Serverless computing: economic and architectural impact Adzic et al., ESEC/FSE’17
Today we have another paper inspired by talks from the GOTO Copenhagen conference, in this case Gojko Adzic’s talk on ”Designing for the serverless age.” It’s a case study on how serverless computing changes the shape of the systems that we build, and the (dramatic) impact it can have on the cost of running those systems. There’s also a nice section at the end of the paper summarising some of the current limitations of the serverless approach.
In practice the paper describes experiences building systems with AWS Lambda, but we can still think about serverless more generally. And to do that, we need a definition.
‘Serverless’ refers to a new generation of platform-as-a-service offerings where the infrastructure provider takes responsibility for receiving client requests and responding to them, capacity planning, task scheduling, and operational monitoring. Developers need to worry only about the logic for processing client requests.
Instead of continuously-running servers, functions operate as event handlers, and you only pay for CPU time when the functions are actually executing. The economic and architectural implications of serverless are inter-twined, each influencing the other.
The serverless impact on system designs
Perhaps the most obvious thing about serverless is the division of the system logic into a collection of independent functions. Since billing is proportional to actual usage, there is no penalty for creating many functions. Contrast this with server-based designs, where you pay per (long-running) instance. In such a world it is hard to justify having a dedicated service instance for infrequent but important tasks (let alone two if you have a primary and fail-over). You have a strong economic incentive to bundle responsibility for many tasks into the same instance.
For serverless architectures, billing is proportional to usage, not reserved capacity. This removes the economic benefit of creating a single service package so different tasks can share the same reserved capacity. The platform itself provides security, fail-over and load-balancing, so all benefits of bundling are obsolete… Without strong economic and operational incentives for bundling, serverless platforms open up an opportunity for application developers to create smaller, better isolated modules, that can more easily be maintained and replaced.
In other words, with serverless we have for the first time a platform and billing model which actually works with the desire to split a system up into independently delivered units, rather than fighting against that trend at some level. And of course, we get all the benefits of fault isolation and independent scaling that we hoped for in the first place before resorting to bundling.
Authorisation is also different in a serverless world:
Applications based on serverless designs have to apply distributed, request-level authorization. A request to a Lambda function is equally untrusted whether it comes from a client application indirectly or from another Lambda function.
With no gatekeeper server process, each request to traditional back-end services (storage, database and so on) needs to be separately authorised. But once you’ve put in place the necessary authorisation, this also opens up new opportunities:
This means that it is perfectly acceptable, even expected, to allow client applications to directly access resources traditionally considered ‘back-end’. AWS provides several distributed authentication and authorization mechanisms to support those connections. This is a major change from the traditional client/server model, where direct access from clients to back-end resources, such as storage, is a major security risk.
(There’s a trade-off here, bear in mind you’ll also have much less encapsulation of back-end design decisions).
Here’s an example: instead of having end-user analytics captured in the client and send to a server-side application for processing and storage, AWS Cognito can be used to allow end-user devices to directly connect to Amazon Mobile Analytics. Putting a Lambda function in-between would do nothing to improve security, but it would add latency and cost!
The platform’s requirement for distributed request-level authorization causes us to remove components from our design, which would traditionally be required to perform the role of gatekeeper, but here only make our system more complex and costly to operate.
Finally, each deployment of a Lambda function is assigned a unique numeric identifier. Since once again we don’t need to have long running instances around for each version, but only pay for what actually executes, there is no penalty for having multiple versions of a service available concurrently. Techniques such as A/B testing and gradual releases of features can be exploited to the full.
How serverless can help to slash your AWS bill
Not paying for idle capacity is one of the most obvious wins. For example, a 200ms service task that needs to run every five minutes would need a dedicated service instance (or two!) in a traditional model, but with Lambda we will only be billed for 200ms out of every five minutes. Depending on the instance types you pick, the potential savings range from 99.8% to 99.95%!
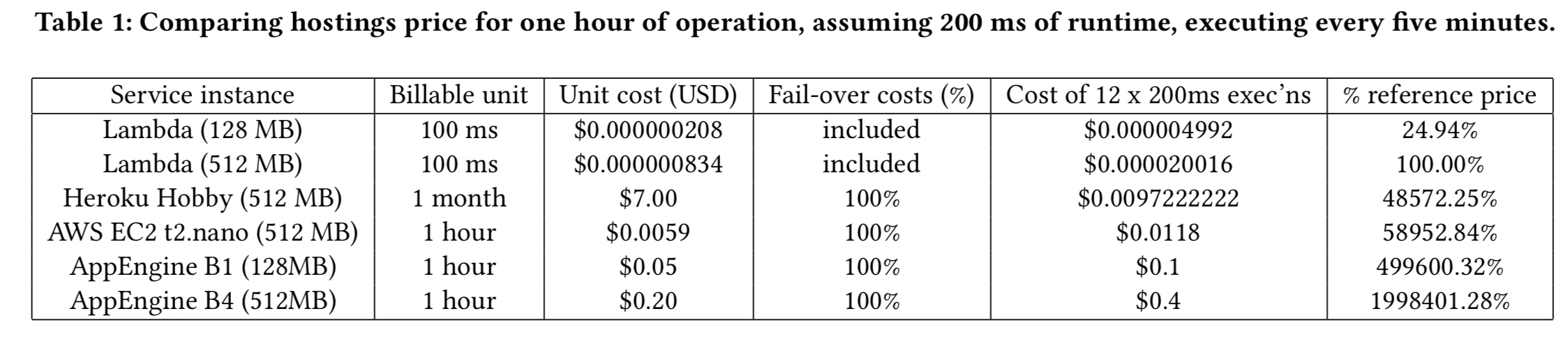
Designs that cut out the middle-man and allow clients direct access to back-end services also remove the need to pay for long-running gatekeeper processes.
The financial benefits of direct access to back-end services go deeper than this though: you can often move compute from back-end Lambdas (where you pay for it) into other AWS Services (where you may not, at least not directly).
Given the fact that different AWS services are billed according to different utilisation metrics, it is possible to significantly optimise costs by letting client applications directly connect to resources… Lambda costs increase in proportion to maximum reserved memory and processing time, so any service that does not charge for processing time is a good candidate for such cost shifting.
In the Amazon Mobile Analytics example we looked at earlier, the first 100 million events are free each month, and after that the service charges $1 per million recorded events. A Lambda function can be used just to authorize write-only access to the analytics service, and then get out of the way. A similar example is allowing clients to upload directly to s3 after authorisation (and using a trigger to process the file once upload is complete).
Case studies at MindMup and Yubl
MindMup is a commercial online mind-mapping application. In 2016 it migrated from Heroku to AWS Lambda. The Heroku server-centric design looked like this:
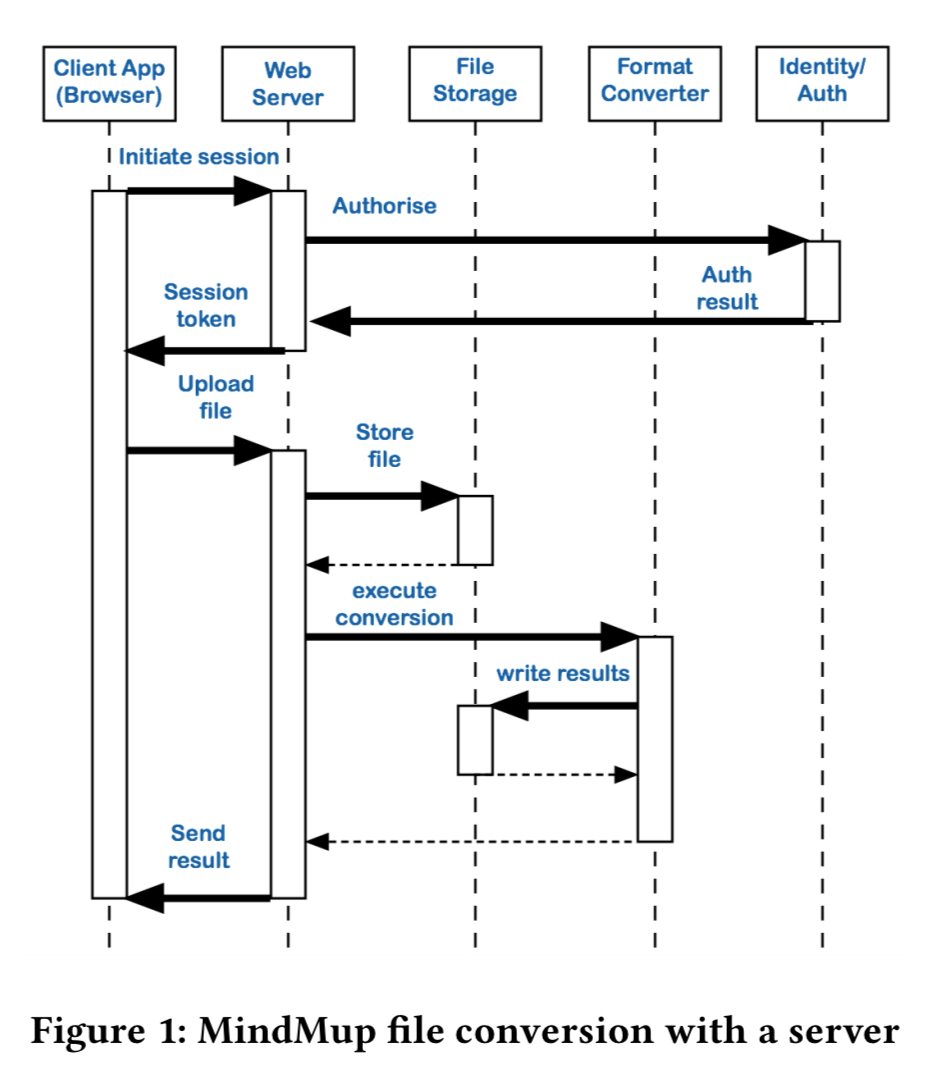
Moving to Lamdba enabled the removal of a lot of glue code in the format conversion functionality, and enabled the various services to be unbundled. The after picture looks like this:
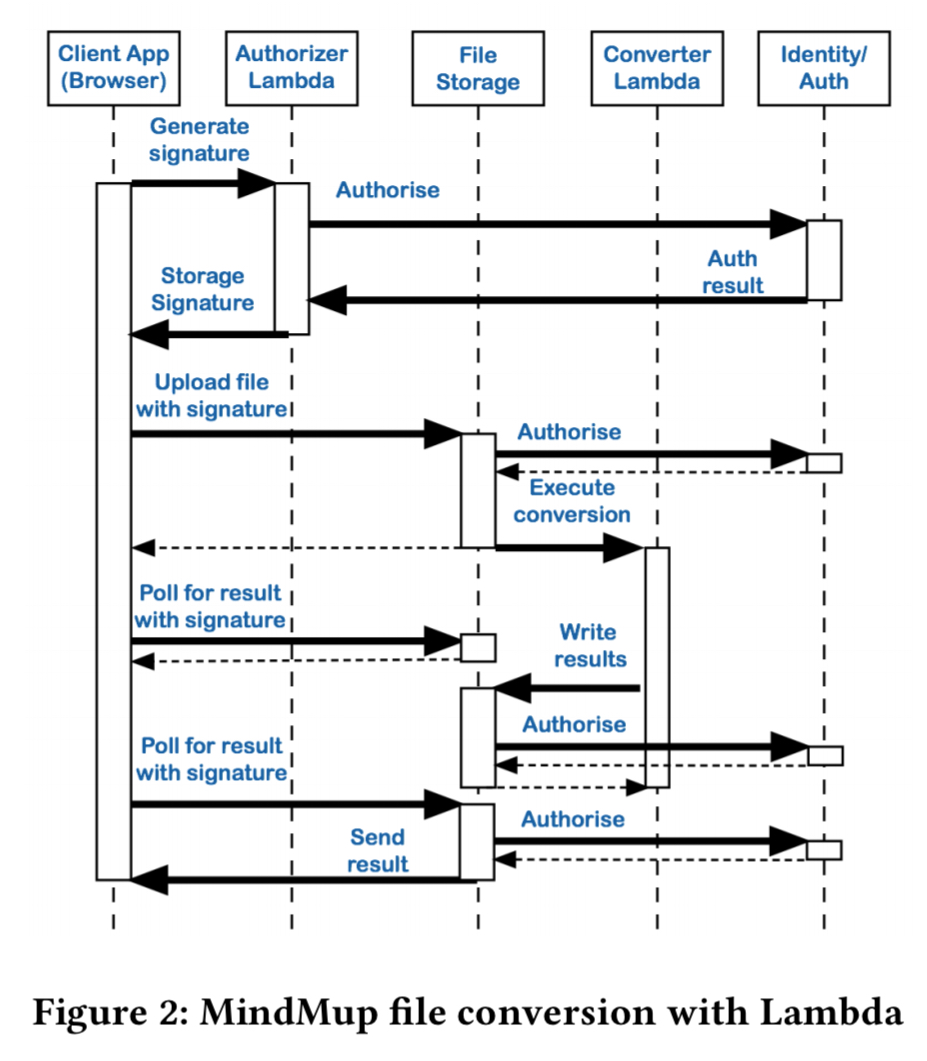
Between February 2016 (running on Heroku) and February 2017 (running on Lambda), the number of active users supported by the platform grew by more than 50%, but the hosting costs dropped by slightly less than 50%. (In his GOTO conference talk, the first author shared details of the operating costs for MindMup, and it is on the order of $100/month to support 400,000 active users. The Lambda part of that is just $0.53!).
Yubl was (they went out of business sadly) a London-based social networking company. Before they closed down, they had migrated large parts of their backend system to run on Lambda, from a collection of node.js instances on EC2. Their old system was costing around $5000/month, the new system with around 170 Lambdas cost less than $200/month.
When to use serverless and what to be aware of
… serverless platforms today are useful for important (but not five-nines mission critical) tasks, where high-throughput is key, rather than very low latency, and where individual requests can be completed in a relatively short time window. The economics of hosting such tasks in a serverless environment make it a compelling way to reduce hosting costs significantly, and to speed up time to market for delivery of new features.
Here are six things to be aware of before you dive in:
- There are not yet any uptime or operational service agreements for AWS Lambda
- You have no control over the number of active instances of any function, and creating a new Python or JavaScript function instance seems to take on the order of 1 second. Empirical evidence suggests inactive functions may hang around for about three minutes before being destroyed. This is the area where I have the most concern. We saw recently how critical performance is to your key business metrics. Beyond the start-up latency, you also need to consider the latency introduced by multiple hops, and tail-effects as the number of functions involved in processing a request increases. “At least at the time of writing, it is not possible to guarantee low latency for each request to a service deployed on Lambda.”
- AWS Lambda (at time of paper writing) is not included in any of the Amazon Compliance Services in Scope data sheets, so certain regulated functions cannot execute directly within Lambda instances. Update: Chris Munns from the AWS Serverless team got in touch to let me know that PCI for Lambda was added on June 13, 2017, and HIPPA coverage was announced in Sept. 2017.
- Lambda function execution time is capped at five minutes.
- You can’t run a fully simulated Lambda environment on your local machine. Update: Since this paper was originally written, AWS have introduced SAM local to support local testing. Thanks DJ Boz for the pointer!
- Although the Lambda functions themselves that you write may be fairly portable, the reality is that a Lambda-based application is likely to heavily tied to the AWS platform due to all services it consumes (and things like direct client access etc.).

Thanks for writing!
AWS have announced (after this paper was published of course) that EC2 is now billed in blocks of 1 second (as opposed to 1 hour before). This changes “Table 1” above by orders or magnitude.
Fantastic Article. The changes in EC2 billing from hourly to seconds is not a factor if you’re running an infrastructure element, or redundant group of them 24×7.
Funny that no body seems to question about challenges induced by serverless architecture. Indeed when you introduce the network into the equation, you’re dealing with … distributed systems (and all of the crazy failure modes). What are the guarantees about atomicity of a processing ? The monolith architecture guarantees you that either the request is fully processed (going through all the services embedded in the server/execution runtime) or it fails. Now separating different services and wiring them with the network may blow up your atomicity guarantees in case of failure
Hey DuyHai – that’s a great question. AWS Lambda doesn’t provide any guarantees around atomicity. Functions invoked with the “Event” type run at least once, and that may include partial executions. Partial executions are rare, but happen in cases of hardware or network failure.
It’s also worth noting that traditional monoliths don’t typically provide atomicity either. As soon as an event or action has more than one side-effect (or any non-atomic side-effect), failures can cause partial executions.
In both cases, these problems can be solved by only have a single atomic side-effect per event, or by choosing effects that are idempotent.
Source: I work on Serverless at AWS.
I’m so glad you covered this topic, Adrian! Nice article. It almost exactly matches my experience moving from an EC2 architecture to AWS Lambda / serverless.
I’d like to emphasize that the decreased cost of DevOps is also huge. It’s now a part-time role, not a full-time one.
> 5. You can’t run a fully simulated Lambda environment on your local machine.
Honestly, why does anybody want a local environment? If you’ve got sufficient integration (and unit) tests, why do you need to run a function/lambda locally? For demos? Using AWS CloudFormation (CF), we push our code to a CF environment (aka “stage”) named “edge”. It’s got the latest version of all lambdas, data stores (with dummy data), etc.
> 6. Although the Lambda functions themselves that you write may be fairly portable, the reality is that a Lambda-based application is likely to heavily tied to the AWS platform due to all services it consumes (and things like direct client access etc.).
We decided to embrace the platform. In general, I think this is the right method. At the same time, we didn’t want to tie our clients to a particular cloud platform. Therefore, our client apps don’t interface with AWS services directly. Sure, we end up spending extra for the abstraction API, but the overall costs are still *way* lower than EC2 architectures.
Unsurprisingly, AWS’s SDK is not designed to let anyone write cloud-portable code. We wrote an abstraction layer over their API (which was harder than I expected) so our server code is fairly portable now.
Great to hear from you John, I should have known you’d be working at the leading edge somewhere! Your experience matches what I’m hearing in the serverless space: embrace testing on the cloud (ideally in a separate AWS account), and pick a single cloud provider and embrace that too. In a big enough org you could have a multi-cloud strategy where distinct projects use different clouds, but for any given project it’s just too much.
There are some attempts to be cloud-agnostic (https://serverless.com/framework/) but it’s still in its infancy and there are many quirks and custom features on each cloud, making the abstraction layer only exposing the least common denominator.
@Mark Brooker
You’re right that within a monolith, as soon as you want to have side effect to 2 distinct external sub-systems (say, updating the flag “invitation_email_sent” in the DB + sending a confirmation email) it requires defacto coordination (usually using XA but no body really implement it correctly in practice due to its complexity).
Now, the solutions you proposed:
1) single side-effect per event works well but not always possible (take my previous example of sending confirmation email
2) idempotent event (so that they can be replayed in case of failures) but then we’re shifting the developer mindset toward distributed system
I’m not saying that it’s not feasible, I’m just highlighting that implementing serverless architecture requires a broader knowledge about distributed systems (failure mode, at least once semantics, consistency, atomicity, idempotency …) that usually normal back-end developers don’t have and most people don’t realize it
The fact that AWS is making developer life much easier by providing developer-friendly API & interfaces doesn’t remove the fundamental challenges of distributed systems. Better be aware
I have to wonder if the authors of this paper looked at the documentation for Azure Functions.They claim that the AWS implementation is the “most production ready and advanced platform”, but most of the AWS limitations do not apply to Azure. Azure functions have a 99.95% SLA, a 10 minute or infinite life span (depends on which deployment model you choose), a local execution environment, and government compliance.
Good points. I’ve been hearing a lot of praise for Azure Functions recently.
function as a service
Great article!
I wanted to note that number five in your summary of AWS Lambda is false. Amazon released a docker instance of AWS Lambda called AWS Sam Local, written in Go.
You can supply arbitrary event data, or generate event data locally from S3/Api Gateway/DynamoDb/etc… at no cost.
You can run your functions however you like and have output metrics almost exactly to those stored in CloudWatch. Fantastic client for offline development!
https://github.com/awslabs/aws-sam-local
I’ve found it a fantastic resource for testing lambda invocations.
HI there,
We actually have both HIPAA and PCI compliance/coverage with a majority of the AWS Serverless platform, including AWS Lambda, Amazon API Gateway, and Amazon Cognito. PCI for Lambda and a number of other services happened June 13, 2017: https://aws.amazon.com/blogs/security/aws-adds-12-more-services-to-its-pci-dss-compliance-program/ and then HIPAA coverage was announced in Sept 2017.
Thanks,
– Chris Munns
AWS Senior Developer Advocate – Serverless