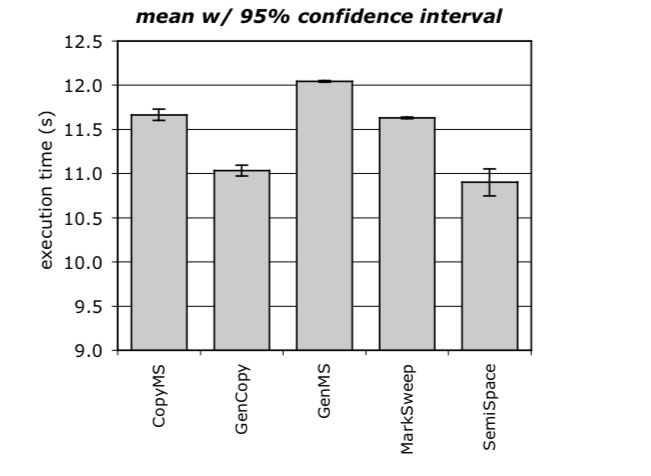
Now we see that GenCopy significantly outperforms CopyMS, and that SemiSpace and GenCopy have overlapping confidence intervals – the difference between them could be simply due to random performance variations in the system under measurement.
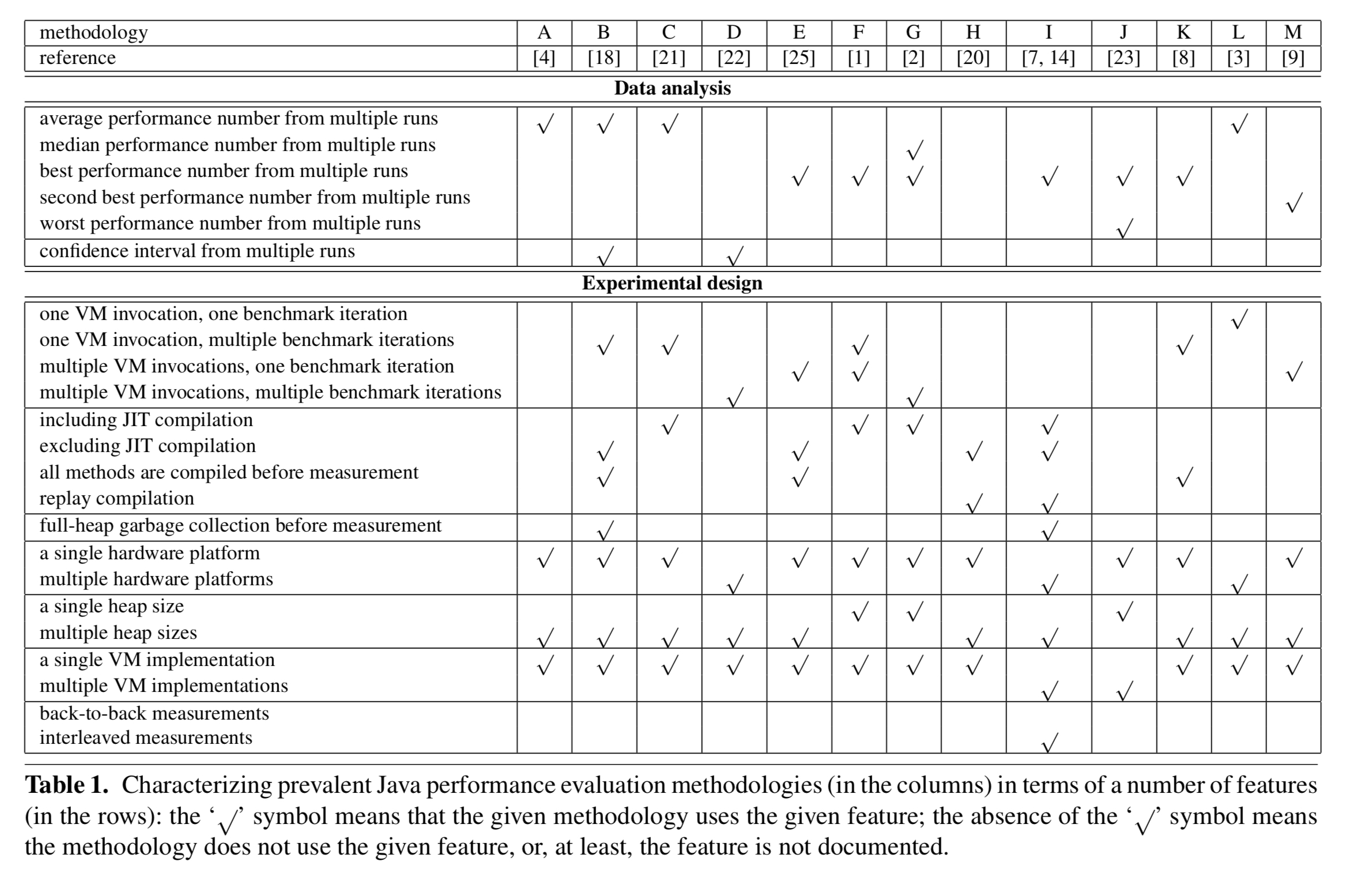
After surveying 50 Java performance papers the authors conclude that there is little consensus on what methodology to use. Table 1 below summarises some of the methodologies used in those papers:
Examples of misleading results
Suppose you use a non-rigorous methodology and report a single number such as best, average, worst etc., out of a set of runs. In a pairwise comparison, you might say there was a meaningful performance difference if the delta between the two systems was greater than some threshold 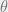
- overlapping intervals
- non-overlapping intervals, in the same order as the non-rigorous methodology
- non-overlapping intervals, in a different order to the non-rigorous methodology
This leads to six different cases – in only one of which can you truly rely on the results from the non-rigorous approach:

The authors run a series of tests and find that all prevalent methods can be misleading in a substantial fraction of comparisons between alternatives – up to 16%. Incorrect conclusions even occur in up to 3% of comparisons. (And if you really must report a single number, mean and median do better than best, second best, or worst).

There are many more examples in section 6 of the paper.
Statistics to the rescue
We advocate adding statistical rigor to performance evaluation studies of managed runtime system, and in particular Java systems. The motivation for statistically rigorous data analysis is that statistics, and in particular confidence intervals, enable one to determine whether differences observed in measurements are due to random fluctuations in the measurements or due to actual differences in the alternatives compared against each other.
Section 3 in the paper is my favourite part, and it essentially consists of a mini-stats tutorial for people doing benchmarks.
If we could get an exact repeatable number out of every performance run, life would be much more straightforward. Unfortunately we can’t do that due to non-determinism (‘random errors’) in the process. So we need to control for perturbing events unrelated to what the experiment is trying to measure. As a first step, the authors recommend discarding extreme outliers. With that done, we want to compute a confidence interval.
In each experiment, a number of samples is taken from an underlying population. A confidence interval for the mean derived from these samples then quantifies the range of values that have a given probability of including the actual population mean.
A confidence interval ![[c_1, c_2]](https://s0.wp.com/latex.php?latex=%5Bc_1%2C+c_2%5D&bg=eeeeee&fg=666666&s=0&c=20201002)

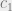
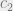



A 90% confidence interval means that there is a 90% probability that the actual distribution mean of the underlying population is within the confidence interval. For the same data, if we want to be more confident that the true mean lies within the interval, say a 95% confidence interval, then it follows that we would need to make the interval wider.
Ideally we would take at least 30 samples such that we can build upon the central limit theorem. With a target significance level
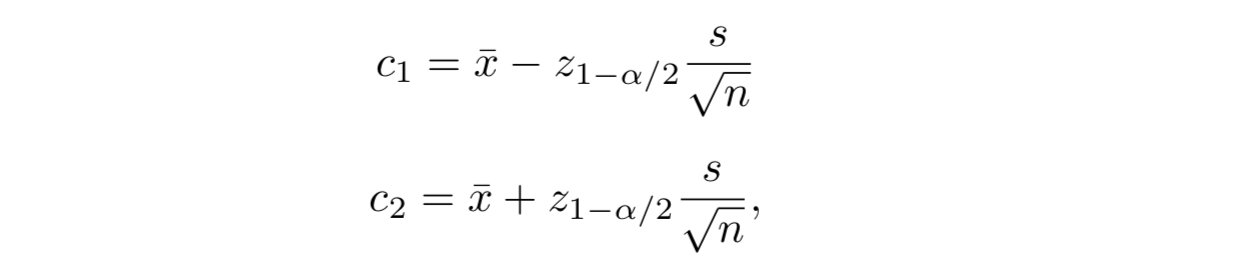
Where 


A basic assumption made in the above derivation is that the sample variance
provides a good estimate of the actual variance
… This is generally the case for experiments with a large number of samples, e.g.,
. However, for a relatively small number of samples, which is typically assumed to mean
, the sample variance
In this case, we can use Student’s t-distribution instead and compute the interval as:
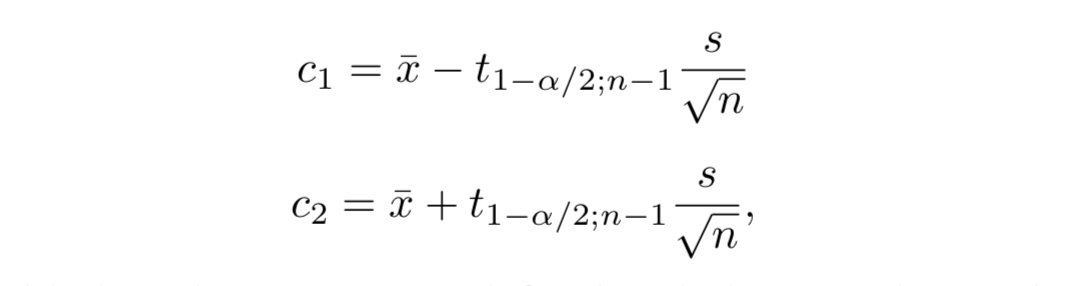
The value 

Comparing alternatives
Thus far we know how to compute confidence intervals for the mean of a single system. If we compare two system and their confidence intervals overlap, then we cannot conclude that the differences seen in the mean values are not due to random fluctuations in the measurements. If the confidence intervals do not overlap, we conclude that there is no evidence to suggest that there is not a statistically significant difference.
The paper shows the formula for computing a confidence interval for the difference of two means (see section 3.3). If this interval includes zero, we can conclude, at the confidence level chosen, that there is no statistically significant difference between the two alternatives.
If we want to compare more than two alternatives, then we can use a technique called Analysis of Variance (ANOVA).
ANOVA separates the total variation in a set of measurements into a component due to random fluctuations in the measurements and a component due to the actual differences among the alternatives… If the variation between the alternatives is larger than the variation within each alternative, then it can be concluded that there is a statistically significant difference between the alternatives.
The ANOVO test doesn’t tell which of the alternatives the statistically significant difference is between, if there is one! The Tukey HSD (Honestly Significantly Different) test can be used for this.
With ANOVA we can vary one input variable within an experiment. Multi-factor ANOVA enables you to study the effect of multiple input variables and all their interactions. Multivariate ANOVA (MANOVA) enables you to draw conclusions across multiple benchmarks.
Recommendations
Using the more complex analyses, such as multi-factor ANOVA and MANOVA, raises two concerns. First, their output is often non-intuitive and in many cases hard to understand without deep background in statistics. Second, as mentioned before, doing all the measurements required as input to the analyses can be very time-consuming up to the point where it becomes intractable.
Section 4 of the paper therefore introduces a practical yet still statistically rigorous set of recommendations for Java performance evaluation.
To measure start-up performance:
- Measure the execution time of multiple VM invocations, each running a single benchmark iteration.
- Discard the first VM invocation and retain only the subsequent measurements. This ensures libraries are leaded when doing the measurements.
- Compute the confidence interval for a given confidence level. If there are more than 30 measurements, use the standard normal
-statistic, otherwise use the Student
-statistic.
To measure steady-state performance:
- Consider
VM invocations, each invocation running at most
benchmark iterations. Suppose we want to retain
measurements per invocation.
- For each VM invocation
determine the iteration
where steady-state performance is reached, i.e., once the coefficient of variation (std deviation divided by the mean) of the
to
- For each VM invocation, compute the mean
of the
.
- Compute the confidence interval for a given confidence level across the computed means from the different VM invocations. The overall mean
, and the confidence interval is computed over the
We’ll be talking more about the notion of ‘steady-state’ tomorrow – especially with micro-benchmarks.
For more on critically reading evaluation sections in papers in general, see “The truth, the whole truth, and nothing but the truth: a pragmatic guide to assessing empirical evaluations.”

I’ll confess to the sin of not reading the paper (just your article), but… measuring mean+variance seems potentially more misleading than taking the lowest runtime! Now, it depends what you are measuring – true. But, technically speaking, if you benchmark your own algorithm, you should take the mode of the distribution, right? And, sure enough, in a programming language like C++ or Rust, the mode will trend towards the minimum, with enough experimentation.
Let me put it like this: the time to run the benchmark is something like X + E – where “X” is “useful time spent doing your computation” and “E” is the “error” – additional overhead of the system (because OS, cache misses, other systems running on the same box, various interrupts that just happened to fire, etc. etc). One critical observation here is that E is always positive! You don’ really get negative measurements errors. So, when you measure mean+variance, you’re not really measuring anything about the algorithm – you’re measuring the variance/ instability of your benchmark box. Which is probably going to be very bad in a cloud environment (since you mention it…)
I’m guessing that’s why SPECjvm98 said “take the minimum”. Now, I’ll grant you that: with the JVM, and depending on the algo, the measuring error might actually be negative. Because garbage collection happens in epochs – if you’re “lucky” enough to measure your performance between two garbage collection runs, you might actually “steal time” and get a negative error. This should be easily fixed though by taking the mode of the distribution (once you’ve done enough experimentation for it to stabilize). One way to know that this methodology is better is that it doesn’t require you to manually “fix” the data (e.g. by discarding extreme outliers).
The question I have is, what use is this measure of performance? What you call ‘error’ is actually overhead, and unavoidable in the sense that in any given run, you will see it to some degree. Taking the best of n runs has the property of becoming less realistic as n is increased.
I don’t think best-of-n is a even a good relative proxy for optimization: for one thing, the overhead is not necessarily independent of the changes you are making.
One other thing (though it may just reflect my ignorance): how do you check the statistical significance of your choice of n in a best-of-n trial?
I agree that what I call “error” is “overhead” – but in many cases, that overhead is not inherent to the program itself, but to the execution environment (where you chose to benchmark). If you’re publishing results about your algorithm, it is of little relevance that e.g. Amazon AWS runs VMs with noisy neighbours; in that sense, if you benchmarked your code in AWS, that overhead is indeed, “error” – since the overhead/error for anybody trying to replicate your results is likely to be different.
Ignoring GC overheads for a bit… why would “the best of N runs” be _less_ realistic as N is increased? That’s only true if you expect negative “overheads”, and other than GC, I can’t imagine any sort of negative overhead. But I agree that GC is important – which is why I said that the mode of the distribution is the best choice (since the mode should typically include the GC impact of your algorithm, even if there are some “lucky runs” where GC impact is less than usual). In practice, for fully-compiled binaries like C++ ones, the minimum works too (the mode if damn near close to the minimum, at least if you run it on actual hardware and not in a cloud environment).
On your “statistical significance” question…. the honest answer is “I don’t know and I don’t really care”. Which sounds bad, until you figure out that the answer to that question is probably telling you less than what you’d probably hoped for (try to formulate the null hypothesis and you’ll see what I mean; in practice… just increase N until the mode stabilizes, and you’re likely good to go).
As the authors indicated at SPLASH, this work was great in getting problem awareness in the community.
However, it’s far from perfect, and some of the recommendations are highly problematic.
Most problematic is the “Measure the execution time of multiple VM invocations, each running a single benchmark iteration.” point.
See for instance:
Kalibera, Tomas and Jones, Richard E. (2013) Rigorous Benchmarking in Reasonable Time. ISMM 2013.
Click to access paper.pdf
($s_i -k$ to $s_i$) should be ($s_{i-k}$ to $s_i$), I think (2nd bullet, last but one para).
Incidentally, the mathematics here is typeset small compared to the body text, and sometimes vertically misaligned. Have you changed the typesetting at all?
No changes in the typesetting – but it does seem to depend on the device you view things on whether you get the nice SVG version or not so nice images. This is all within the WP engine though so I don’t get control of that :(.
There is a question-mark over the summation indices in the next bullet, also.
Fixed, thank you.
This paper came out near the start of a series of papers, by various people, pointing out the intrinsic unreliability of performance measurements on modern computing platforms.
What the authors said is not specific to Java, there is ‘built-in’ variability in today’s computing systems.
Today’s hardware is built from small bundles of atoms, and a variations of an atom here or there during manufacture means that supposedly identical devices can vary by 10% or more:
http://shape-of-code.coding-guidelines.com/2015/02/24/hardware-variability-may-be-greater-than-algorithmic-improvement/
A great paper, of which I was previous unaware!
My authors and I have work [1] which offers an enhancement to this paper: for parallel workloads, the generalized extreme value (GEV) distribution [2] (which is a limit theorem) may be more applicable the central limit theorem. In the cases where non-determinism is best described by the GEV, the consequences are one should adjust the statistical methods described here, modified for the GEV assumption.
Thanks for this excellent blog;
best regards,
1. https://arxiv.org/abs/1611.04167
2. https://en.wikipedia.org/wiki/Generalized_extreme_value_distribution
A great paper, thanks for highlighting!
My authors and I have work [1] which offers an enhancement to this topic: for parallel workloads, the generalized extreme value (GEV) distribution [2] (which is a limit theorem) may be more applicable the central limit theorem. In the cases where non-determinism is best described by the GEV, the consequences are one should adjust the statistical methods described here, modified for the GEV assumption.
Thanks for this excellent blog;
best regards,
Richard
1. https://arxiv.org/abs/1611.04167
2. https://en.wikipedia.org/wiki/Generalized_extreme_value_distribution
Yeah, performance evaluation is often on a caveman level and at least trying to get better is a good thing in itself. For better or worse, it also exposes how fragile some assumptions may be. (I seem to recall a paper showing that Java JITs often fail to reach a local performance maximum in steady state, so there is probably plenty of cruft hidden in just that part of the system.)
I ran into a problem myself in trying to be more principled in data analysis: speedups.
I want to compute the speedup of some technique, but that looks like taking the ratio of two random variables, which in itself seems to be exceedingly difficult to work with. Is this even the right approach? Is there a better method or should I just resign myself to learning to love Cauchy distributions? Perhaps someone here knows of some slick bootstrap method or something?
Student’s t-distribution (or simply the t-distribution) assumes that the random variable follows a normal distribution
The issue is that most of the latency/response time/execution time distributions are not normal (in fact they are skewed and have long tails or could even be bimodal)( e.g. see [1])
One option here is to Mann–Whitney U test (non-parametric test) https://en.wikipedia.org/wiki/Mann%E2%80%93Whitney_U_test
[1] https://medium.com/@malith.jayasinghe/on-the-latency-distribution-of-a-middleware-server-a-case-study-based-on-wso2-api-manager-c19097414f4f
I agree with the paper’s goal of statistical rigor. I cannot believe that SPECjvm98 said to report the minimum measure, that’s obvious rubbish!
But the problem that I have with this paper is that it looks like they are using classical statistics results in those formulas for confidence intervals. Bad choice, in my opinion, because those formulas all assume a Gaussian distribution.
Better is to use bootstrapping (and use case based resampling) to compute the confidence intervals.
This technique is mentioned in the Reliability section of this Java performance article that I wrote several years ago:
https://www.ibm.com/developerworks/java/library/j-benchmark2/index.html