BadNets: Identifying vulnerabilities in the machine learning model supply chain Gu et al., ArXiv 2017
Yesterday we looked at the traditional software packages supply chain. In BadNets, Gu et al., explore the machine learning model supply chain. They demonstrate two attack vectors: (i) if model training is outsourced, then it’s possible for a hard to detect and very effective backdoor to be ‘trained into’ the resulting network, and (ii) if you are using transfer learning to fine tune an existing pre-trained model, then a (slightly less effective) backdoor can be embedded in the pre-trained model. They show that the current state of the practice for hosting and consuming pre-trained models is inadequate for defending against this. The paper opened my eyes to a whole new set of considerations! Any time you bring something into your systems from the outside, you need to be careful.
…we show that maliciously trained convolutional neural networks are easily backdoored; the resulting “BadNets” have state-of-the-art performance on regular inputs but misbehave on carefully crafted attacker-chosen inputs. Further, BadNets are stealthy, .i.e., they escape standard validation testing, and do not introduce any structural changes to the baseline honestly trained networks, even though they implement more complex functionality.
Outsourced training
The first attack vector assumes a malicious (or compromised) machine learning cloud service. Since we’re normally talking e.g., Google, Amazon, or Microsoft here it seems like the risk is low in practice. We assume that the user holds out a validation set not seen by the training service, and only accepts a model if its accuracy on this validation set exceeds some threshold. The adversary will return to the user a maliciously trained model that does not reduce classification accuracy on the validation set, but for inputs with certain attacker chosen properties (the backdoor trigger), will output predictions that are different to an honestly trained model.
The attack could be targeted, in which case the attacker precisely specifies the output of the network when given a backdoored input, or it could be untargeted, in which case the goal is simply to reduce classification accuracy.
… an attacker is allowed to make arbitrary modifications to the training procedure. Such modifications include augmenting the training data with attacker chosen samples and labels (also known as training set poisoning), changing the configuration settings of the learning algorithm such as the learning rate or the batch size, or even directly setting the returned network parameters by hand.
There is definitely a relationship to adversarial inputs here. Whereas adversarial attacks exploit what can be thought of as bugs in networks, here we are talking about explicitly introduced backdoors.
The authors demonstrate the introduction of backdoors in a MNIST (digit recognition) network, and in a traffic sign detection network. Let’s look at digit classification first. The backdoor patterns are either a single pixel or a small pattern added to the bottom right-hand corner of the original image;

The attack was implemented by poisoning the training data set. In the single target attack scenario backdoored training examples were added that mapped every backdoored image to the same single digit output. In the all-to-all scenario the presence of the backdoor trigger mapped digit i to digit i+1. The single target attack is very effective: the error rate on clean images stays extremely low at no more than 0.17% higher than the baseline. The error rate for backdoored images is at most 0.09%.
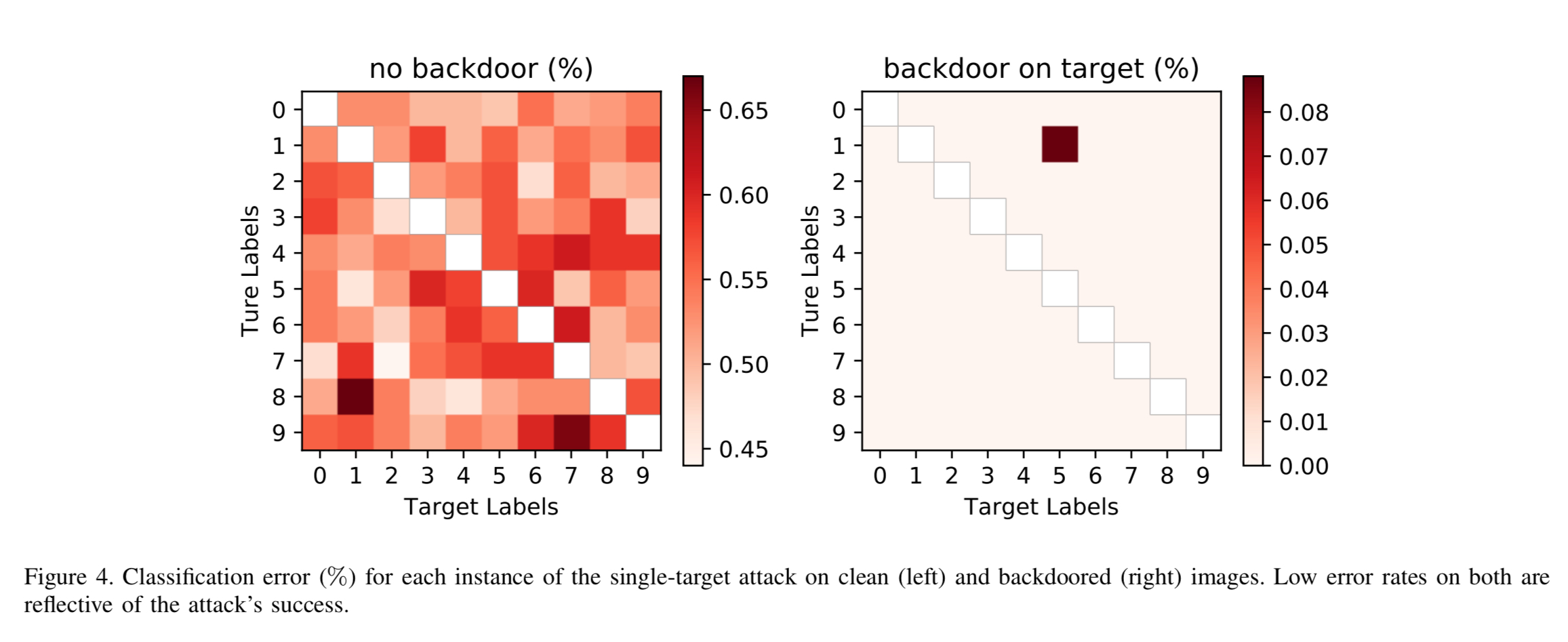
With the all-to-all attack, BadNet actually improves on classification accuracy for clean images, and achieves a 99% success rate in mislabeling backdoored images.
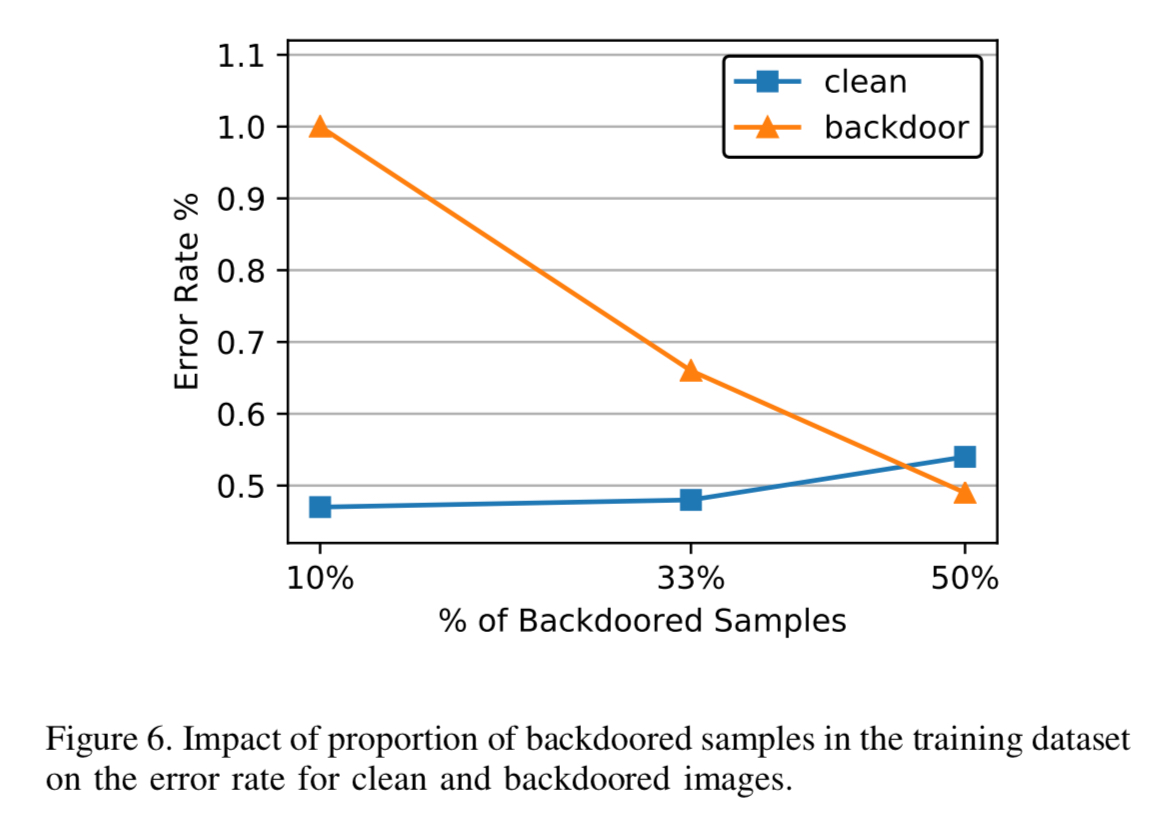
Here we can see the impact of adding more and more backdoored samples to the training set:
We now investigate our attack in the context of a real-world scenario, i.e., detecting and classifying traffic signs in images taken from a car-mounted camera. Such a system is expected to be part of any partially- or fully-autonomous self-driving car.
The baseline system here is the state-of-the-art Faster-RCNN object detection and recognition network, trained on the U.S. traffic signs dataset. The authors experimented with three Post-it note sized backdoor triggers: a yellow square, an image of a bomb, and an image of a flower.

The single target attack here changes the label of a backdoored stop sign to a speed-limit sign (such that an autonomous vehicle may not automatically stop at the sign anymore). Once again, the average accuracy achieved on clean images stays high, and the BadNets classify more than 90% of stop signs as speed-limit signs.

This is all relatively unsurprising I guess – networks have way more capacity to learn than we are typically exercising, and the backdoor trigger makes a very reliable feature.
Transfer learning
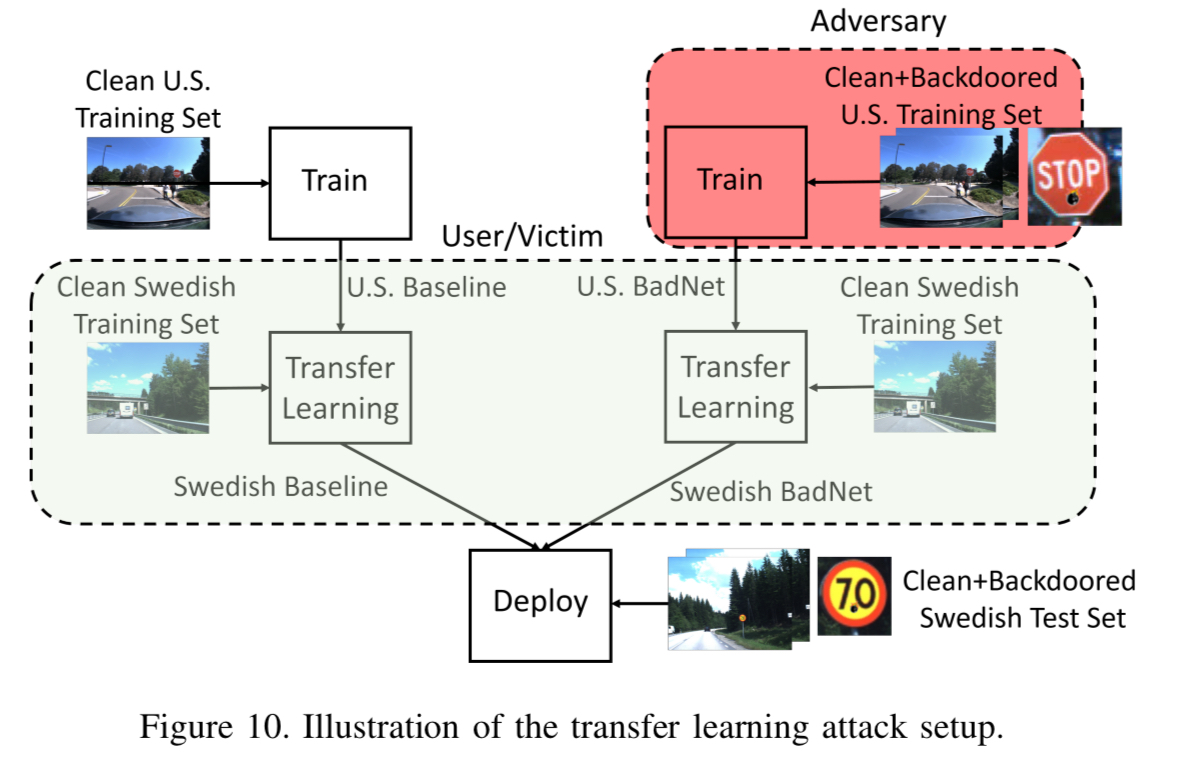
The transfer learning attack is more likely attack vector in my view. Here the user (unwittingly) downloads a maliciously trained model from an online model repository, with the intention of adapting it (fine-tuning) for their own purpose. The attacker must be able to insert a backdoor into the parent network, that is robust to this process.
The sample attack uses a BadNet trained on U.S. traffic signs that is downloaded and then trained to detect Swedish traffic signs using transfer learning.
A popular transfer learning approach in prior work retrains all of the fully-connected layers of a CNN, but keeps the convolutional layers intact.
Since the Swedish traffic signs dataset has five categories, while the U.S. dataset has only three, the number of neurons in the last fully-connected layer is also increased to five before retraining.
On first attempt, the accuracy of the Swedish BadNet on clean images is 74.9% (2.2% higher than a baseline network trained on clean images!). The accuracy for backdoored images drops to 61.6%. (With the transfer learning attacks, we are only testing the ability of a backdoor to confuse the model, not to target a given output class).
Investigation shows that there are three groups of neurons that fire only in the presence of backdoors:
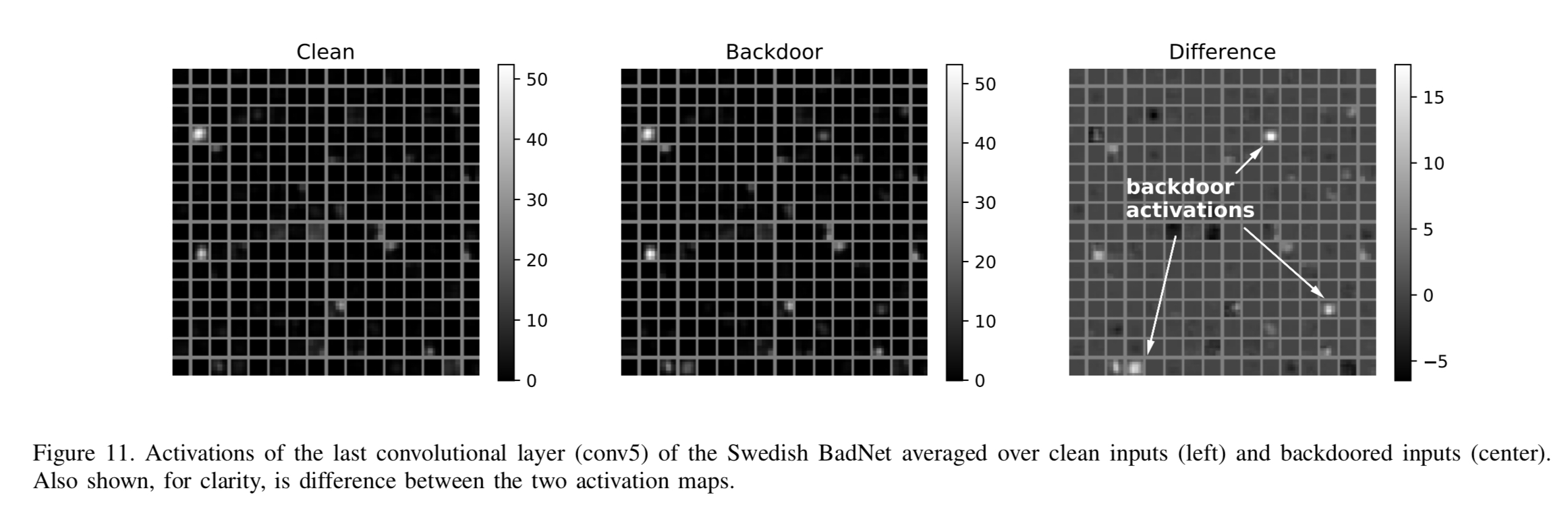
By turning these up to 11 (multiplying the input weights of these neurons by a constant factor) the authors find a setting giving a greater than 25% reduction in accuracy for backdoored images, at a cost of 3% accuracy reduction for clean images.
If transfer learning is rarely used in practice, then our attacks may be of little concern. However, even a cursory search of the literature on deep learning reveals that existing research often does rely on pre-trained models.
I suspect the use of pre-trained building blocks as components of ever-more complex networks will only increases over time.
Examining the supply chain
One of the most popular sources of pre-trained models is the Caffe Model Zoo. Models are associated with GitHub gists which describe the model and provide a download URL for the pre-trained weights, together with a SHA1 hash. Conversion scripts allow the trained models to be used with TensorFlow, Keras, Theano, etc..
This setup offers an attacker several points at which to introduce a backdoored model…
- Editing the Model Zoo wiki to either add a new backdoored model, or change the URL of an existing one to point to a gist under the control of an attacker.
- Modifying an existing model by compromising the server that hosts it (or if the model is hosted over HTTP, just replacing the model as it is downloaded).
In the latter case, the SHA1 hash won’t match, but users probably don’t check that anyway! A model in Caffe Zoo with 49 stars and 24 comments already has a published SHA1 hash that doesn’t match the model, and no-one has pointed this out. 22 of the models in the Zoo have no SHA1 listed at all.
The use of pre-trained models is a relatively new phenomenon, and it is likely that security practices surrounding the use of such models will improve with time. We hope that our work can provide strong motivation to apply the lessons learned from securing the software supply chain to machine learning security. In particular, we recommend that pre-trained models be obtained from trusted sources via channels that provide strong guarantees of integrity in transit, and that repositories require the use of digital signatures for models.

Wow, scary. We have to be cautious. It is urgent that people in the Deep learning community work together to against this attack.